 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-agnostic Multi-scale Contrastive Text-Audio Pre-training for Parallelized TTS Frontend Modeling
Apr 14, 2024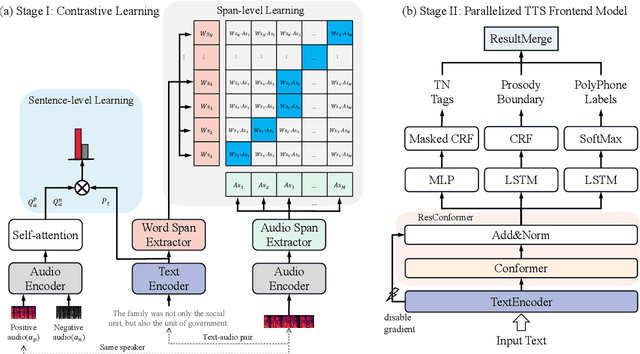
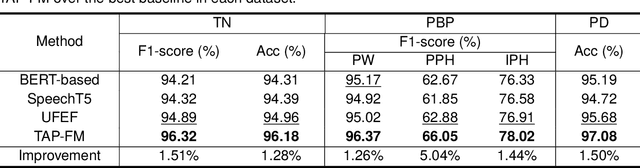

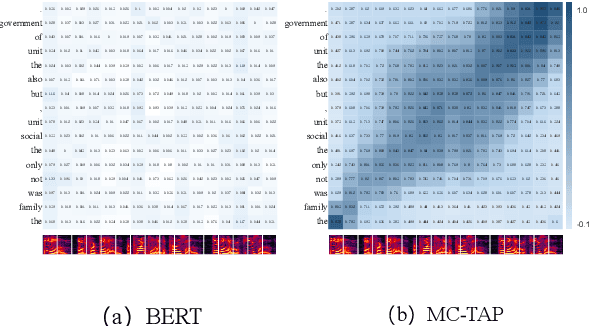
Over the past decade, a series of unflagging efforts have been dedicated to developing highly expressive and controllable text-to-speech (TTS) systems. In general, the holistic TTS comprises two interconnected components: the frontend module and the backend module. The frontend excels in capturing linguistic representations from the raw text input, while the backend module converts linguistic cues to speech. The research community has shown growing interest in the study of the frontend component, recognizing its pivotal role in text-to-speech systems, including Text Normalization (TN), Prosody Boundary Prediction (PBP), and Polyphone Disambiguation (PD). Nonetheless, the limitations posed by insufficient annotated textual data and the reliance on homogeneous text signals significantly undermine the effectiveness of its supervised learning. To evade this obstacle, a novel two-stage TTS frontend prediction pipeline, named TAP-FM, is proposed in this paper. Specifically, during the first learning phase, we present a Multi-scale Contrastive Text-audio Pre-training protocol (MC-TAP), which hammers at acquiring richer insights via multi-granularity contrastive pre-training in an unsupervised manner. Instead of mining homogeneous features in prior pre-training approaches, our framework demonstrates the ability to delve deep into both global and local text-audio semantic and acoustic representations. Furthermore, a parallelized TTS frontend model is delicately devised to execute TN, PD, and PBP prediction tasks, respectively in the second stage. Finally, extensive experiments illustrate the superiority of our proposed method, achieving state-of-the-art performance.
Multi-Modal Automatic Prosody Annotation with Contrastive Pretraining of SSWP
Sep 11, 2023

In the realm of expressive Text-to-Speech (TTS), explicit prosodic boundaries significantly advance the naturalness and controllability of synthesized speech. While human prosody annotation contributes a lot to the performance, it is a labor-intensive and time-consuming process, often resulting in inconsistent outcomes. Despite the availability of extensive supervised data, the current benchmark model still faces performance setbacks. To address this issue, a two-stage automatic annotation pipeline is novelly proposed in this paper. Specifically, in the first stage, we propose contrastive text-speech pretraining of Speech-Silence and Word-Punctuation (SSWP) pairs. The pretraining procedure hammers at enhancing the prosodic space extracted from joint text-speech space. In the second stage, we build a multi-modal prosody annotator, which consists of pretrained encoders, a straightforward yet effective text-speech feature fusion scheme, and a sequence classifier. Extensive experiments conclusively demonstrate that our proposed method excels at automatically generating prosody annotation and achieves state-of-the-art (SOTA) performance. Furthermore, our novel model has exhibited remarkable resilience when tested with varying amounts of data.
TranssionADD: A multi-frame reinforcement based sequence tagging model for audio deepfake detection
Jun 27, 2023


Thanks to recent advancements in end-to-end speech modeling technology, it has become increasingly feasible to imitate and clone a user`s voice. This leads to a significant challenge in differentiating between authentic and fabricated audio segments. To address the issue of user voice abuse and misuse, the second Audio Deepfake Detection Challenge (ADD 2023) aims to detect and analyze deepfake speech utterances. Specifically, Track 2, named the Manipulation Region Location (RL), aims to pinpoint the location of manipulated regions in audio, which can be present in both real and generated audio segments. We propose our novel TranssionADD system as a solution to the challenging problem of model robustness and audio segment outliers in the trace competition. Our system provides three unique contributions: 1) we adapt sequence tagging task for audio deepfake detection; 2) we improve model generalization by various data augmentation techniques; 3) we incorporate multi-frame detection (MFD) module to overcome limited representation provided by a single frame and use isolated-frame penalty (IFP) loss to handle outliers in segments. Our best submission achieved 2nd place in Track 2, demonstrating the effectiveness and robustness of our proposed system.
CPNet: Exploiting CLIP-based Attention Condenser and Probability Map Guidance for High-fidelity Talking Face Generation
May 23, 2023



Recently, talking face generation has drawn ever-increasing attention from the research community in computer vision due to its arduous challenges and widespread application scenarios, e.g. movie animation and virtual anchor. Although persevering efforts have been undertaken to enhance the fidelity and lip-sync quality of generated talking face videos, there is still large room for further improvements of synthesis quality and efficiency. Actually, these attempts somewhat ignore the explorations of fine-granularity feature extraction/integration and the consistency between probability distributions of landmarks, thereby recurring the issues of local details blurring and degraded fidelity. To mitigate these dilemmas, in this paper, a novel CLIP-based Attention and Probability Map Guided Network (CPNet) is delicately designed for inferring high-fidelity talking face videos. Specifically, considering the demands of fine-grained feature recalibration, a clip-based attention condenser is exploited to transfer knowledge with rich semantic priors from the prevailing CLIP model. Moreover, to guarantee the consistency in probability space and suppress the landmark ambiguity, we creatively propose the density map of facial landmark as auxiliary supervisory signal to guide the landmark distribution learning of generated frame. Extensive experiments on the widely-used benchmark dataset demonstrate the superiority of our CPNet against state of the arts in terms of image and lip-sync quality. In addition, a cohort of studies are also conducted to ablate the impacts of the individual pivotal components.
Towards Realistic Visual Dubbing with Heterogeneous Sources
Jan 17, 2022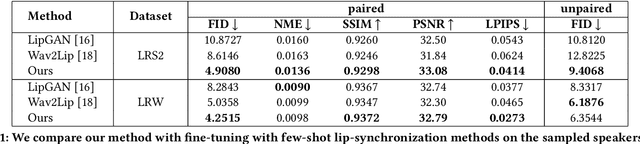
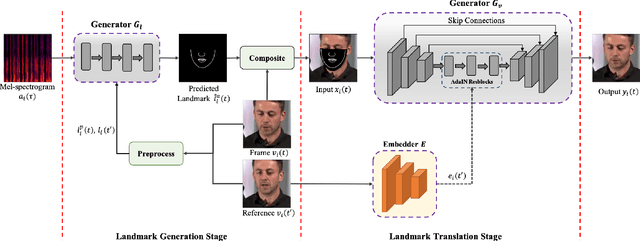
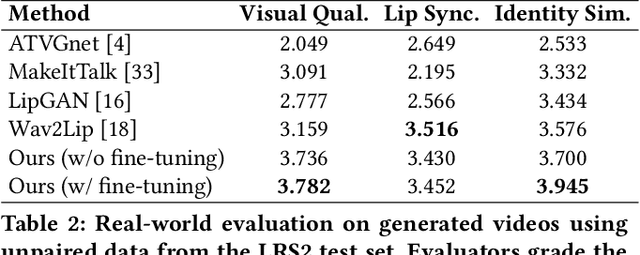
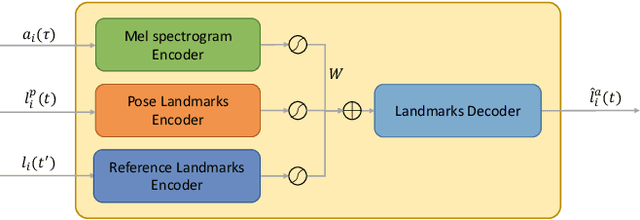
The task of few-shot visual dubbing focuses on synchronizing the lip movements with arbitrary speech input for any talking head video. Albeit moderate improvements in current approaches, they commonly require high-quality homologous data sources of videos and audios, thus causing the failure to leverage heterogeneous data sufficiently. In practice, it may be intractable to collect the perfect homologous data in some cases, for example, audio-corrupted or picture-blurry videos. To explore this kind of data and support high-fidelity few-shot visual dubbing, in this paper, we novelly propose a simple yet efficient two-stage framework with a higher flexibility of mining heterogeneous data. Specifically, our two-stage paradigm employs facial landmarks as intermediate prior of latent representations and disentangles the lip movements prediction from the core task of realistic talking head generation. By this means, our method makes it possible to independently utilize the training corpus for two-stage sub-networks using more available heterogeneous data easily acquired. Besides, thanks to the disentanglement, our framework allows a further fine-tuning for a given talking head, thereby leading to better speaker-identity preserving in the final synthesized results. Moreover, the proposed method can also transfer appearance features from others to the target speaker. Extensive experimental results demonstrate the superiority of our proposed method in generating highly realistic videos synchronized with the speech over the state-of-the-art.
Towards Using Clothes Style Transfer for Scenario-aware Person Video Generation
Oct 25, 2021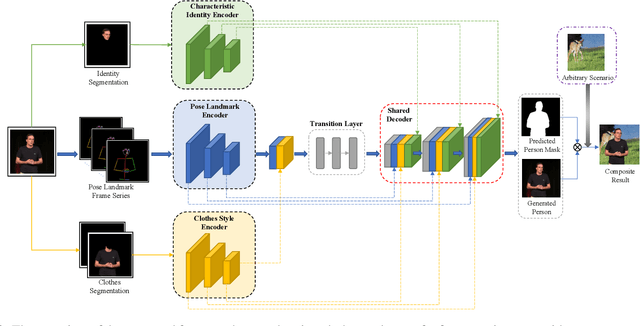
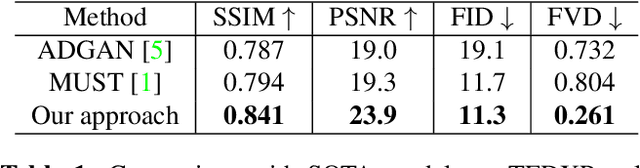
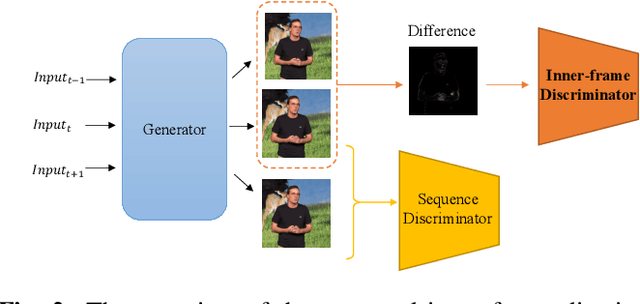
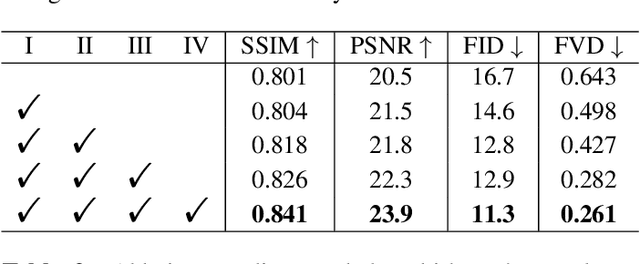
Clothes style transfer for person video generation is a challenging task, due to drastic variations of intra-person appearance and video scenarios. To tackle this problem, most recent AdaIN-based architectures are proposed to extract clothes and scenario features for generation. However, these approaches suffer from being short of fine-grained details and are prone to distort the origin person. To further improve the generation performance, we propose a novel framework with disentangled multi-branch encoders and a shared decoder. Moreover, to pursue the strong video spatio-temporal consistency, an inner-frame discriminator is delicately designed with input being cross-frame difference. Besides, the proposed framework possesses the property of scenario adaptation. Extensive experiments on the TEDXPeople benchmark demonstrate the superiority of our method over state-of-the-art approaches in terms of image quality and video coherence.
Towards High-fidelity Singing Voice Conversion with Acoustic Reference and Contrastive Predictive Coding
Oct 10, 2021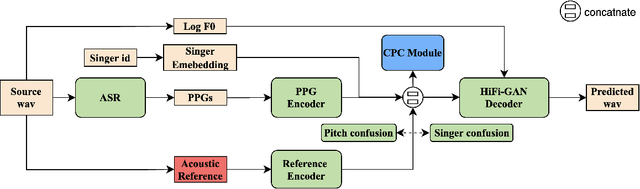
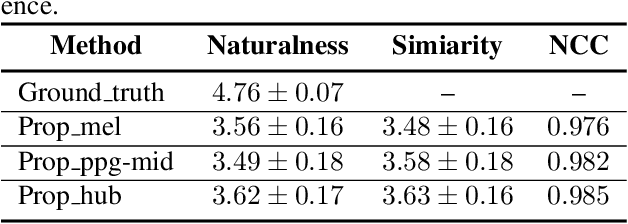

Recently, phonetic posteriorgrams (PPGs) based methods have been quite popular in non-parallel singing voice conversion systems. However, due to the lack of acoustic information in PPGs, style and naturalness of the converted singing voices are still limited. To solve these problems, in this paper, we utilize an acoustic reference encoder to implicitly model singing characteristics. We experiment with different auxiliary features, including mel spectrograms, HuBERT, and the middle hidden feature (PPG-Mid) of pretrained automatic speech recognition (ASR) model, as the input of the reference encoder, and finally find the HuBERT feature is the best choice. In addition, we use contrastive predictive coding (CPC) module to further smooth the voices by predicting future observations in latent space. Experiments show that, compared with the baseline models, our proposed model can significantly improve the naturalness of converted singing voices and the similarity with the target singer. Moreover, our proposed model can also make the speakers with just speech data sing.
PPG-based singing voice conversion with adversarial representation learning
Oct 28, 2020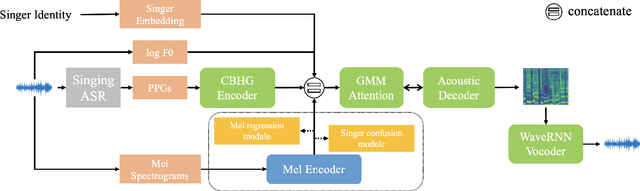
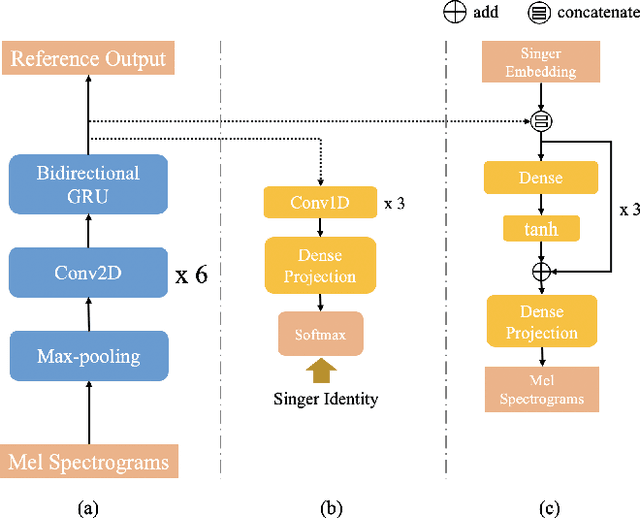
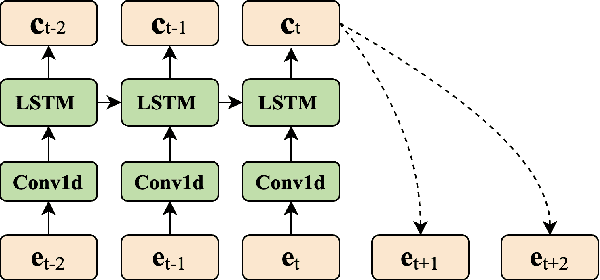
Singing voice conversion (SVC) aims to convert the voice of one singer to that of other singers while keeping the singing content and melody. On top of recent voice conversion works, we propose a novel model to steadily convert songs while keeping their naturalness and intonation. We build an end-to-end architecture, taking phonetic posteriorgrams (PPGs) as inputs and generating mel spectrograms. Specifically, we implement two separate encoders: one encodes PPGs as content, and the other compresses mel spectrograms to supply acoustic and musical information. To improve the performance on timbre and melody, an adversarial singer confusion module and a mel-regressive representation learning module are designed for the model. Objective and subjective experiments are conducted on our private Chinese singing corpus. Comparing with the baselines, our methods can significantly improve the conversion performance in terms of naturalness, melody, and voice similarity. Moreover, our PPG-based method is proved to be robust for noisy sources.
Improving Accent Conversion with Reference Encoder and End-To-End Text-To-Speech
May 19, 2020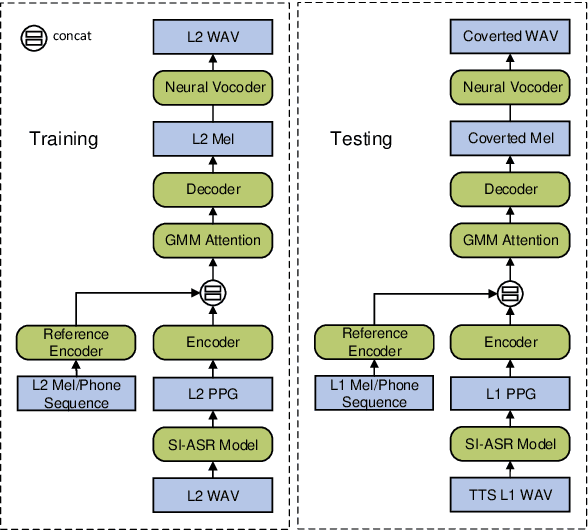
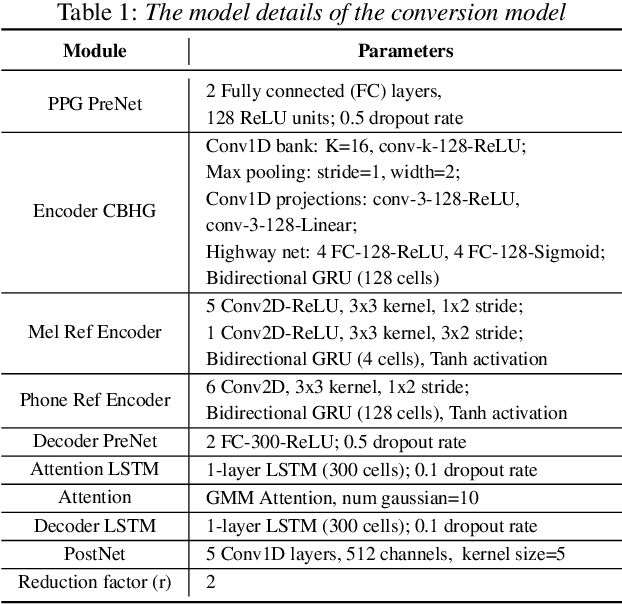
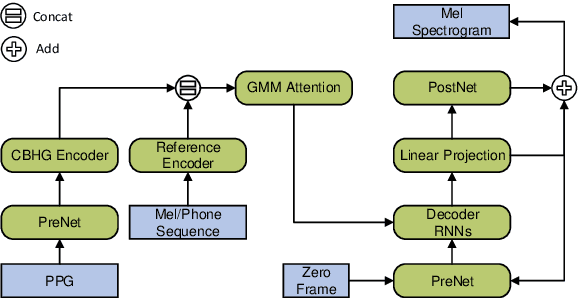
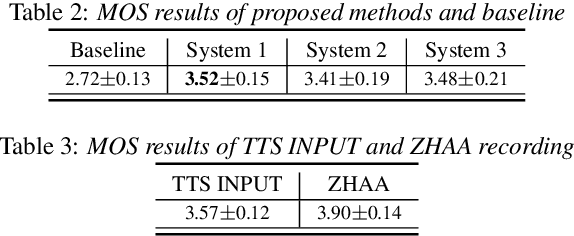
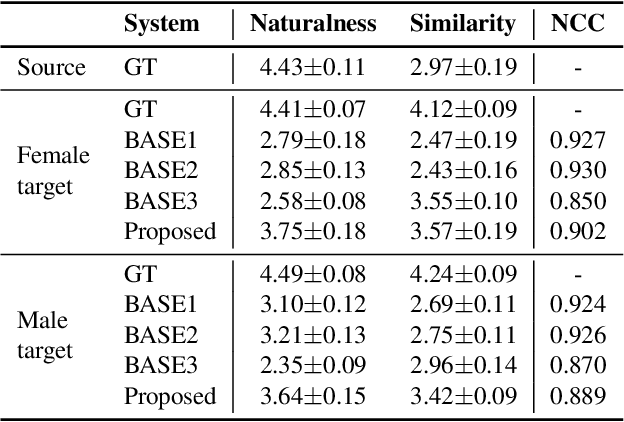
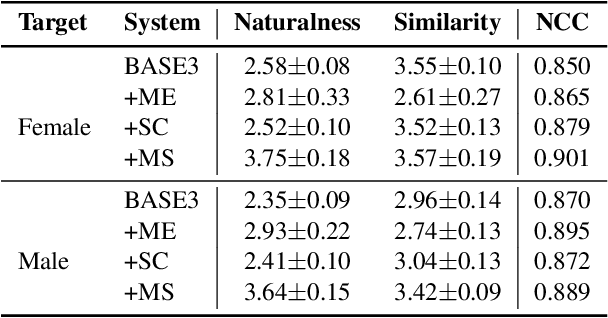
Accent conversion (AC) transforms a non-native speaker's accent into a native accent while maintaining the speaker's voice timbre. In this paper, we propose approaches to improving accent conversion applicability, as well as quality. First of all, we assume no reference speech is available at the conversion stage, and hence we employ an end-to-end text-to-speech system that is trained on native speech to generate native reference speech. To improve the quality and accent of the converted speech, we introduce reference encoders which make us capable of utilizing multi-source information. This is motivated by acoustic features extracted from native reference and linguistic information, which are complementary to conventional phonetic posteriorgrams (PPGs), so they can be concatenated as features to improve a baseline system based only on PPGs. Moreover, we optimize model architecture using GMM-based attention instead of windowed attention to elevate synthesized performance. Experimental results indicate when the proposed techniques are applied the integrated system significantly raises the scores of acoustic quality (30$\%$ relative increase in mean opinion score) and native accent (68$\%$ relative preference) while retaining the voice identity of the non-native speaker.