 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Human-AI Interaction Alignment: Designing, Evaluating, and Evolving Value-Centered AI For Reciprocal Human-AI Futures
Dec 25, 2025The rapid integration of generative AI into everyday life underscores the need to move beyond unidirectional alignment models that only adapt AI to human values. This workshop focuses on bidirectional human-AI alignment, a dynamic, reciprocal process where humans and AI co-adapt through interaction, evaluation, and value-centered design. Building on our past CHI 2025 BiAlign SIG and ICLR 2025 Workshop, this workshop will bring together interdisciplinary researchers from HCI, AI, social sciences and more domains to advance value-centered AI and reciprocal human-AI collaboration. We focus on embedding human and societal values into alignment research, emphasizing not only steering AI toward human values but also enabling humans to critically engage with and evolve alongside AI systems. Through talks, interdisciplinary discussions, and collaborative activities, participants will explore methods for interactive alignment, frameworks for societal impact evaluation, and strategies for alignment in dynamic contexts. This workshop aims to bridge the disciplines' gaps and establish a shared agenda for responsible, reciprocal human-AI futures.
UltraShape 1.0: High-Fidelity 3D Shape Generation via Scalable Geometric Refinement
Dec 24, 2025In this report, we introduce UltraShape 1.0, a scalable 3D diffusion framework for high-fidelity 3D geometry generation. The proposed approach adopts a two-stage generation pipeline: a coarse global structure is first synthesized and then refined to produce detailed, high-quality geometry. To support reliable 3D generation, we develop a comprehensive data processing pipeline that includes a novel watertight processing method and high-quality data filtering. This pipeline improves the geometric quality of publicly available 3D datasets by removing low-quality samples, filling holes, and thickening thin structures, while preserving fine-grained geometric details. To enable fine-grained geometry refinement, we decouple spatial localization from geometric detail synthesis in the diffusion process. We achieve this by performing voxel-based refinement at fixed spatial locations, where voxel queries derived from coarse geometry provide explicit positional anchors encoded via RoPE, allowing the diffusion model to focus on synthesizing local geometric details within a reduced, structured solution space. Our model is trained exclusively on publicly available 3D datasets, achieving strong geometric quality despite limited training resources. Extensive evaluations demonstrate that UltraShape 1.0 performs competitively with existing open-source methods in both data processing quality and geometry generation. All code and trained models will be released to support future research.
Multimodal Classification Network Guided Trajectory Planning for Four-Wheel Independent Steering Autonomous Parking Considering Obstacle Attributes
Dec 21, 2025Four-wheel Independent Steering (4WIS) vehicles have attracted increasing attention for their superior maneuverability. Human drivers typically choose to cross or drive over the low-profile obstacles (e.g., plastic bags) to efficiently navigate through narrow spaces, while existing planners neglect obstacle attributes, causing inefficiency or path-finding failures. To address this, we propose a trajectory planning framework integrating the 4WIS hybrid A* and Optimal Control Problem (OCP), in which the hybrid A* provides an initial path to enhance the OCP solution. Specifically, a multimodal classification network is introduced to assess scene complexity (hard/easy task) by fusing image and vehicle state data. For hard tasks, guided points are set to decompose complex tasks into local subtasks, improving the search efficiency of 4WIS hybrid A*. The multiple steering modes of 4WIS vehicles (Ackermann, diagonal, and zero-turn) are also incorporated into node expansion and heuristic designs. Moreover, a hierarchical obstacle handling strategy is designed to guide the node expansion considering obstacle attributes, i.e., 'non-traversable', 'crossable', and 'drive-over' obstacles. It allows crossing or driving over obstacles instead of the 'avoid-only' strategy, greatly enhancing success rates of pathfinding. We also design a logical constraint for the 'drive-over' obstacle by limiting its velocity to ensure safety. Furthermore, to address dynamic obstacles with motion uncertainty, we introduce a probabilistic risk field model, constructing risk-aware driving corridors that serve as linear collision constraints in OCP. Experimental results demonstrate the proposed framework's effectiveness in generating safe, efficient, and smooth trajectories for 4WIS vehicles, especially in constrained environments.
Reasoning Palette: Modulating Reasoning via Latent Contextualization for Controllable Exploration for (V)LMs
Dec 19, 2025



Exploration capacity shapes both inference-time performance and reinforcement learning (RL) training for large (vision-) language models, as stochastic sampling often yields redundant reasoning paths with little high-level diversity. This paper proposes Reasoning Palette, a novel latent-modulation framework that endows the model with a stochastic latent variable for strategic contextualization, guiding its internal planning prior to token generation. This latent context is inferred from the mean-pooled embedding of a question-answer pair via a variational autoencoder (VAE), where each sampled latent potentially encodes a distinct reasoning context. During inference, a sampled latent is decoded into learnable token prefixes and prepended to the input prompt, modulating the model's internal reasoning trajectory. In this way, the model performs internal sampling over reasoning strategies prior to output generation, which shapes the style and structure of the entire response sequence. A brief supervised fine-tuning (SFT) warm-up phase allows the model to adapt to this latent conditioning. Within RL optimization, Reasoning Palette facilitates structured exploration by enabling on-demand injection for diverse reasoning modes, significantly enhancing exploration efficiency and sustained learning capability. Experiments across multiple reasoning benchmarks demonstrate that our method enables interpretable and controllable control over the (vision-) language model's strategic behavior, thereby achieving consistent performance gains over standard RL methods.
PhysFire-WM: A Physics-Informed World Model for Emulating Fire Spread Dynamics
Dec 19, 2025



Fine-grained fire prediction plays a crucial role in emergency response. Infrared images and fire masks provide complementary thermal and boundary information, yet current methods are predominantly limited to binary mask modeling with inherent signal sparsity, failing to capture the complex dynamics of fire. While world models show promise in video generation, their physical inconsistencies pose significant challenges for fire forecasting. This paper introduces PhysFire-WM, a Physics-informed World Model for emulating Fire spread dynamics. Our approach internalizes combustion dynamics by encoding structured priors from a Physical Simulator to rectify physical discrepancies, coupled with a Cross-task Collaborative Training strategy (CC-Train) that alleviates the issue of limited information in mask-based modeling. Through parameter sharing and gradient coordination, CC-Train effectively integrates thermal radiation dynamics and spatial boundary delineation, enhancing both physical realism and geometric accuracy. Extensive experiments on a fine-grained multimodal fire dataset demonstrate the superior accuracy of PhysFire-WM in fire spread prediction. Validation underscores the importance of physical priors and cross-task collaboration, providing new insights for applying physics-informed world models to disaster prediction.
Turn-PPO: Turn-Level Advantage Estimation with PPO for Improved Multi-Turn RL in Agentic LLMs
Dec 18, 2025



Reinforcement learning (RL) has re-emerged as a natural approach for training interactive LLM agents in real-world environments. However, directly applying the widely used Group Relative Policy Optimization (GRPO) algorithm to multi-turn tasks exposes notable limitations, particularly in scenarios requiring long-horizon reasoning. To address these challenges, we investigate more stable and effective advantage estimation strategies, especially for multi-turn settings. We first explore Proximal Policy Optimization (PPO) as an alternative and find it to be more robust than GRPO. To further enhance PPO in multi-turn scenarios, we introduce turn-PPO, a variant that operates on a turn-level MDP formulation, as opposed to the commonly used token-level MDP. Our results on the WebShop and Sokoban datasets demonstrate the effectiveness of turn-PPO, both with and without long reasoning components.
In Pursuit of Pixel Supervision for Visual Pre-training
Dec 17, 2025At the most basic level, pixels are the source of the visual information through which we perceive the world. Pixels contain information at all levels, ranging from low-level attributes to high-level concepts. Autoencoders represent a classical and long-standing paradigm for learning representations from pixels or other raw inputs. In this work, we demonstrate that autoencoder-based self-supervised learning remains competitive today and can produce strong representations for downstream tasks, while remaining simple, stable, and efficient. Our model, codenamed "Pixio", is an enhanced masked autoencoder (MAE) with more challenging pre-training tasks and more capable architectures. The model is trained on 2B web-crawled images with a self-curation strategy with minimal human curation. Pixio performs competitively across a wide range of downstream tasks in the wild, including monocular depth estimation (e.g., Depth Anything), feed-forward 3D reconstruction (i.e., MapAnything), semantic segmentation, and robot learning, outperforming or matching DINOv3 trained at similar scales. Our results suggest that pixel-space self-supervised learning can serve as a promising alternative and a complement to latent-space approaches.
HyperVL: An Efficient and Dynamic Multimodal Large Language Model for Edge Devices
Dec 16, 2025



Current multimodal large lanauge models possess strong perceptual and reasoning capabilities, however high computational and memory requirements make them difficult to deploy directly on on-device environments. While small-parameter models are progressively endowed with strong general capabilities, standard Vision Transformer (ViT) encoders remain a critical bottleneck, suffering from excessive latency and memory consumption when processing high-resolution inputs.To address these challenges, we introduce HyperVL, an efficient multimodal large language model tailored for on-device inference. HyperVL adopts an image-tiling strategy to cap peak memory usage and incorporates two novel techniques: (1) a Visual Resolution Compressor (VRC) that adaptively predicts optimal encoding resolutions to eliminate redundant computation, and (2) Dual Consistency Learning (DCL), which aligns multi-scale ViT encoders within a unified framework, enabling dynamic switching between visual branches under a shared LLM. Extensive experiments demonstrate that HyperVL achieves state-of-the-art performance among models of comparable size across multiple benchmarks. Furthermore, it significantly significantly reduces latency and power consumption on real mobile devices, demonstrating its practicality for on-device multimodal inference.
HiFi-Portrait: Zero-shot Identity-preserved Portrait Generation with High-fidelity Multi-face Fusion
Dec 16, 2025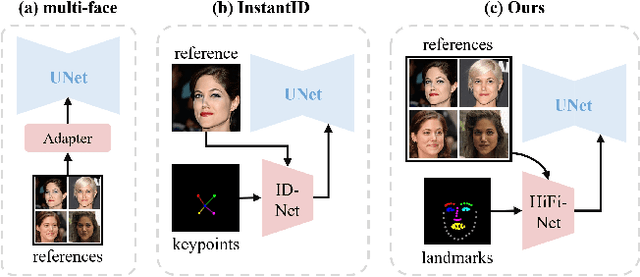
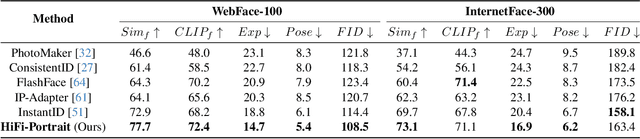


Recent advancements in diffusion-based technologies have made significant strides, particularly in identity-preserved portrait generation (IPG). However, when using multiple reference images from the same ID, existing methods typically produce lower-fidelity portraits and struggle to customize face attributes precisely. To address these issues, this paper presents HiFi-Portrait, a high-fidelity method for zero-shot portrait generation. Specifically, we first introduce the face refiner and landmark generator to obtain fine-grained multi-face features and 3D-aware face landmarks. The landmarks include the reference ID and the target attributes. Then, we design HiFi-Net to fuse multi-face features and align them with landmarks, which improves ID fidelity and face control. In addition, we devise an automated pipeline to construct an ID-based dataset for training HiFi-Portrait. Extensive experimental results demonstrate that our method surpasses the SOTA approaches in face similarity and controllability. Furthermore, our method is also compatible with previous SDXL-based works.