 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraShape 1.0: High-Fidelity 3D Shape Generation via Scalable Geometric Refinement
Dec 24, 2025In this report, we introduce UltraShape 1.0, a scalable 3D diffusion framework for high-fidelity 3D geometry generation. The proposed approach adopts a two-stage generation pipeline: a coarse global structure is first synthesized and then refined to produce detailed, high-quality geometry. To support reliable 3D generation, we develop a comprehensive data processing pipeline that includes a novel watertight processing method and high-quality data filtering. This pipeline improves the geometric quality of publicly available 3D datasets by removing low-quality samples, filling holes, and thickening thin structures, while preserving fine-grained geometric details. To enable fine-grained geometry refinement, we decouple spatial localization from geometric detail synthesis in the diffusion process. We achieve this by performing voxel-based refinement at fixed spatial locations, where voxel queries derived from coarse geometry provide explicit positional anchors encoded via RoPE, allowing the diffusion model to focus on synthesizing local geometric details within a reduced, structured solution space. Our model is trained exclusively on publicly available 3D datasets, achieving strong geometric quality despite limited training resources. Extensive evaluations demonstrate that UltraShape 1.0 performs competitively with existing open-source methods in both data processing quality and geometry generation. All code and trained models will be released to support future research.
Large Material Gaussian Model for Relightable 3D Generation
Sep 26, 2025
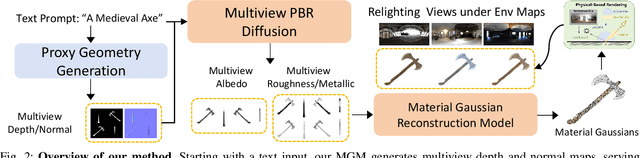
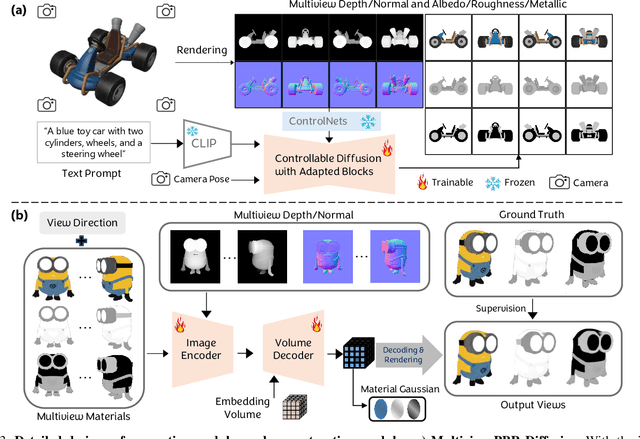

The increasing demand for 3D assets across various industries necessitates efficient and automated methods for 3D content creation. Leveraging 3D Gaussian Splatting, recent large reconstruction models (LRMs) have demonstrated the ability to efficiently achieve high-quality 3D rendering by integrating multiview diffusion for generation and scalable transformers for reconstruction. However, existing models fail to produce the material properties of assets, which is crucial for realistic rendering in diverse lighting environments. In this paper, we introduce the Large Material Gaussian Model (MGM), a novel framework designed to generate high-quality 3D content with Physically Based Rendering (PBR) materials, ie, albedo, roughness, and metallic properties, rather than merely producing RGB textures with uncontrolled light baking. Specifically, we first fine-tune a new multiview material diffusion model conditioned on input depth and normal maps. Utilizing the generated multiview PBR images, we explore a Gaussian material representation that not only aligns with 2D Gaussian Splatting but also models each channel of the PBR materials. The reconstructed point clouds can then be rendered to acquire PBR attributes, enabling dynamic relighting by applying various ambient light maps. Extensive experiments demonstrate that the materials produced by our method not only exhibit greater visual appeal compared to baseline methods but also enhance material modeling, thereby enabling practical downstream rendering applications.
AssetDropper: Asset Extraction via Diffusion Models with Reward-Driven Optimization
Jun 06, 2025Recent research on generative models has primarily focused on creating product-ready visual outputs; however, designers often favor access to standardized asset libraries, a domain that has yet to be significantly enhanced by generative capabilities. Although open-world scenes provide ample raw materials for designers, efficiently extracting high-quality, standardized assets remains a challenge. To address this, we introduce AssetDropper, the first framework designed to extract assets from reference images, providing artists with an open-world asset palette. Our model adeptly extracts a front view of selected subjects from input images, effectively handling complex scenarios such as perspective distortion and subject occlusion. We establish a synthetic dataset of more than 200,000 image-subject pairs and a real-world benchmark with thousands more for evaluation, facilitating the exploration of future research in downstream tasks. Furthermore, to ensure precise asset extraction that aligns well with the image prompts, we employ a pre-trained reward model to fulfill a closed-loop with feedback. We design the reward model to perform an inverse task that pastes the extracted assets back into the reference sources, which assists training with additional consistency and mitigates hallucination. Extensive experiments show that, with the aid of reward-driven optimization, AssetDropper achieves the state-of-the-art results in asset extraction. Project page: AssetDropper.github.io.
GarmentX: Autoregressive Parametric Representations for High-Fidelity 3D Garment Generation
Apr 29, 2025This work presents GarmentX, a novel framework for generating diverse, high-fidelity, and wearable 3D garments from a single input image. Traditional garment reconstruction methods directly predict 2D pattern edges and their connectivity, an overly unconstrained approach that often leads to severe self-intersections and physically implausible garment structures. In contrast, GarmentX introduces a structured and editable parametric representation compatible with GarmentCode, ensuring that the decoded sewing patterns always form valid, simulation-ready 3D garments while allowing for intuitive modifications of garment shape and style. To achieve this, we employ a masked autoregressive model that sequentially predicts garment parameters, leveraging autoregressive modeling for structured generation while mitigating inconsistencies in direct pattern prediction. Additionally, we introduce GarmentX dataset, a large-scale dataset of 378,682 garment parameter-image pairs, constructed through an automatic data generation pipeline that synthesizes diverse and high-quality garment images conditioned on parametric garment representations. Through integrating our method with GarmentX dataset, we achieve state-of-the-art performance in geometric fidelity and input image alignment, significantly outperforming prior approaches. We will release GarmentX dataset upon publication.
MagicScroll: Nontypical Aspect-Ratio Image Generation for Visual Storytelling via Multi-Layered Semantic-Aware Denoising
Dec 18, 2023Visual storytelling often uses nontypical aspect-ratio images like scroll paintings, comic strips, and panoramas to create an expressive and compelling narrative. While generative AI has achieved great success and shown the potential to reshape the creative industry, it remains a challenge to generate coherent and engaging content with arbitrary size and controllable style, concept, and layout, all of which are essential for visual storytelling. To overcome the shortcomings of previous methods including repetitive content, style inconsistency, and lack of controllability, we propose MagicScroll, a multi-layered, progressive diffusion-based image generation framework with a novel semantic-aware denoising process. The model enables fine-grained control over the generated image on object, scene, and background levels with text, image, and layout conditions. We also establish the first benchmark for nontypical aspect-ratio image generation for visual storytelling including mediums like paintings, comics, and cinematic panoramas, with customized metrics for systematic evaluation. Through comparative and ablation studies, MagicScroll showcases promising results in aligning with the narrative text, improving visual coherence, and engaging the audience. We plan to release the code and benchmark in the hope of a better collaboration between AI researchers and creative practitioners involving visual storytelling.