 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Trajectory-Driven Spatio-Temporal Refinement Solution for CVPR 2026 8th UG2+ Challenge Track 3: DOST
Jun 04, 2026In this work, we present our solution for the 8th UG2+ Challenge (CVPR 2026) Track 3: Dynamic Object Segmentation in Turbulence (DOST). Our method is built upon the strong baseline framework Segment Any Motion (SegAnyMo), which provides powerful mask generation and motion tracking capabilities. To further boost the segmentation performance under severe atmospheric distortions, we propose two key improvements. First, we employ a data-centric domain adaptation strategy. We significantly expand our training data by incorporating selected sequences from the DAVIS dataset alongside a subset of the DOST dataset, and apply simulated atmospheric fluctuation degradations to enhance the model's robustness against complex geometric distortions. Second, we introduce a spatio-temporal post-processing module. This refinement step effectively removes persistent boundary-connected false foregrounds and short-lived fragmented noise, while strictly preserving genuine small targets and maintaining original individual labels across frames. With these combined strategies, our proposed method ranks the 2st place in the challenge.
An Effective Solution for the CVPR 2026 8th UG2+ Challenge Track 3: Dynamic Object Segmentation in Turbulence
May 30, 2026In this work, we present our solution for the 8th UG2+ Challenge (CVPR 2026) Track 3: Dynamic Object Segmentation in Turbulence (DOST). Our method is built upon the strong baseline framework Segment Any Motion (SegAnyMo), which provides powerful mask generation and motion tracking capabilities. To further boost the segmentation performance under severe atmospheric distortions, we propose two key improvements. First, we employ a data-centric domain adaptation strategy. We significantly expand our training data by incorporating selected sequences from the DAVIS dataset alongside a subset of the DOST dataset, and apply simulated atmospheric fluctuation degradations to enhance the model's robustness against complex geometric distortions. Second, we introduce a spatio-temporal post-processing module. This refinement step effectively removes persistent boundary-connected false foregrounds and short-lived fragmented noise, while strictly preserving genuine small targets and maintaining original individual labels across frames. With these combined strategies, our proposed method ranks the 2st place in the challenge.
X-Restormer++: 1st Place Solution for the UG2+ CVPR 2026 All-Weather Restoration Challenge
May 13, 2026In this work, we present our winning solution for the 8th UG2+ Challenge (CVPR 2026) Track 1: Image Restoration under All-weather Conditions. Our method is built upon the strong baseline framework X-Restormer, which effectively captures both channel-wise global dependencies and spatially-local structural information through its dual-attention design (Multi-DConv Head Transposed Attention and Overlapping Cross-Attention). To further boost the restoration performance, we propose several key improvements. First, we integrate the spatially-adaptive input scaling mechanism from Restormer-Plus to dynamically adjust the spatial weights of the input image, enhancing spatial adaptability. Second, to better preserve structural details and edge information, we introduce a novel Gradient-Guided Edge-Aware (GGEA) loss, which is combined with L1 and Multi-Scale SSIM losses in a unified training objective. Third, we significantly expand the training data by incorporating an extra 24,500 degraded-clean image pairs from FoundIR and WeatherBench alongside the original WeatherStream dataset. With these strategies, our proposed method successfully ranks the 1st place in the challenge.
Enhancing Sa2VA for Referent Video Object Segmentation: 2nd Solution for 7th LSVOS RVOS Track
Sep 19, 2025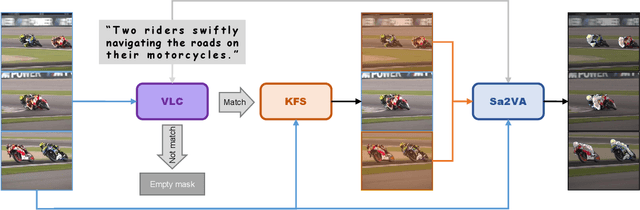



Referential Video Object Segmentation (RVOS) aims to segment all objects in a video that match a given natural language description, bridging the gap between vision and language understanding. Recent work, such as Sa2VA, combines Large Language Models (LLMs) with SAM~2, leveraging the strong video reasoning capability of LLMs to guide video segmentation. In this work, we present a training-free framework that substantially improves Sa2VA's performance on the RVOS task. Our method introduces two key components: (1) a Video-Language Checker that explicitly verifies whether the subject and action described in the query actually appear in the video, thereby reducing false positives; and (2) a Key-Frame Sampler that adaptively selects informative frames to better capture both early object appearances and long-range temporal context. Without any additional training, our approach achieves a J&F score of 64.14% on the MeViS test set, ranking 2nd place in the RVOS track of the 7th LSVOS Challenge at ICCV 2025.
Pseudo-Label Enhanced Cascaded Framework: 2nd Technical Report for LSVOS 2025 VOS Track
Sep 18, 2025



Complex Video Object Segmentation (VOS) presents significant challenges in accurately segmenting objects across frames, especially in the presence of small and similar targets, frequent occlusions, rapid motion, and complex interactions. In this report, we present our solution for the LSVOS 2025 VOS Track based on the SAM2 framework. We adopt a pseudo-labeling strategy during training: a trained SAM2 checkpoint is deployed within the SAM2Long framework to generate pseudo labels for the MOSE test set, which are then combined with existing data for further training. For inference, the SAM2Long framework is employed to obtain our primary segmentation results, while an open-source SeC model runs in parallel to produce complementary predictions. A cascaded decision mechanism dynamically integrates outputs from both models, exploiting the temporal stability of SAM2Long and the concept-level robustness of SeC. Benefiting from pseudo-label training and cascaded multi-model inference, our approach achieves a J\&F score of 0.8616 on the MOSE test set -- +1.4 points over our SAM2Long baseline -- securing the 2nd place in the LSVOS 2025 VOS Track, and demonstrating strong robustness and accuracy in long, complex video segmentation scenarios.
Multi-Modal Automatic Prosody Annotation with Contrastive Pretraining of SSWP
Sep 11, 2023

In the realm of expressive Text-to-Speech (TTS), explicit prosodic boundaries significantly advance the naturalness and controllability of synthesized speech. While human prosody annotation contributes a lot to the performance, it is a labor-intensive and time-consuming process, often resulting in inconsistent outcomes. Despite the availability of extensive supervised data, the current benchmark model still faces performance setbacks. To address this issue, a two-stage automatic annotation pipeline is novelly proposed in this paper. Specifically, in the first stage, we propose contrastive text-speech pretraining of Speech-Silence and Word-Punctuation (SSWP) pairs. The pretraining procedure hammers at enhancing the prosodic space extracted from joint text-speech space. In the second stage, we build a multi-modal prosody annotator, which consists of pretrained encoders, a straightforward yet effective text-speech feature fusion scheme, and a sequence classifier. Extensive experiments conclusively demonstrate that our proposed method excels at automatically generating prosody annotation and achieves state-of-the-art (SOTA) performance. Furthermore, our novel model has exhibited remarkable resilience when tested with varying amounts of data.
TranssionADD: A multi-frame reinforcement based sequence tagging model for audio deepfake detection
Jun 27, 2023


Thanks to recent advancements in end-to-end speech modeling technology, it has become increasingly feasible to imitate and clone a user`s voice. This leads to a significant challenge in differentiating between authentic and fabricated audio segments. To address the issue of user voice abuse and misuse, the second Audio Deepfake Detection Challenge (ADD 2023) aims to detect and analyze deepfake speech utterances. Specifically, Track 2, named the Manipulation Region Location (RL), aims to pinpoint the location of manipulated regions in audio, which can be present in both real and generated audio segments. We propose our novel TranssionADD system as a solution to the challenging problem of model robustness and audio segment outliers in the trace competition. Our system provides three unique contributions: 1) we adapt sequence tagging task for audio deepfake detection; 2) we improve model generalization by various data augmentation techniques; 3) we incorporate multi-frame detection (MFD) module to overcome limited representation provided by a single frame and use isolated-frame penalty (IFP) loss to handle outliers in segments. Our best submission achieved 2nd place in Track 2, demonstrating the effectiveness and robustness of our proposed system.