 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenHLM: An Empirical Recipe for Whole-Body Humanoid Loco-Manipulation
Jun 20, 2026Whole-body humanoid loco-manipulation requires coordinating the robot's entire kinematic chain. However, most existing systems typically decouple the upper and lower bodies into separate controllers, limiting such coordination and yielding behaviors similar to those of a wheeled dual-arm platform. In this paper, we ask what it takes to build a whole-body native vision-language-action (VLA) model that maps language and pixels directly to all of the humanoid's degrees of freedom. We conduct a systematic empirical study organized as a roadmap of one-variable-at-a-time experiments across three phases: whole-body teleoperation, VLA model design, and heterogeneous co-training. Our study yields several intriguing findings: a joint-based whole-body teleoperation interface outperforms alternatives that only partially expose the humanoid's degrees of freedom; a VLA pretrained on static and wheeled dual-arm platforms transfers surprisingly well to a humanoid's full action space; and co-training with HuMI, the humanoid analog of UMI, extends the policy to new objects and instructions without additional whole-body teleoperation on those targets. Following this roadmap yields OpenHLM, an open-source recipe for whole-body humanoid loco-manipulation. In a challenging long-horizon task that spans a wide vertical range of the humanoid, OpenHLM outperforms two state-of-the-art humanoid VLA baselines (GR00T N1.6 and $Ψ_0$) using less than half the total demonstration time. Our code, training data, and model checkpoints are available at [https://openhlm-project.github.io/].
Humanoid Manipulation Interface: Humanoid Whole-Body Manipulation from Robot-Free Demonstrations
Feb 06, 2026Current approaches for humanoid whole-body manipulation, primarily relying on teleoperation or visual sim-to-real reinforcement learning, are hindered by hardware logistics and complex reward engineering. Consequently, demonstrated autonomous skills remain limited and are typically restricted to controlled environments. In this paper, we present the Humanoid Manipulation Interface (HuMI), a portable and efficient framework for learning diverse whole-body manipulation tasks across various environments. HuMI enables robot-free data collection by capturing rich whole-body motion using portable hardware. This data drives a hierarchical learning pipeline that translates human motions into dexterous and feasible humanoid skills. Extensive experiments across five whole-body tasks--including kneeling, squatting, tossing, walking, and bimanual manipulation--demonstrate that HuMI achieves a 3x increase in data collection efficiency compared to teleoperation and attains a 70% success rate in unseen environments.
OneTwoVLA: A Unified Vision-Language-Action Model with Adaptive Reasoning
May 17, 2025General-purpose robots capable of performing diverse tasks require synergistic reasoning and acting capabilities. However, recent dual-system approaches, which separate high-level reasoning from low-level acting, often suffer from challenges such as limited mutual understanding of capabilities between systems and latency issues. This paper introduces OneTwoVLA, a single unified vision-language-action model that can perform both acting (System One) and reasoning (System Two). Crucially, OneTwoVLA adaptively switches between two modes: explicitly reasoning at critical moments during task execution, and generating actions based on the most recent reasoning at other times. To further unlock OneTwoVLA's reasoning and generalization capabilities, we design a scalable pipeline for synthesizing embodied reasoning-centric vision-language data, used for co-training with robot data. We validate OneTwoVLA's effectiveness through extensive experiments, highlighting its superior performance across four key capabilities: long-horizon task planning, error detection and recovery, natural human-robot interaction, and generalizable visual grounding, enabling the model to perform long-horizon, highly dexterous manipulation tasks such as making hotpot or mixing cocktails.
HuB: Learning Extreme Humanoid Balance
May 12, 2025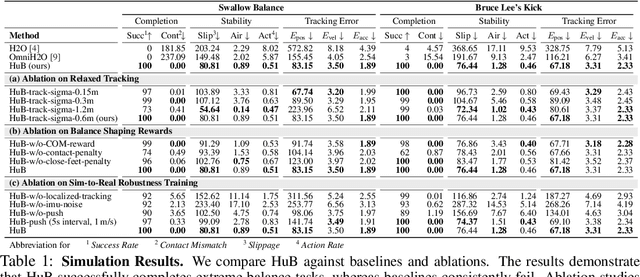
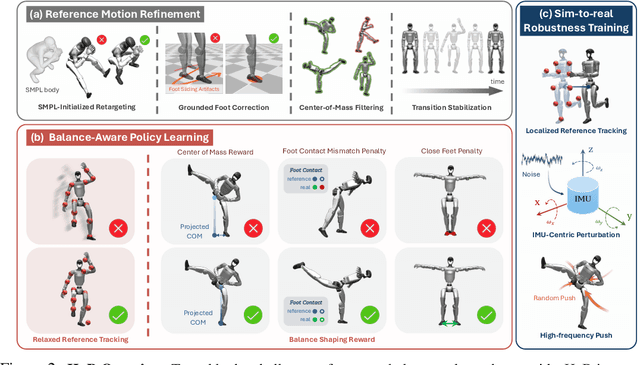
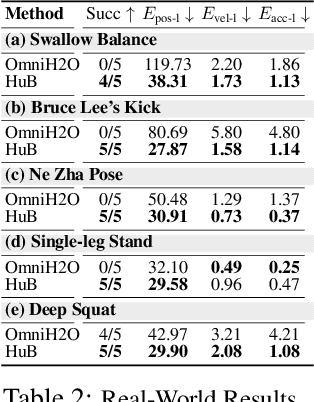
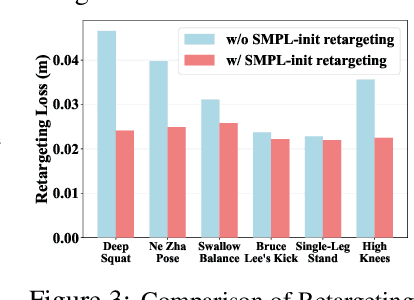
The human body demonstrates exceptional motor capabilities-such as standing steadily on one foot or performing a high kick with the leg raised over 1.5 meters-both requiring precise balance control. While recent research on humanoid control has leveraged reinforcement learning to track human motions for skill acquisition, applying this paradigm to balance-intensive tasks remains challenging. In this work, we identify three key obstacles: instability from reference motion errors, learning difficulties due to morphological mismatch, and the sim-to-real gap caused by sensor noise and unmodeled dynamics. To address these challenges, we propose HuB (Humanoid Balance), a unified framework that integrates reference motion refinement, balance-aware policy learning, and sim-to-real robustness training, with each component targeting a specific challenge. We validate our approach on the Unitree G1 humanoid robot across challenging quasi-static balance tasks, including extreme single-legged poses such as Swallow Balance and Bruce Lee's Kick. Our policy remains stable even under strong physical disturbances-such as a forceful soccer strike-while baseline methods consistently fail to complete these tasks. Project website: https://hub-robot.github.io
Revisiting Disentanglement in Downstream Tasks: A Study on Its Necessity for Abstract Visual Reasoning
Mar 01, 2024



In representation learning, a disentangled representation is highly desirable as it encodes generative factors of data in a separable and compact pattern. Researchers have advocated leveraging disentangled representations to complete downstream tasks with encouraging empirical evidence. This paper further investigates the necessity of disentangled representation in downstream applications. Specifically, we show that dimension-wise disentangled representations are unnecessary on a fundamental downstream task, abstract visual reasoning. We provide extensive empirical evidence against the necessity of disentanglement, covering multiple datasets, representation learning methods, and downstream network architectures. Furthermore, our findings suggest that the informativeness of representations is a better indicator of downstream performance than disentanglement. Finally, the positive correlation between informativeness and disentanglement explains the claimed usefulness of disentangled representations in previous works. The source code is available at https://github.com/Richard-coder-Nai/disentanglement-lib-necessity.git.
An Empirical Study on Disentanglement of Negative-free Contrastive Learning
Jun 09, 2022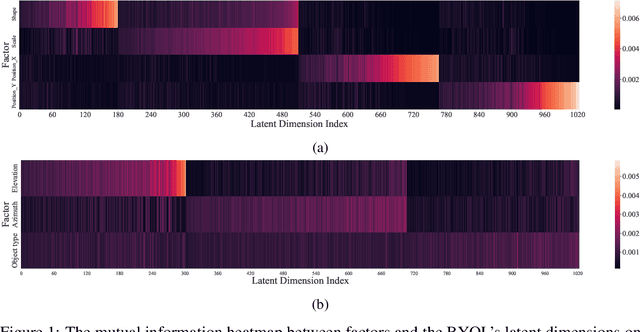

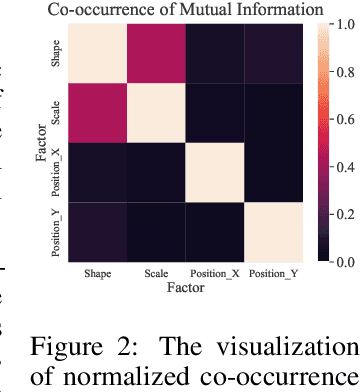

Negative-free contrastive learning has attracted a lot of attention with simplicity and impressive performance for large-scale pretraining. But its disentanglement property remains unexplored. In this paper, we take different negative-free contrastive learning methods to study the disentanglement property of this genre of self-supervised methods empirically. We find the existing disentanglement metrics fail to make meaningful measurements for the high-dimensional representation model so we propose a new disentanglement metric based on Mutual Information between representation and data factors. With the proposed metric, we benchmark the disentanglement property of negative-free contrastive learning for the first time, on both popular synthetic datasets and a real-world dataset CelebA. Our study shows that the investigated methods can learn a well-disentangled subset of representation. We extend the study of the disentangled representation learning to high-dimensional representation space and negative-free contrastive learning for the first time. The implementation of the proposed metric is available at \url{https://github.com/noahcao/disentanglement_lib_med}.
Real Additive Margin Softmax for Speaker Verification
Oct 18, 2021

The additive margin softmax (AM-Softmax) loss has delivered remarkable performance in speaker verification. A supposed behavior of AM-Softmax is that it can shrink within-class variation by putting emphasis on target logits, which in turn improves margin between target and non-target classes. In this paper, we conduct a careful analysis on the behavior of AM-Softmax loss, and show that this loss does not implement real max-margin training. Based on this observation, we present a Real AM-Softmax loss which involves a true margin function in the softmax training. Experiments conducted on VoxCeleb1, SITW and CNCeleb demonstrated that the corrected AM-Softmax loss consistently outperforms the original one. The code has been released at https://gitlab.com/csltstu/sunine.