 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding
Apr 29, 2024



We present LayerSkip, an end-to-end solution to speed-up inference of large language models (LLMs). First, during training we apply layer dropout, with low dropout rates for earlier layers and higher dropout rates for later layers, and an early exit loss where all transformer layers share the same exit. Second, during inference, we show that this training recipe increases the accuracy of early exit at earlier layers, without adding any auxiliary layers or modules to the model. Third, we present a novel self-speculative decoding solution where we exit at early layers and verify and correct with remaining layers of the model. Our proposed self-speculative decoding approach has less memory footprint than other speculative decoding approaches and benefits from shared compute and activations of the draft and verification stages. We run experiments on different Llama model sizes on different types of training: pretraining from scratch, continual pretraining, finetuning on specific data domain, and finetuning on specific task. We implement our inference solution and show speedups of up to 2.16x on summarization for CNN/DM documents, 1.82x on coding, and 2.0x on TOPv2 semantic parsing task.
MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
Feb 22, 2024This paper addresses the growing need for efficient large language models (LLMs) on mobile devices, driven by increasing cloud costs and latency concerns. We focus on designing top-quality LLMs with fewer than a billion parameters, a practical choice for mobile deployment. Contrary to prevailing belief emphasizing the pivotal role of data and parameter quantity in determining model quality, our investigation underscores the significance of model architecture for sub-billion scale LLMs. Leveraging deep and thin architectures, coupled with embedding sharing and grouped-query attention mechanisms, we establish a strong baseline network denoted as MobileLLM, which attains a remarkable 2.7%/4.3% accuracy boost over preceding 125M/350M state-of-the-art models. Additionally, we propose an immediate block-wise weight sharing approach with no increase in model size and only marginal latency overhead. The resultant models, denoted as MobileLLM-LS, demonstrate a further accuracy enhancement of 0.7%/0.8% than MobileLLM 125M/350M. Moreover, MobileLLM model family shows significant improvements compared to previous sub-billion models on chat benchmarks, and demonstrates close correctness to LLaMA-v2 7B in API calling tasks, highlighting the capability of small models for common on-device use cases.
Not All Weights Are Created Equal: Enhancing Energy Efficiency in On-Device Streaming Speech Recognition
Feb 20, 2024



Power consumption plays an important role in on-device streaming speech recognition, as it has a direct impact on the user experience. This study delves into how weight parameters in speech recognition models influence the overall power consumption of these models. We discovered that the impact of weight parameters on power consumption varies, influenced by factors including how often they are invoked and their placement in memory. Armed with this insight, we developed design guidelines aimed at optimizing on-device speech recognition models. These guidelines focus on minimizing power use without substantially affecting accuracy. Our method, which employs targeted compression based on the varying sensitivities of weight parameters, demonstrates superior performance compared to state-of-the-art compression methods. It achieves a reduction in energy usage of up to 47% while maintaining similar model accuracy and improving the real-time factor.
Folding Attention: Memory and Power Optimization for On-Device Transformer-based Streaming Speech Recognition
Sep 21, 2023



Transformer-based models excel in speech recognition. Existing efforts to optimize Transformer inference, typically for long-context applications, center on simplifying attention score calculations. However, streaming speech recognition models usually process a limited number of tokens each time, making attention score calculation less of a bottleneck. Instead, the bottleneck lies in the linear projection layers of multi-head attention and feedforward networks, constituting a substantial portion of the model size and contributing significantly to computation, memory, and power usage. To address this bottleneck, we propose folding attention, a technique targeting these linear layers, significantly reducing model size and improving memory and power efficiency. Experiments on on-device Transformer-based streaming speech recognition models show that folding attention reduces model size (and corresponding memory consumption) by up to 24% and power consumption by up to 23%, all without compromising model accuracy or computation overhead.
SDRM3: A Dynamic Scheduler for Dynamic Real-time Multi-model ML Workloads
Dec 07, 2022



Emerging real-time multi-model ML (RTMM) workloads such as AR/VR and drone control often involve dynamic behaviors in various levels; task, model, and layers (or, ML operators) within a model. Such dynamic behaviors are new challenges to the system software in an ML system because the overall system load is unpredictable unlike traditional ML workloads. Also, the real-time processing requires to meet deadlines, and multi-model workloads involve highly heterogeneous models. As RTMM workloads often run on resource-constrained devices (e.g., VR headset), developing an effective scheduler is an important research problem. Therefore, we propose a new scheduler, SDRM3, that effectively handles various dynamicity in RTMM style workloads targeting multi-accelerator systems. To make scheduling decisions, SDRM3 quantifies the unique requirements for RTMM workloads and utilizes the quantified scores to drive scheduling decisions, considering the current system load and other inference jobs on different models and input frames. SDRM3 has tunable parameters that provide fast adaptivity to dynamic workload changes based on a gradient descent-like online optimization, which typically converges within five steps for new workloads. In addition, we also propose a method to exploit model level dynamicity based on Supernet for exploiting the trade-off between the scheduling effectiveness and model performance (e.g., accuracy), which dynamically selects a proper sub-network in a Supernet based on the system loads. In our evaluation on five realistic RTMM workload scenarios, SDRM3 reduces the overall UXCost, which is a energy-delay-product (EDP)-equivalent metric for real-time applications defined in the paper, by 37.7% and 53.2% on geometric mean (up to 97.6% and 97.1%) compared to state-of-the-art baselines, which shows the efficacy of our scheduling methodology.
XRBench: An Extended Reality (XR) Machine Learning Benchmark Suite for the Metaverse
Nov 16, 2022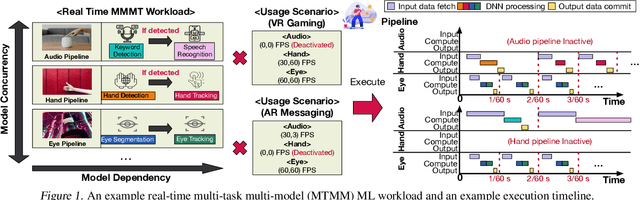
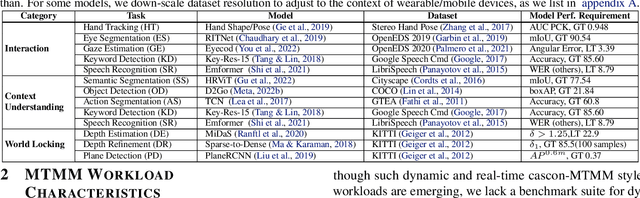

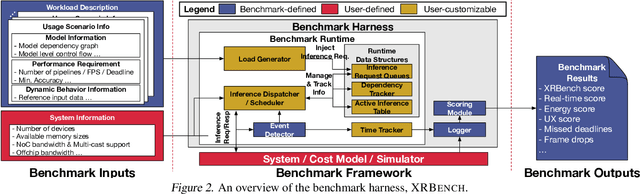
Real-time multi-model multi-task (MMMT) workloads, a new form of deep learning inference workloads, are emerging for applications areas like extended reality (XR) to support metaverse use cases. These workloads combine user interactivity with computationally complex machine learning (ML) activities. Compared to standard ML applications, these ML workloads present unique difficulties and constraints. Real-time MMMT workloads impose heterogeneity and concurrency requirements on future ML systems and devices, necessitating the development of new capabilities. This paper begins with a discussion of the various characteristics of these real-time MMMT ML workloads and presents an ontology for evaluating the performance of future ML hardware for XR systems. Next, we present XRBench, a collection of MMMT ML tasks, models, and usage scenarios that execute these models in three representative ways: cascaded, concurrent, and cascaded-concurrency for XR use cases. Finally, we emphasize the need for new metrics that capture the requirements properly. We hope that our work will stimulate research and lead to the development of a new generation of ML systems for XR use cases.
Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation
Nov 23, 2021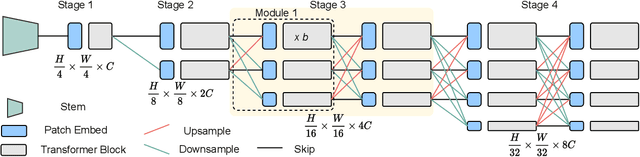

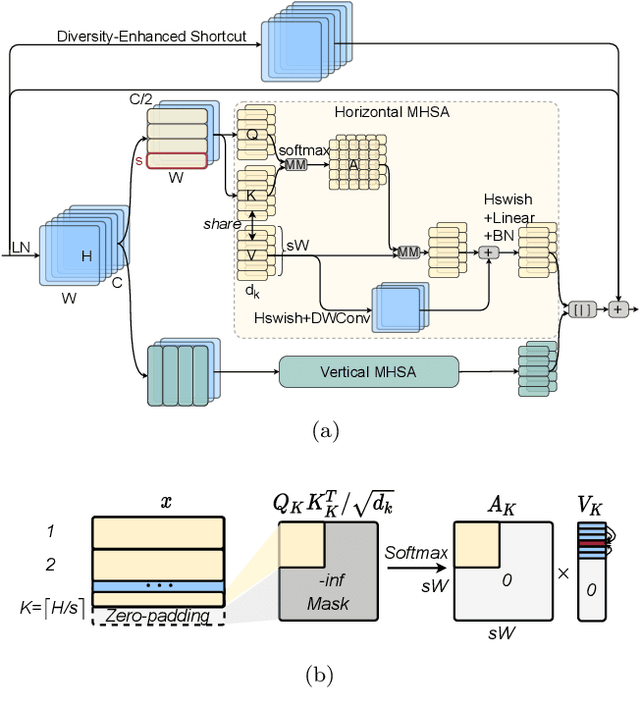
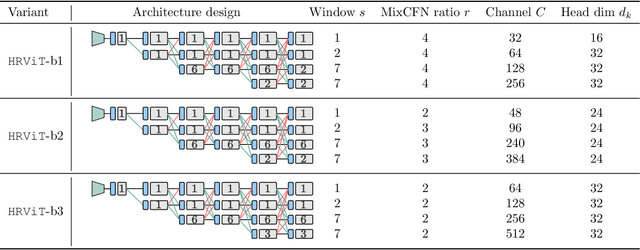
Vision Transformers (ViTs) have emerged with superior performance on computer vision tasks compared to convolutional neural network (CNN)-based models. However, ViTs are mainly designed for image classification that generate single-scale low-resolution representations, which makes dense prediction tasks such as semantic segmentation challenging for ViTs. Therefore, we propose HRViT, which enhances ViTs to learn semantically-rich and spatially-precise multi-scale representations by integrating high-resolution multi-branch architectures with ViTs. We balance the model performance and efficiency of HRViT by various branch-block co-optimization techniques. Specifically, we explore heterogeneous branch designs, reduce the redundancy in linear layers, and augment the attention block with enhanced expressiveness. Those approaches enabled HRViT to push the Pareto frontier of performance and efficiency on semantic segmentation to a new level, as our evaluation results on ADE20K and Cityscapes show. HRViT achieves 50.20% mIoU on ADE20K and 83.16% mIoU on Cityscapes, surpassing state-of-the-art MiT and CSWin backbones with an average of +1.78 mIoU improvement, 28% parameter saving, and 21% FLOPs reduction, demonstrating the potential of HRViT as a strong vision backbone for semantic segmentation.
Low-Rank+Sparse Tensor Compression for Neural Networks
Nov 02, 2021
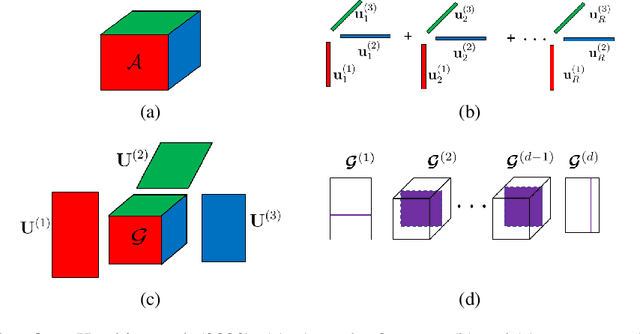
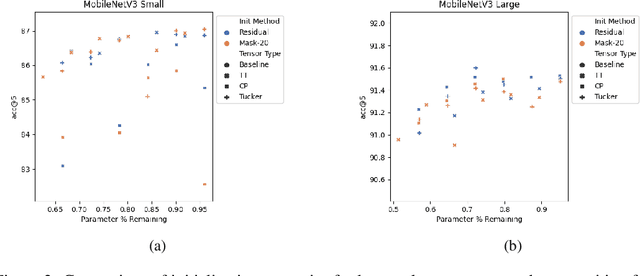
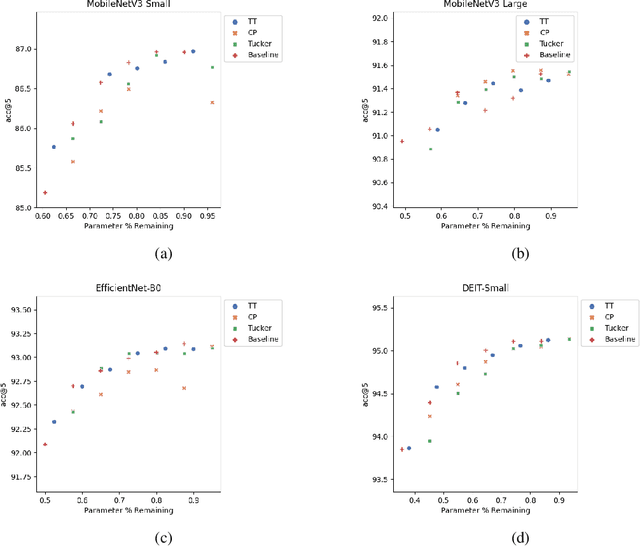
Low-rank tensor compression has been proposed as a promising approach to reduce the memory and compute requirements of neural networks for their deployment on edge devices. Tensor compression reduces the number of parameters required to represent a neural network weight by assuming network weights possess a coarse higher-order structure. This coarse structure assumption has been applied to compress large neural networks such as VGG and ResNet. However modern state-of-the-art neural networks for computer vision tasks (i.e. MobileNet, EfficientNet) already assume a coarse factorized structure through depthwise separable convolutions, making pure tensor decomposition a less attractive approach. We propose to combine low-rank tensor decomposition with sparse pruning in order to take advantage of both coarse and fine structure for compression. We compress weights in SOTA architectures (MobileNetv3, EfficientNet, Vision Transformer) and compare this approach to sparse pruning and tensor decomposition alone.
Improving Efficiency in Neural Network Accelerator Using Operands Hamming Distance optimization
Feb 13, 2020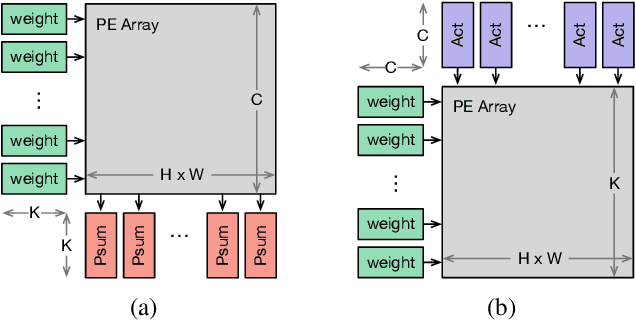

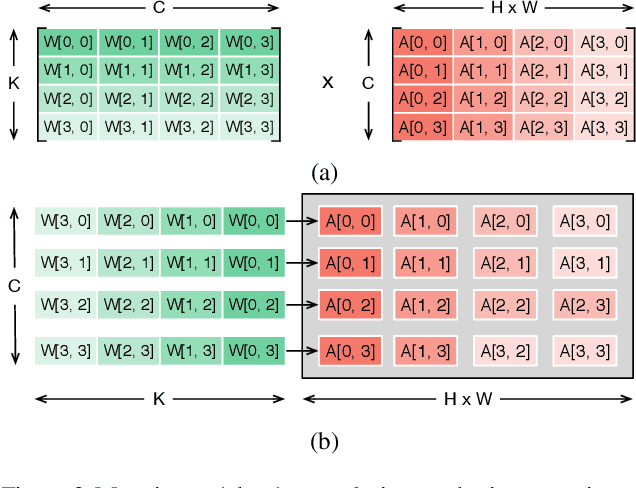
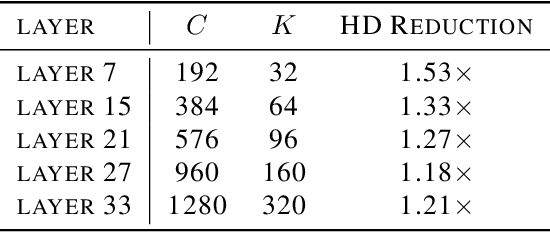
Neural network accelerator is a key enabler for the on-device AI inference, for which energy efficiency is an important metric. The data-path energy, including the computation energy and the data movement energy among the arithmetic units, claims a significant part of the total accelerator energy. By revisiting the basic physics of the arithmetic logic circuits, we show that the data-path energy is highly correlated with the bit flips when streaming the input operands into the arithmetic units, defined as the hamming distance of the input operand matrices. Based on the insight, we propose a post-training optimization algorithm and a hamming-distance-aware training algorithm to co-design and co-optimize the accelerator and the network synergistically. The experimental results based on post-layout simulation with MobileNetV2 demonstrate on average 2.85X data-path energy reduction and up to 8.51X data-path energy reduction for certain layers.
Co-Exploration of Neural Architectures and Heterogeneous ASIC Accelerator Designs Targeting Multiple Tasks
Feb 10, 2020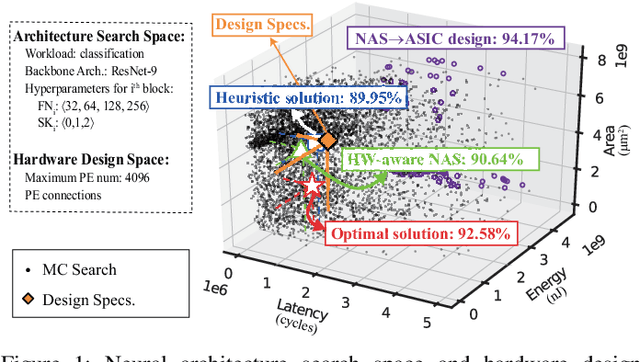
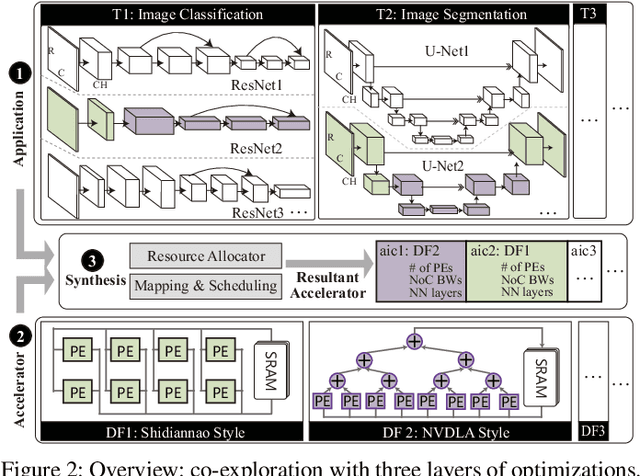
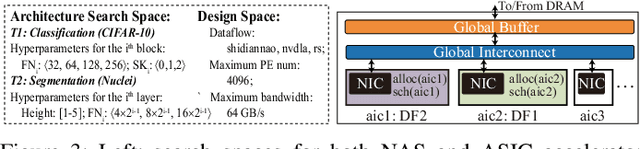
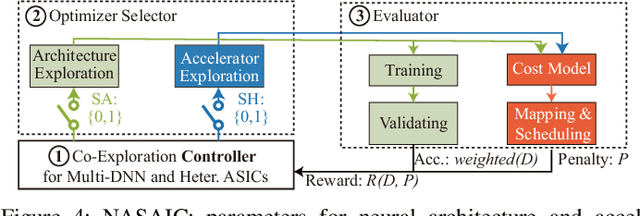
Neural Architecture Search (NAS) has demonstrated its power on various AI accelerating platforms such as Field Programmable Gate Arrays (FPGAs) and Graphic Processing Units (GPUs). However, it remains an open problem, how to integrate NAS with Application-Specific Integrated Circuits (ASICs), despite them being the most powerful AI accelerating platforms. The major bottleneck comes from the large design freedom associated with ASIC designs. Moreover, with the consideration that multiple DNNs will run in parallel for different workloads with diverse layer operations and sizes, integrating heterogeneous ASIC sub-accelerators for distinct DNNs in one design can significantly boost performance, and at the same time further complicate the design space. To address these challenges, in this paper we build ASIC template set based on existing successful designs, described by their unique dataflows, so that the design space is significantly reduced. Based on the templates, we further propose a framework, namely NASAIC, which can simultaneously identify multiple DNN architectures and the associated heterogeneous ASIC accelerator design, such that the design specifications (specs) can be satisfied, while the accuracy can be maximized. Experimental results show that compared with successive NAS and ASIC design optimizations which lead to design spec violations, NASAIC can guarantee the results to meet the design specs with 17.77%, 2.49x, and 2.32x reductions on latency, energy, and area and with 0.76% accuracy loss. To the best of the authors' knowledge, this is the first work on neural architecture and ASIC accelerator design co-exploration.