 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
MetaCLIP 2: A Worldwide Scaling Recipe
Jul 29, 2025
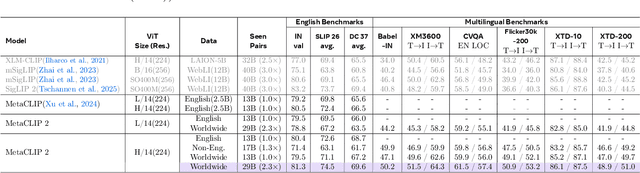


Contrastive Language-Image Pretraining (CLIP) is a popular foundation model, supporting from zero-shot classification, retrieval to encoders for multimodal large language models (MLLMs). Although CLIP is successfully trained on billion-scale image-text pairs from the English world, scaling CLIP's training further to learning from the worldwide web data is still challenging: (1) no curation method is available to handle data points from non-English world; (2) the English performance from existing multilingual CLIP is worse than its English-only counterpart, i.e., "curse of multilinguality" that is common in LLMs. Here, we present MetaCLIP 2, the first recipe training CLIP from scratch on worldwide web-scale image-text pairs. To generalize our findings, we conduct rigorous ablations with minimal changes that are necessary to address the above challenges and present a recipe enabling mutual benefits from English and non-English world data. In zero-shot ImageNet classification, MetaCLIP 2 ViT-H/14 surpasses its English-only counterpart by 0.8% and mSigLIP by 0.7%, and surprisingly sets new state-of-the-art without system-level confounding factors (e.g., translation, bespoke architecture changes) on multilingual benchmarks, such as CVQA with 57.4%, Babel-ImageNet with 50.2% and XM3600 with 64.3% on image-to-text retrieval.
GTAD: Global Temporal Aggregation Denoising Learning for 3D Semantic Occupancy Prediction
Jul 28, 2025Accurately perceiving dynamic environments is a fundamental task for autonomous driving and robotic systems. Existing methods inadequately utilize temporal information, relying mainly on local temporal interactions between adjacent frames and failing to leverage global sequence information effectively. To address this limitation, we investigate how to effectively aggregate global temporal features from temporal sequences, aiming to achieve occupancy representations that efficiently utilize global temporal information from historical observations. For this purpose, we propose a global temporal aggregation denoising network named GTAD, introducing a global temporal information aggregation framework as a new paradigm for holistic 3D scene understanding. Our method employs an in-model latent denoising network to aggregate local temporal features from the current moment and global temporal features from historical sequences. This approach enables the effective perception of both fine-grained temporal information from adjacent frames and global temporal patterns from historical observations. As a result, it provides a more coherent and comprehensive understanding of the environment. Extensive experiments on the nuScenes and Occ3D-nuScenes benchmark and ablation studies demonstrate the superiority of our method.
SessionIntentBench: A Multi-task Inter-session Intention-shift Modeling Benchmark for E-commerce Customer Behavior Understanding
Jul 27, 2025Session history is a common way of recording user interacting behaviors throughout a browsing activity with multiple products. For example, if an user clicks a product webpage and then leaves, it might because there are certain features that don't satisfy the user, which serve as an important indicator of on-the-spot user preferences. However, all prior works fail to capture and model customer intention effectively because insufficient information exploitation and only apparent information like descriptions and titles are used. There is also a lack of data and corresponding benchmark for explicitly modeling intention in E-commerce product purchase sessions. To address these issues, we introduce the concept of an intention tree and propose a dataset curation pipeline. Together, we construct a sibling multimodal benchmark, SessionIntentBench, that evaluates L(V)LMs' capability on understanding inter-session intention shift with four subtasks. With 1,952,177 intention entries, 1,132,145 session intention trajectories, and 13,003,664 available tasks mined using 10,905 sessions, we provide a scalable way to exploit the existing session data for customer intention understanding. We conduct human annotations to collect ground-truth label for a subset of collected data to form an evaluation gold set. Extensive experiments on the annotated data further confirm that current L(V)LMs fail to capture and utilize the intention across the complex session setting. Further analysis show injecting intention enhances LLMs' performances.
Reusing Attention for One-stage Lane Topology Understanding
Jul 23, 2025Understanding lane toplogy relationships accurately is critical for safe autonomous driving. However, existing two-stage methods suffer from inefficiencies due to error propagations and increased computational overheads. To address these challenges, we propose a one-stage architecture that simultaneously predicts traffic elements, lane centerlines and topology relationship, improving both the accuracy and inference speed of lane topology understanding for autonomous driving. Our key innovation lies in reusing intermediate attention resources within distinct transformer decoders. This approach effectively leverages the inherent relational knowledge within the element detection module to enable the modeling of topology relationships among traffic elements and lanes without requiring additional computationally expensive graph networks. Furthermore, we are the first to demonstrate that knowledge can be distilled from models that utilize standard definition (SD) maps to those operates without using SD maps, enabling superior performance even in the absence of SD maps. Extensive experiments on the OpenLane-V2 dataset show that our approach outperforms baseline methods in both accuracy and efficiency, achieving superior results in lane detection, traffic element identification, and topology reasoning. Our code is available at https://github.com/Yang-Li-2000/one-stage.git.
Skip a Layer or Loop it? Test-Time Depth Adaptation of Pretrained LLMs
Jul 10, 2025Can a pretrained neural network adapt its architecture to different inputs without any finetuning? Do we need all layers for simple tasks, and are they adequate for challenging tasks? We found that the layers of a pretrained large language model (LLM) can be manipulated as separate modules to build a better and even shallower model customized for each test sample. In particular, each layer from the pretrained model can be skipped/pruned or repeated multiple times as recurrent neural networks (RNN), and stacked with others in arbitrary orders, yielding a chain-of-layers (CoLa) per sample. This compositional space greatly expands the scope of existing works on looped/recurrent pretrained modules, layer pruning, or early-exit networks. We develop a Monte Carlo Tree Search (MCTS) protocol to explore and identify the optimal CoLa for each sample from math and commonsense reasoning benchmarks. Compared to a static model of a fixed depth, CoLa allows shortcut paths (fast thinking), recurrence of the same layer(s) (slow thinking), and combining both, offering more flexible, dynamic architectures for different inputs. We conduct an extensive analysis of the MCTS-optimized CoLa, which leads to two key findings: (1) For >75% of samples with correct predictions by the original LLM, we can find shorter CoLa, suggesting a large space for improving inference efficiency; (2) For >60% of samples with originally incorrect predictions, we can identify CoLa achieving correct predictions, suggesting a large space of performance enhancement. Our results highlight the shortcomings of using a fixed architecture of pre-trained LLMs for inference on different samples and pave the way to unlock the generalization power of test-time depth adaptation.
Optimal Auction Design in the Joint Advertising
Jul 10, 2025Online advertising is a vital revenue source for major internet platforms. Recently, joint advertising, which assigns a bundle of two advertisers in an ad slot instead of allocating a single advertiser, has emerged as an effective method for enhancing allocation efficiency and revenue. However, existing mechanisms for joint advertising fail to realize the optimality, as they tend to focus on individual advertisers and overlook bundle structures. This paper identifies an optimal mechanism for joint advertising in a single-slot setting. For multi-slot joint advertising, we propose \textbf{BundleNet}, a novel bundle-based neural network approach specifically designed for joint advertising. Our extensive experiments demonstrate that the mechanisms generated by \textbf{BundleNet} approximate the theoretical analysis results in the single-slot setting and achieve state-of-the-art performance in the multi-slot setting. This significantly increases platform revenue while ensuring approximate dominant strategy incentive compatibility and individual rationality.
NaturalThoughts: Selecting and Distilling Reasoning Traces for General Reasoning Tasks
Jul 02, 2025



Recent work has shown that distilling reasoning traces from a larger teacher model via supervised finetuning outperforms reinforcement learning with the smaller student model alone (Guo et al. 2025). However, there has not been a systematic study of what kind of reasoning demonstrations from the teacher are most effective in improving the student model's reasoning capabilities. In this work we curate high-quality "NaturalThoughts" by selecting reasoning traces from a strong teacher model based on a large pool of questions from NaturalReasoning (Yuan et al. 2025). We first conduct a systematic analysis of factors that affect distilling reasoning capabilities, in terms of sample efficiency and scalability for general reasoning tasks. We observe that simply scaling up data size with random sampling is a strong baseline with steady performance gains. Further, we find that selecting difficult examples that require more diverse reasoning strategies is more sample-efficient to transfer the teacher model's reasoning skills. Evaluated on both Llama and Qwen models, training with NaturalThoughts outperforms existing reasoning datasets such as OpenThoughts, LIMO, etc. on general STEM reasoning benchmarks including GPQA-Diamond, MMLU-Pro and SuperGPQA.
UAVD-Mamba: Deformable Token Fusion Vision Mamba for Multimodal UAV Detection
Jul 01, 2025Unmanned Aerial Vehicle (UAV) object detection has been widely used in traffic management, agriculture, emergency rescue, etc. However, it faces significant challenges, including occlusions, small object sizes, and irregular shapes. These challenges highlight the necessity for a robust and efficient multimodal UAV object detection method. Mamba has demonstrated considerable potential in multimodal image fusion. Leveraging this, we propose UAVD-Mamba, a multimodal UAV object detection framework based on Mamba architectures. To improve geometric adaptability, we propose the Deformable Token Mamba Block (DTMB) to generate deformable tokens by incorporating adaptive patches from deformable convolutions alongside normal patches from normal convolutions, which serve as the inputs to the Mamba Block. To optimize the multimodal feature complementarity, we design two separate DTMBs for the RGB and infrared (IR) modalities, with the outputs from both DTMBs integrated into the Mamba Block for feature extraction and into the Fusion Mamba Block for feature fusion. Additionally, to improve multiscale object detection, especially for small objects, we stack four DTMBs at different scales to produce multiscale feature representations, which are then sent to the Detection Neck for Mamba (DNM). The DNM module, inspired by the YOLO series, includes modifications to the SPPF and C3K2 of YOLOv11 to better handle the multiscale features. In particular, we employ cross-enhanced spatial attention before the DTMB and cross-channel attention after the Fusion Mamba Block to extract more discriminative features. Experimental results on the DroneVehicle dataset show that our method outperforms the baseline OAFA method by 3.6% in the mAP metric. Codes will be released at https://github.com/GreatPlum-hnu/UAVD-Mamba.git.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.