 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEPT: Standard-Definition Map Enhanced Scene Perception and Topology Reasoning for Autonomous Driving
May 18, 2025



Online scene perception and topology reasoning are critical for autonomous vehicles to understand their driving environments, particularly for mapless driving systems that endeavor to reduce reliance on costly High-Definition (HD) maps. However, recent advances in online scene understanding still face limitations, especially in long-range or occluded scenarios, due to the inherent constraints of onboard sensors. To address this challenge, we propose a Standard-Definition (SD) Map Enhanced scene Perception and Topology reasoning (SEPT) framework, which explores how to effectively incorporate the SD map as prior knowledge into existing perception and reasoning pipelines. Specifically, we introduce a novel hybrid feature fusion strategy that combines SD maps with Bird's-Eye-View (BEV) features, considering both rasterized and vectorized representations, while mitigating potential misalignment between SD maps and BEV feature spaces. Additionally, we leverage the SD map characteristics to design an auxiliary intersection-aware keypoint detection task, which further enhances the overall scene understanding performance. Experimental results on the large-scale OpenLane-V2 dataset demonstrate that by effectively integrating SD map priors, our framework significantly improves both scene perception and topology reasoning, outperforming existing methods by a substantial margin.
OneTwoVLA: A Unified Vision-Language-Action Model with Adaptive Reasoning
May 17, 2025General-purpose robots capable of performing diverse tasks require synergistic reasoning and acting capabilities. However, recent dual-system approaches, which separate high-level reasoning from low-level acting, often suffer from challenges such as limited mutual understanding of capabilities between systems and latency issues. This paper introduces OneTwoVLA, a single unified vision-language-action model that can perform both acting (System One) and reasoning (System Two). Crucially, OneTwoVLA adaptively switches between two modes: explicitly reasoning at critical moments during task execution, and generating actions based on the most recent reasoning at other times. To further unlock OneTwoVLA's reasoning and generalization capabilities, we design a scalable pipeline for synthesizing embodied reasoning-centric vision-language data, used for co-training with robot data. We validate OneTwoVLA's effectiveness through extensive experiments, highlighting its superior performance across four key capabilities: long-horizon task planning, error detection and recovery, natural human-robot interaction, and generalizable visual grounding, enabling the model to perform long-horizon, highly dexterous manipulation tasks such as making hotpot or mixing cocktails.
SoLoPO: Unlocking Long-Context Capabilities in LLMs via Short-to-Long Preference Optimization
May 16, 2025Despite advances in pretraining with extended context lengths, large language models (LLMs) still face challenges in effectively utilizing real-world long-context information, primarily due to insufficient long-context alignment caused by data quality issues, training inefficiencies, and the lack of well-designed optimization objectives. To address these limitations, we propose a framework named $\textbf{S}$h$\textbf{o}$rt-to-$\textbf{Lo}$ng $\textbf{P}$reference $\textbf{O}$ptimization ($\textbf{SoLoPO}$), decoupling long-context preference optimization (PO) into two components: short-context PO and short-to-long reward alignment (SoLo-RA), supported by both theoretical and empirical evidence. Specifically, short-context PO leverages preference pairs sampled from short contexts to enhance the model's contextual knowledge utilization ability. Meanwhile, SoLo-RA explicitly encourages reward score consistency utilization for the responses when conditioned on both short and long contexts that contain identical task-relevant information. This facilitates transferring the model's ability to handle short contexts into long-context scenarios. SoLoPO is compatible with mainstream preference optimization algorithms, while substantially improving the efficiency of data construction and training processes. Experimental results show that SoLoPO enhances all these algorithms with respect to stronger length and domain generalization abilities across various long-context benchmarks, while achieving notable improvements in both computational and memory efficiency.
Highly Undersampled MRI Reconstruction via a Single Posterior Sampling of Diffusion Models
May 13, 2025Incoherent k-space under-sampling and deep learning-based reconstruction methods have shown great success in accelerating MRI. However, the performance of most previous methods will degrade dramatically under high acceleration factors, e.g., 8$\times$ or higher. Recently, denoising diffusion models (DM) have demonstrated promising results in solving this issue; however, one major drawback of the DM methods is the long inference time due to a dramatic number of iterative reverse posterior sampling steps. In this work, a Single Step Diffusion Model-based reconstruction framework, namely SSDM-MRI, is proposed for restoring MRI images from highly undersampled k-space. The proposed method achieves one-step reconstruction by first training a conditional DM and then iteratively distilling this model. Comprehensive experiments were conducted on both publicly available fastMRI images and an in-house multi-echo GRE (QSM) subject. Overall, the results showed that SSDM-MRI outperformed other methods in terms of numerical metrics (PSNR and SSIM), qualitative error maps, image fine details, and latent susceptibility information hidden in MRI phase images. In addition, the reconstruction time for a 320*320 brain slice of SSDM-MRI is only 0.45 second, which is only comparable to that of a simple U-net, making it a highly effective solution for MRI reconstruction tasks.
HuB: Learning Extreme Humanoid Balance
May 12, 2025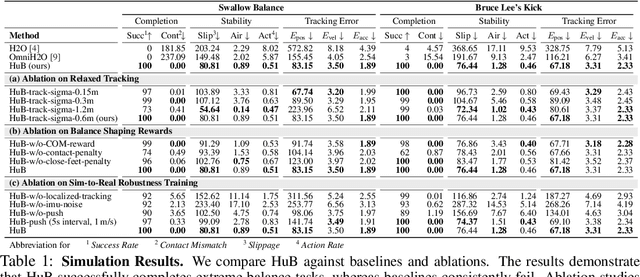
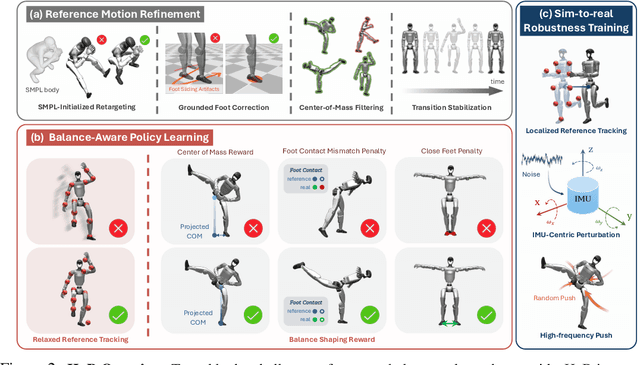
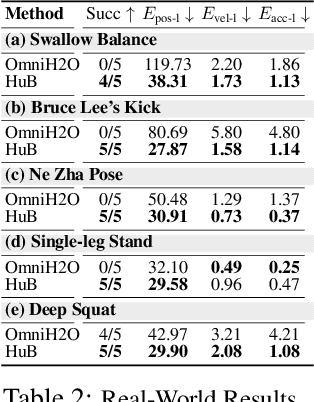
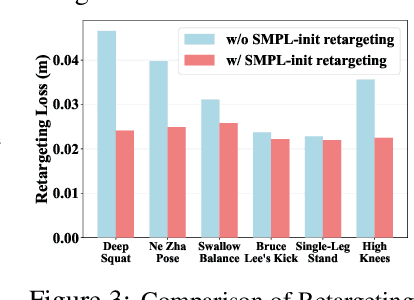
The human body demonstrates exceptional motor capabilities-such as standing steadily on one foot or performing a high kick with the leg raised over 1.5 meters-both requiring precise balance control. While recent research on humanoid control has leveraged reinforcement learning to track human motions for skill acquisition, applying this paradigm to balance-intensive tasks remains challenging. In this work, we identify three key obstacles: instability from reference motion errors, learning difficulties due to morphological mismatch, and the sim-to-real gap caused by sensor noise and unmodeled dynamics. To address these challenges, we propose HuB (Humanoid Balance), a unified framework that integrates reference motion refinement, balance-aware policy learning, and sim-to-real robustness training, with each component targeting a specific challenge. We validate our approach on the Unitree G1 humanoid robot across challenging quasi-static balance tasks, including extreme single-legged poses such as Swallow Balance and Bruce Lee's Kick. Our policy remains stable even under strong physical disturbances-such as a forceful soccer strike-while baseline methods consistently fail to complete these tasks. Project website: https://hub-robot.github.io
FACET: Force-Adaptive Control via Impedance Reference Tracking for Legged Robots
May 11, 2025Reinforcement learning (RL) has made significant strides in legged robot control, enabling locomotion across diverse terrains and complex loco-manipulation capabilities. However, the commonly used position or velocity tracking-based objectives are agnostic to forces experienced by the robot, leading to stiff and potentially dangerous behaviors and poor control during forceful interactions. To address this limitation, we present \emph{Force-Adaptive Control via Impedance Reference Tracking} (FACET). Inspired by impedance control, we use RL to train a control policy to imitate a virtual mass-spring-damper system, allowing fine-grained control under external forces by manipulating the virtual spring. In simulation, we demonstrate that our quadruped robot achieves improved robustness to large impulses (up to 200 Ns) and exhibits controllable compliance, achieving an 80% reduction in collision impulse. The policy is deployed to a physical robot to showcase both compliance and the ability to engage with large forces by kinesthetic control and pulling payloads up to 2/3 of its weight. Further extension to a legged loco-manipulator and a humanoid shows the applicability of our method to more complex settings to enable whole-body compliance control. Project Website: https://egalahad.github.io/facet/
Advancing Conversational Diagnostic AI with Multimodal Reasoning
May 06, 2025



Large Language Models (LLMs) have demonstrated great potential for conducting diagnostic conversations but evaluation has been largely limited to language-only interactions, deviating from the real-world requirements of remote care delivery. Instant messaging platforms permit clinicians and patients to upload and discuss multimodal medical artifacts seamlessly in medical consultation, but the ability of LLMs to reason over such data while preserving other attributes of competent diagnostic conversation remains unknown. Here we advance the conversational diagnosis and management performance of the Articulate Medical Intelligence Explorer (AMIE) through a new capability to gather and interpret multimodal data, and reason about this precisely during consultations. Leveraging Gemini 2.0 Flash, our system implements a state-aware dialogue framework, where conversation flow is dynamically controlled by intermediate model outputs reflecting patient states and evolving diagnoses. Follow-up questions are strategically directed by uncertainty in such patient states, leading to a more structured multimodal history-taking process that emulates experienced clinicians. We compared AMIE to primary care physicians (PCPs) in a randomized, blinded, OSCE-style study of chat-based consultations with patient actors. We constructed 105 evaluation scenarios using artifacts like smartphone skin photos, ECGs, and PDFs of clinical documents across diverse conditions and demographics. Our rubric assessed multimodal capabilities and other clinically meaningful axes like history-taking, diagnostic accuracy, management reasoning, communication, and empathy. Specialist evaluation showed AMIE to be superior to PCPs on 7/9 multimodal and 29/32 non-multimodal axes (including diagnostic accuracy). The results show clear progress in multimodal conversational diagnostic AI, but real-world translation needs further research.
KineDex: Learning Tactile-Informed Visuomotor Policies via Kinesthetic Teaching for Dexterous Manipulation
May 04, 2025



Collecting demonstrations enriched with fine-grained tactile information is critical for dexterous manipulation, particularly in contact-rich tasks that require precise force control and physical interaction. While prior works primarily focus on teleoperation or video-based retargeting, they often suffer from kinematic mismatches and the absence of real-time tactile feedback, hindering the acquisition of high-fidelity tactile data. To mitigate this issue, we propose KineDex, a hand-over-hand kinesthetic teaching paradigm in which the operator's motion is directly transferred to the dexterous hand, enabling the collection of physically grounded demonstrations enriched with accurate tactile feedback. To resolve occlusions from human hand, we apply inpainting technique to preprocess the visual observations. Based on these demonstrations, we then train a visuomotor policy using tactile-augmented inputs and implement force control during deployment for precise contact-rich manipulation. We evaluate KineDex on a suite of challenging contact-rich manipulation tasks, including particularly difficult scenarios such as squeezing toothpaste onto a toothbrush, which require precise multi-finger coordination and stable force regulation. Across these tasks, KineDex achieves an average success rate of 74.4%, representing a 57.7% improvement over the variant without force control. Comparative experiments with teleoperation and user studies further validate the advantages of KineDex in data collection efficiency and operability. Specifically, KineDex collects data over twice as fast as teleoperation across two tasks of varying difficulty, while maintaining a near-100% success rate, compared to under 50% for teleoperation.
DeCo: Task Decomposition and Skill Composition for Zero-Shot Generalization in Long-Horizon 3D Manipulation
May 01, 2025Generalizing language-conditioned multi-task imitation learning (IL) models to novel long-horizon 3D manipulation tasks remains a significant challenge. To address this, we propose DeCo (Task Decomposition and Skill Composition), a model-agnostic framework compatible with various multi-task IL models, designed to enhance their zero-shot generalization to novel, compositional, long-horizon 3D manipulation tasks. DeCo first decomposes IL demonstrations into a set of modular atomic tasks based on the physical interaction between the gripper and objects, and constructs an atomic training dataset that enables models to learn a diverse set of reusable atomic skills during imitation learning. At inference time, DeCo leverages a vision-language model (VLM) to parse high-level instructions for novel long-horizon tasks, retrieve the relevant atomic skills, and dynamically schedule their execution; a spatially-aware skill-chaining module then ensures smooth, collision-free transitions between sequential skills. We evaluate DeCo in simulation using DeCoBench, a benchmark specifically designed to assess zero-shot generalization of multi-task IL models in compositional long-horizon 3D manipulation. Across three representative multi-task IL models (RVT-2, 3DDA, and ARP), DeCo achieves success rate improvements of 66.67%, 21.53%, and 57.92%, respectively, on 12 novel compositional tasks. Moreover, in real-world experiments, a DeCo-enhanced model trained on only 6 atomic tasks successfully completes 9 novel long-horizon tasks, yielding an average success rate improvement of 53.33% over the base multi-task IL model. Video demonstrations are available at: https://deco226.github.io.
Adapting In-Domain Few-Shot Segmentation to New Domains without Retraining
Apr 30, 2025



Cross-domain few-shot segmentation (CD-FSS) aims to segment objects of novel classes in new domains, which is often challenging due to the diverse characteristics of target domains and the limited availability of support data. Most CD-FSS methods redesign and retrain in-domain FSS models using various domain-generalization techniques, which are effective but costly to train. To address these issues, we propose adapting informative model structures of the well-trained FSS model for target domains by learning domain characteristics from few-shot labeled support samples during inference, thereby eliminating the need for retraining. Specifically, we first adaptively identify domain-specific model structures by measuring parameter importance using a novel structure Fisher score in a data-dependent manner. Then, we progressively train the selected informative model structures with hierarchically constructed training samples, progressing from fewer to more support shots. The resulting Informative Structure Adaptation (ISA) method effectively addresses domain shifts and equips existing well-trained in-domain FSS models with flexible adaptation capabilities for new domains, eliminating the need to redesign or retrain CD-FSS models on base data. Extensive experiments validate the effectiveness of our method, demonstrating superior performance across multiple CD-FSS benchmarks.