 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapley-Guided Neural Repair Approach via Derivative-Free Optimization
Apr 01, 2026DNNs are susceptible to defects like backdoors, adversarial attacks, and unfairness, undermining their reliability. Existing approaches mainly involve retraining, optimization, constraint-solving, or search algorithms. However, most methods rely on gradient calculations, restricting applicability to specific activation functions (e.g., ReLU), or use search algorithms with uninterpretable localization and repair. Furthermore, they often lack generalizability across multiple properties. We propose SHARPEN, integrating interpretable fault localization with a derivative-free optimization strategy. First, SHARPEN introduces a Deep SHAP-based localization strategy quantifying each layer's and neuron's marginal contribution to erroneous outputs. Specifically, a hierarchical coarse-to-fine approach reranks layers by aggregated impact, then locates faulty neurons/filters by analyzing activation divergences between property-violating and benign states. Subsequently, SHARPEN incorporates CMA-ES to repair identified neurons. CMA-ES leverages a covariance matrix to capture variable dependencies, enabling gradient-free search and coordinated adjustments across coupled neurons. By combining interpretable localization with evolutionary optimization, SHARPEN enables derivative-free repair across architectures, being less sensitive to gradient anomalies and hyperparameters. We demonstrate SHARPEN's effectiveness on three repair tasks. Balancing property repair and accuracy preservation, it outperforms baselines in backdoor removal (+10.56%), adversarial mitigation (+5.78%), and unfairness repair (+11.82%). Notably, SHARPEN handles diverse tasks, and its modular design is plug-and-play with different derivative-free optimizers, highlighting its flexibility.
Coding in a Bubble? Evaluating LLMs in Resolving Context Adaptation Bugs During Code Adaptation
Jan 10, 2026Code adaptation is a fundamental but challenging task in software development, requiring developers to modify existing code for new contexts. A key challenge is to resolve Context Adaptation Bugs (CtxBugs), which occurs when code correct in its original context violates constraints in the target environment. Unlike isolated bugs, CtxBugs cannot be resolved through local fixes and require cross-context reasoning to identify semantic mismatches. Overlooking them may lead to critical failures in adaptation. Although Large Language Models (LLMs) show great potential in automating code-related tasks, their ability to resolve CtxBugs remains a significant and unexplored obstacle to their practical use in code adaptation. To bridge this gap, we propose CtxBugGen, a novel framework for generating CtxBugs to evaluate LLMs. Its core idea is to leverage LLMs' tendency to generate plausible but context-free code when contextual constraints are absent. The framework generates CtxBugs through a four-step process to ensure their relevance and validity: (1) Adaptation Task Selection, (2) Task-specific Perturbation,(3) LLM-based Variant Generation and (4) CtxBugs Identification. Based on the benchmark constructed by CtxBugGen, we conduct an empirical study with four state-of-the-art LLMs. Our results reveal their unsatisfactory performance in CtxBug resolution. The best performing LLM, Kimi-K2, achieves 55.93% on Pass@1 and resolves just 52.47% of CtxBugs. The presence of CtxBugs degrades LLMs' adaptation performance by up to 30%. Failure analysis indicates that LLMs often overlook CtxBugs and replicate them in their outputs. Our study highlights a critical weakness in LLMs' cross-context reasoning and emphasize the need for new methods to enhance their context awareness for reliable code adaptation.
AdaptEval: A Benchmark for Evaluating Large Language Models on Code Snippet Adaptation
Jan 08, 2026Recent advancements in large language models (LLMs) have automated various software engineering tasks, with benchmarks emerging to evaluate their capabilities. However, for adaptation, a critical activity during code reuse, there is no benchmark to assess LLMs' performance, leaving their practical utility in this area unclear. To fill this gap, we propose AdaptEval, a benchmark designed to evaluate LLMs on code snippet adaptation. Unlike existing benchmarks, AdaptEval incorporates the following three distinctive features: First, Practical Context. Tasks in AdaptEval are derived from developers' practices, preserving rich contextual information from Stack Overflow and GitHub communities. Second, Multi-granularity Annotation. Each task is annotated with requirements at both task and adaptation levels, supporting the evaluation of LLMs across diverse adaptation scenarios. Third, Fine-grained Evaluation. AdaptEval includes a two-tier testing framework combining adaptation-level and function-level tests, which enables evaluating LLMs' performance across various individual adaptations. Based on AdaptEval, we conduct the first empirical study to evaluate six instruction-tuned LLMs and especially three reasoning LLMs on code snippet adaptation. Experimental results demonstrate that AdaptEval enables the assessment of LLMs' adaptation capabilities from various perspectives. It also provides critical insights into their current limitations, particularly their struggle to follow explicit instructions. We hope AdaptEval can facilitate further investigation and enhancement of LLMs' capabilities in code snippet adaptation, supporting their real-world applications.
Fairness Is Not Just Ethical: Performance Trade-Off via Data Correlation Tuning to Mitigate Bias in ML Software
Dec 19, 2025Traditional software fairness research typically emphasizes ethical and social imperatives, neglecting that fairness fundamentally represents a core software quality issue arising directly from performance disparities across sensitive user groups. Recognizing fairness explicitly as a software quality dimension yields practical benefits beyond ethical considerations, notably improved predictive performance for unprivileged groups, enhanced out-of-distribution generalization, and increased geographic transferability in real-world deployments. Nevertheless, existing bias mitigation methods face a critical dilemma: while pre-processing methods offer broad applicability across model types, they generally fall short in effectiveness compared to post-processing techniques. To overcome this challenge, we propose Correlation Tuning (CoT), a novel pre-processing approach designed to mitigate bias by adjusting data correlations. Specifically, CoT introduces the Phi-coefficient, an intuitive correlation measure, to systematically quantify correlation between sensitive attributes and labels, and employs multi-objective optimization to address the proxy biases. Extensive evaluations demonstrate that CoT increases the true positive rate of unprivileged groups by an average of 17.5% and reduces three key bias metrics, including statistical parity difference (SPD), average odds difference (AOD), and equal opportunity difference (EOD), by more than 50% on average. CoT outperforms state-of-the-art methods by three and ten percentage points in single attribute and multiple attributes scenarios, respectively. We will publicly release our experimental results and source code to facilitate future research.
Step More: Going Beyond Single Backpropagation in Meta Learning Based Model Editing
Aug 06, 2025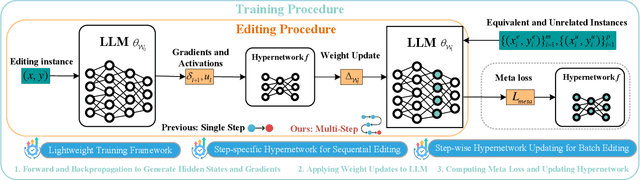
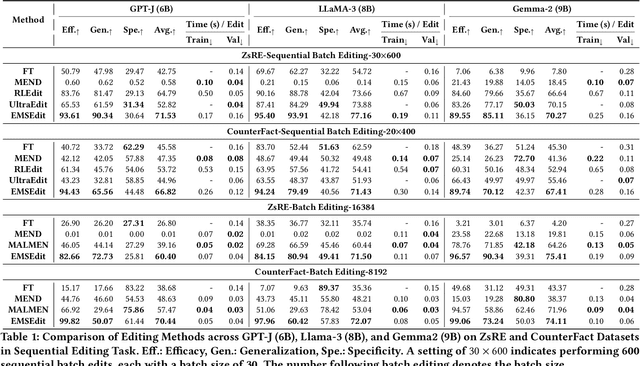
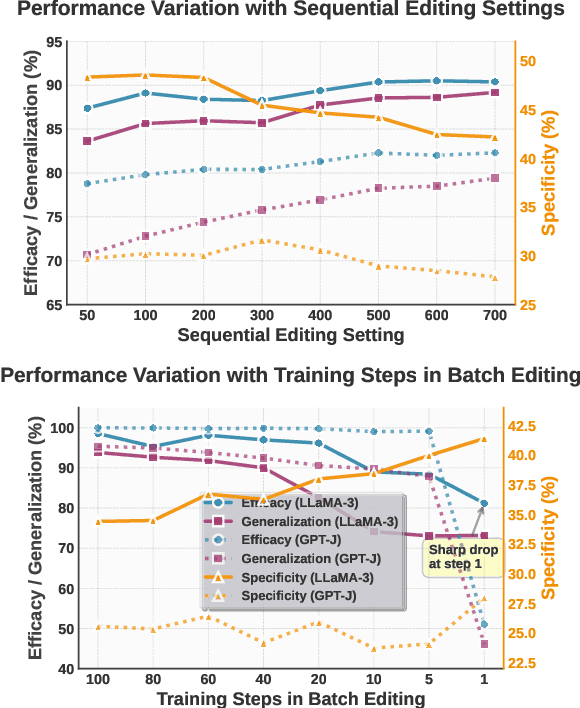
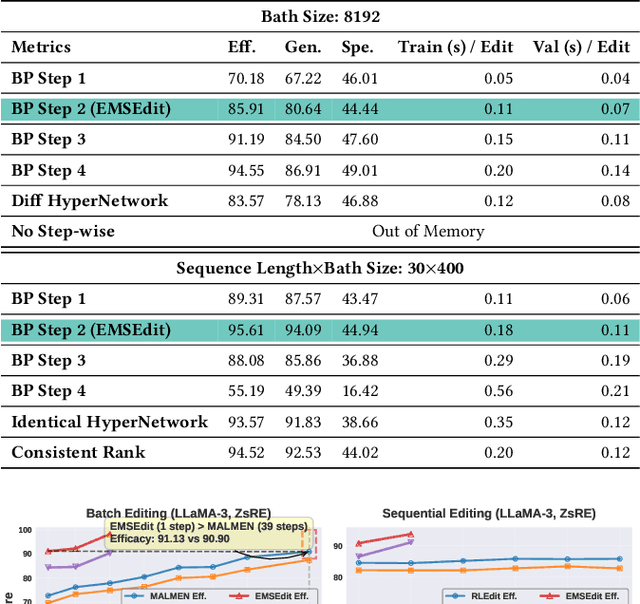
Large Language Models (LLMs) underpin many AI applications, but their static nature makes updating knowledge costly. Model editing offers an efficient alternative by injecting new information through targeted parameter modifications. In particular, meta-learning-based model editing (MLBME) methods have demonstrated notable advantages in both editing effectiveness and efficiency. Despite this, we find that MLBME exhibits suboptimal performance in low-data scenarios, and its training efficiency is bottlenecked by the computation of KL divergence. To address these, we propose $\textbf{S}$tep $\textbf{M}$ore $\textbf{Edit}$ ($\textbf{SMEdit}$), a novel MLBME method that adopts $\textbf{M}$ultiple $\textbf{B}$ackpro$\textbf{P}$agation $\textbf{S}$teps ($\textbf{MBPS}$) to improve editing performance under limited supervision and a norm regularization on weight updates to improve training efficiency. Experimental results on two datasets and two LLMs demonstrate that SMEdit outperforms prior MLBME baselines and the MBPS strategy can be seamlessly integrated into existing methods to further boost their performance. Our code will be released soon.
Large Language Models are Qualified Benchmark Builders: Rebuilding Pre-Training Datasets for Advancing Code Intelligence Tasks
Apr 28, 2025



Pre-trained code models rely heavily on high-quality pre-training data, particularly human-written reference comments that bridge code and natural language. However, these comments often become outdated as software evolves, degrading model performance. Large language models (LLMs) excel at generating high-quality code comments. We investigate whether replacing human-written comments with LLM-generated ones improves pre-training datasets. Since standard metrics cannot assess reference comment quality, we propose two novel reference-free evaluation tasks: code-comment inconsistency detection and semantic code search. Results show that LLM-generated comments are more semantically consistent with code than human-written ones, as confirmed by manual evaluation. Leveraging this finding, we rebuild the CodeSearchNet dataset with LLM-generated comments and re-pre-train CodeT5. Evaluations demonstrate that models trained on LLM-enhanced data outperform those using original human comments in code summarization, generation, and translation tasks. This work validates rebuilding pre-training datasets with LLMs to advance code intelligence, challenging the traditional reliance on human reference comments.
Mitigating Sensitive Information Leakage in LLMs4Code through Machine Unlearning
Feb 09, 2025



Large Language Models for Code (LLMs4Code) excel at code generation tasks, yielding promise to release developers from huge software development burdens. Nonetheless, these models have been shown to suffer from the significant privacy risks due to the potential leakage of sensitive information embedded during training, known as the memorization problem. Addressing this issue is crucial for ensuring privacy compliance and upholding user trust, but till now there is a dearth of dedicated studies in the literature that focus on this specific direction. Recently, machine unlearning has emerged as a promising solution by enabling models to "forget" sensitive information without full retraining, offering an efficient and scalable approach compared to traditional data cleaning methods. In this paper, we empirically evaluate the effectiveness of unlearning techniques for addressing privacy concerns in LLMs4Code.Specifically, we investigate three state-of-the-art unlearning algorithms and three well-known open-sourced LLMs4Code, on a benchmark that takes into consideration both the privacy data to be forgotten as well as the code generation capabilites of these models. Results show that it is feasible to mitigate the privacy concerns of LLMs4Code through machine unlearning while maintain their code generation capabilities at the same time. We also dissect the forms of privacy protection/leakage after unlearning and observe that there is a shift from direct leakage to indirect leakage, which underscores the need for future studies addressing this risk.
LSAQ: Layer-Specific Adaptive Quantization for Large Language Model Deployment
Dec 24, 2024



As large language models (LLMs) demonstrate exceptional performance across various domains, the deployment of these models on edge devices has emerged as a new trend. Quantization techniques, which reduce the size and memory footprint of LLMs, are effective for enabling deployment on resource-constrained edge devices. However, existing one-size-fits-all quantization methods often fail to dynamically adjust the memory consumption of LLMs based on specific hardware characteristics and usage scenarios. To address this limitation, we propose LSAQ (Layer-Specific Adaptive Quantization), a system for adaptive quantization and dynamic deployment of LLMs based on layer importance. LSAQ evaluates layer importance by constructing top-k token sets from the inputs and outputs of each layer and calculating their Jaccard coefficient. Using this evaluation, the system adaptively adjusts quantization strategies in real time according to the resource availability of edge devices, assigning different precision levels to layers of varying importance. This approach significantly reduces the storage requirements of LLMs while maintaining model performance, enabling efficient deployment across diverse hardware platforms and usage scenarios.
Instruct or Interact? Exploring and Eliciting LLMs' Capability in Code Snippet Adaptation Through Prompt Engineering
Nov 23, 2024



Code snippet adaptation is a fundamental activity in the software development process. Unlike code generation, code snippet adaptation is not a "free creation", which requires developers to tailor a given code snippet in order to fit specific requirements and the code context. Recently, large language models (LLMs) have confirmed their effectiveness in the code generation task with promising results. However, their performance on adaptation, a reuse-oriented and context-dependent code change prediction task, is still unclear. To bridge this gap, we conduct an empirical study to investigate the performance and issues of LLMs on the adaptation task. We first evaluate the adaptation performances of three popular LLMs and compare them to the code generation task. Our result indicates that their adaptation ability is weaker than generation, with a nearly 15% decrease on pass@1 and more context-related errors. By manually inspecting 200 cases, we further investigate the causes of LLMs' sub-optimal performance, which can be classified into three categories, i.e., Unclear Requirement, Requirement Misalignment and Context Misapplication. Based on the above empirical research, we propose an interactive prompting approach to eliciting LLMs' adaptation ability. Experimental result reveals that our approach greatly improve LLMs' adaptation performance. The best-performing Human-LLM interaction successfully solves 159 out of the 202 identified defects and improves the pass@1 and pass@5 by over 40% compared to the initial instruction-based prompt. Considering human efforts, we suggest multi-agent interaction as a trade-off, which can achieve comparable performance with excellent generalization ability. We deem that our approach could provide methodological assistance for autonomous code snippet reuse and adaptation with LLMs.
Model Editing for LLMs4Code: How Far are We?
Nov 11, 2024



Large Language Models for Code (LLMs4Code) have been found to exhibit outstanding performance in the software engineering domain, especially the remarkable performance in coding tasks. However, even the most advanced LLMs4Code can inevitably contain incorrect or outdated code knowledge. Due to the high cost of training LLMs4Code, it is impractical to re-train the models for fixing these problematic code knowledge. Model editing is a new technical field for effectively and efficiently correcting erroneous knowledge in LLMs, where various model editing techniques and benchmarks have been proposed recently. Despite that, a comprehensive study that thoroughly compares and analyzes the performance of the state-of-the-art model editing techniques for adapting the knowledge within LLMs4Code across various code-related tasks is notably absent. To bridge this gap, we perform the first systematic study on applying state-of-the-art model editing approaches to repair the inaccuracy of LLMs4Code. To that end, we introduce a benchmark named CLMEEval, which consists of two datasets, i.e., CoNaLa-Edit (CNLE) with 21K+ code generation samples and CodeSearchNet-Edit (CSNE) with 16K+ code summarization samples. With the help of CLMEEval, we evaluate six advanced model editing techniques on three LLMs4Code: CodeLlama (7B), CodeQwen1.5 (7B), and Stable-Code (3B). Our findings include that the external memorization-based GRACE approach achieves the best knowledge editing effectiveness and specificity (the editing does not influence untargeted knowledge), while generalization (whether the editing can generalize to other semantically-identical inputs) is a universal challenge for existing techniques. Furthermore, building on in-depth case analysis, we introduce an enhanced version of GRACE called A-GRACE, which incorporates contrastive learning to better capture the semantics of the inputs.