 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference-Free Omnidirectional Stereo Matching via Multi-View Consistency Maximization
Mar 16, 2026Reliable omnidirectional depth estimation from multi-fisheye stereo matching is pivotal to many applications, such as embodied robotics. Existing approaches either rely on spherical sweeping with heuristic fusion strategies to build the cost columns or perform reference-centric stereo matching based on rectified views. However, these methods fail to explicitly exploit geometric relationships between multiple views, rendering them less capable of capturing the global dependencies, visibility, or scale changes. In this paper, we shift to a new perspective and propose a novel reference-free framework, dubbed FreeOmniMVS, via multi-view consistency maximization. The highlight of FreeOmniMVS is that it can aggregate pair-wise correlations into a robust, visibility-aware, and global consensus. As such, it is tolerant to occlusions, partial overlaps, and varying baselines. Specifically, to achieve global coherence, we introduce a novel View-pair Correlation Transformer (VCT) that explicitly models pairwise correlation volumes across all camera view pairs, allowing us to drop unreliable pairs caused by occlusion or out-of-focus observations. To realize scalable and visibility-aware consensus, we propose a lightweight attention mechanism that adaptively fuses the correlation vectors, eliminating the need for a designated reference view and allowing all cameras to contribute equally to the stereo matching process. Extensive experiments on diverse benchmark datasets demonstrate the superiority of our method for globally consistent, visibility-aware, and scale-aware omnidirectional depth estimation.
Diff-PC: Identity-preserving and 3D-aware Controllable Diffusion for Zero-shot Portrait Customization
Jan 31, 2026Portrait customization (PC) has recently garnered significant attention due to its potential applications. However, existing PC methods lack precise identity (ID) preservation and face control. To address these tissues, we propose Diff-PC, a diffusion-based framework for zero-shot PC, which generates realistic portraits with high ID fidelity, specified facial attributes, and diverse backgrounds. Specifically, our approach employs the 3D face predictor to reconstruct the 3D-aware facial priors encompassing the reference ID, target expressions, and poses. To capture fine-grained face details, we design ID-Encoder that fuses local and global facial features. Subsequently, we devise ID-Ctrl using the 3D face to guide the alignment of ID features. We further introduce ID-Injector to enhance ID fidelity and facial controllability. Finally, training on our collected ID-centric dataset improves face similarity and text-to-image (T2I) alignment. Extensive experiments demonstrate that Diff-PC surpasses state-of-the-art methods in ID preservation, facial control, and T2I consistency. Furthermore, our method is compatible with multi-style foundation models.
FaceSnap: Enhanced ID-fidelity Network for Tuning-free Portrait Customization
Jan 31, 2026Benefiting from the significant advancements in text-to-image diffusion models, research in personalized image generation, particularly customized portrait generation, has also made great strides recently. However, existing methods either require time-consuming fine-tuning and lack generalizability or fail to achieve high fidelity in facial details. To address these issues, we propose FaceSnap, a novel method based on Stable Diffusion (SD) that requires only a single reference image and produces extremely consistent results in a single inference stage. This method is plug-and-play and can be easily extended to different SD models. Specifically, we design a new Facial Attribute Mixer that can extract comprehensive fused information from both low-level specific features and high-level abstract features, providing better guidance for image generation. We also introduce a Landmark Predictor that maintains reference identity across landmarks with different poses, providing diverse yet detailed spatial control conditions for image generation. Then we use an ID-preserving module to inject these into the UNet. Experimental results demonstrate that our approach performs remarkably in personalized and customized portrait generation, surpassing other state-of-the-art methods in this domain.
HiFi-Portrait: Zero-shot Identity-preserved Portrait Generation with High-fidelity Multi-face Fusion
Dec 16, 2025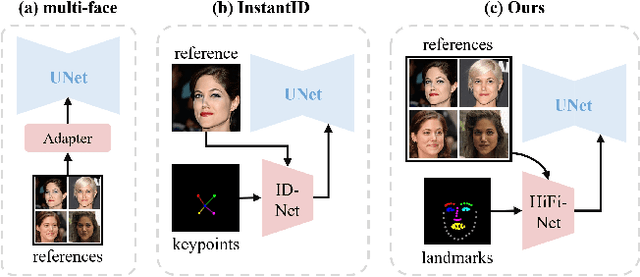
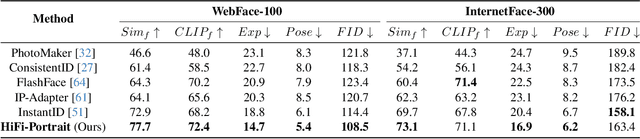


Recent advancements in diffusion-based technologies have made significant strides, particularly in identity-preserved portrait generation (IPG). However, when using multiple reference images from the same ID, existing methods typically produce lower-fidelity portraits and struggle to customize face attributes precisely. To address these issues, this paper presents HiFi-Portrait, a high-fidelity method for zero-shot portrait generation. Specifically, we first introduce the face refiner and landmark generator to obtain fine-grained multi-face features and 3D-aware face landmarks. The landmarks include the reference ID and the target attributes. Then, we design HiFi-Net to fuse multi-face features and align them with landmarks, which improves ID fidelity and face control. In addition, we devise an automated pipeline to construct an ID-based dataset for training HiFi-Portrait. Extensive experimental results demonstrate that our method surpasses the SOTA approaches in face similarity and controllability. Furthermore, our method is also compatible with previous SDXL-based works.
Uni-Inter: Unifying 3D Human Motion Synthesis Across Diverse Interaction Contexts
Nov 17, 2025We present Uni-Inter, a unified framework for human motion generation that supports a wide range of interaction scenarios: including human-human, human-object, and human-scene-within a single, task-agnostic architecture. In contrast to existing methods that rely on task-specific designs and exhibit limited generalization, Uni-Inter introduces the Unified Interactive Volume (UIV), a volumetric representation that encodes heterogeneous interactive entities into a shared spatial field. This enables consistent relational reasoning and compound interaction modeling. Motion generation is formulated as joint-wise probabilistic prediction over the UIV, allowing the model to capture fine-grained spatial dependencies and produce coherent, context-aware behaviors. Experiments across three representative interaction tasks demonstrate that Uni-Inter achieves competitive performance and generalizes well to novel combinations of entities. These results suggest that unified modeling of compound interactions offers a promising direction for scalable motion synthesis in complex environments.
Free3D: 3D Human Motion Emerges from Single-View 2D Supervision
Nov 14, 2025Recent 3D human motion generation models demonstrate remarkable reconstruction accuracy yet struggle to generalize beyond training distributions. This limitation arises partly from the use of precise 3D supervision, which encourages models to fit fixed coordinate patterns instead of learning the essential 3D structure and motion semantic cues required for robust generalization.To overcome this limitation, we propose Free3D, a framework that synthesizes realistic 3D motions without any 3D motion annotations. Free3D introduces a Motion-Lifting Residual Quantized VAE (ML-RQ) that maps 2D motion sequences into 3D-consistent latent spaces, and a suite of 3D-free regularization objectives enforcing view consistency, orientation coherence, and physical plausibility. Trained entirely on 2D motion data, Free3D generates diverse, temporally coherent, and semantically aligned 3D motions, achieving performance comparable to or even surpassing fully 3D-supervised counterparts. These results suggest that relaxing explicit 3D supervision encourages stronger structural reasoning and generalization, offering a scalable and data-efficient paradigm for 3D motion generation.
Multi-modal Fusion and Query Refinement Network for Video Moment Retrieval and Highlight Detection
Jan 18, 2025



Given a video and a linguistic query, video moment retrieval and highlight detection (MR&HD) aim to locate all the relevant spans while simultaneously predicting saliency scores. Most existing methods utilize RGB images as input, overlooking the inherent multi-modal visual signals like optical flow and depth. In this paper, we propose a Multi-modal Fusion and Query Refinement Network (MRNet) to learn complementary information from multi-modal cues. Specifically, we design a multi-modal fusion module to dynamically combine RGB, optical flow, and depth map. Furthermore, to simulate human understanding of sentences, we introduce a query refinement module that merges text at different granularities, containing word-, phrase-, and sentence-wise levels. Comprehensive experiments on QVHighlights and Charades datasets indicate that MRNet outperforms current state-of-the-art methods, achieving notable improvements in MR-mAP@Avg (+3.41) and HD-HIT@1 (+3.46) on QVHighlights.
Zero-shot Video Moment Retrieval via Off-the-shelf Multimodal Large Language Models
Jan 14, 2025



The target of video moment retrieval (VMR) is predicting temporal spans within a video that semantically match a given linguistic query. Existing VMR methods based on multimodal large language models (MLLMs) overly rely on expensive high-quality datasets and time-consuming fine-tuning. Although some recent studies introduce a zero-shot setting to avoid fine-tuning, they overlook inherent language bias in the query, leading to erroneous localization. To tackle the aforementioned challenges, this paper proposes Moment-GPT, a tuning-free pipeline for zero-shot VMR utilizing frozen MLLMs. Specifically, we first employ LLaMA-3 to correct and rephrase the query to mitigate language bias. Subsequently, we design a span generator combined with MiniGPT-v2 to produce candidate spans adaptively. Finally, to leverage the video comprehension capabilities of MLLMs, we apply VideoChatGPT and span scorer to select the most appropriate spans. Our proposed method substantially outperforms the state-ofthe-art MLLM-based and zero-shot models on several public datasets, including QVHighlights, ActivityNet-Captions, and Charades-STA.
Real-time Multi-view Omnidirectional Depth Estimation System for Robots and Autonomous Driving on Real Scenes
Sep 12, 2024



Omnidirectional Depth Estimation has broad application prospects in fields such as robotic navigation and autonomous driving. In this paper, we propose a robotic prototype system and corresponding algorithm designed to validate omnidirectional depth estimation for navigation and obstacle avoidance in real-world scenarios for both robots and vehicles. The proposed HexaMODE system captures 360$^\circ$ depth maps using six surrounding arranged fisheye cameras. We introduce a combined spherical sweeping method and optimize the model architecture for proposed RtHexa-OmniMVS algorithm to achieve real-time omnidirectional depth estimation. To ensure high accuracy, robustness, and generalization in real-world environments, we employ a teacher-student self-training strategy, utilizing large-scale unlabeled real-world data for model training. The proposed algorithm demonstrates high accuracy in various complex real-world scenarios, both indoors and outdoors, achieving an inference speed of 15 fps on edge computing platforms.
GPTSee: Enhancing Moment Retrieval and Highlight Detection via Description-Based Similarity Features
Mar 10, 2024



Moment retrieval (MR) and highlight detection (HD) aim to identify relevant moments and highlights in video from corresponding natural language query. Large language models (LLMs) have demonstrated proficiency in various computer vision tasks. However, existing methods for MR\&HD have not yet been integrated with LLMs. In this letter, we propose a novel two-stage model that takes the output of LLMs as the input to the second-stage transformer encoder-decoder. First, MiniGPT-4 is employed to generate the detailed description of the video frame and rewrite the query statement, fed into the encoder as new features. Then, semantic similarity is computed between the generated description and the rewritten queries. Finally, continuous high-similarity video frames are converted into span anchors, serving as prior position information for the decoder. Experiments demonstrate that our approach achieves a state-of-the-art result, and by using only span anchors and similarity scores as outputs, positioning accuracy outperforms traditional methods, like Moment-DETR.