 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Conversational Medical AI with Eyes, Ears and a Voice
May 10, 2026The practice of medicine relies not only upon skillful dialogue but also on the nuanced exchange and interpretation of rich auditory and visual cues between doctors and patients. Building on the low-latency voice and video processing capabilities of Gemini, we introduce AI co-clinician, a first-of-its-kind conversational AI system utilizing continuous streams of audio-visual data from live patient conversations to inform real-time clinical decisions. Its dual-agent architecture balances deep clinical reasoning with the low latency required for natural dialogue. To assess this system, we implemented a video-based interface emulating telemedicine consultations. We crafted 20 standardized outpatient scenarios requiring proactive real-time auditory and visual reasoning and designed "TelePACES" evaluation criteria alongside case-specific rubrics. In a randomized, interface-blinded, crossover simulation study (n = 120 encounters) with 10 internal medicine residents as patient actors, we compared AI co-clinician with primary care physicians (PCPs), GPT-Realtime, and a baseline agent. AI co-clinician approached PCPs in key TelePACES dimensions, including management plans and differential diagnosis, while significantly outperforming GPT-Realtime across all general criteria. While our agent demonstrated parity with PCPs in case-specific triage measures, physicians maintained superior overall performance in case-specific assessments. Although AI co-clinician marks a significant advance in real-time telemedical AI, gaps remain in physical examination and disease-specific reasoning. Our work shows that text-only approaches fail to capture the true challenges of medical consultation and suggests that high-stakes real-time diagnostic AI is most safely advanced in collaborative, triadic models where AI can be a supportive co-clinician for doctors and patients.
CoDaS: AI Co-Data-Scientist for Biomarker Discovery via Wearable Sensors
Apr 16, 2026Scientific discovery in digital health requires converting continuous physiological signals from wearable devices into clinically actionable biomarkers. We introduce CoDaS (AI Co-Data-Scientist), a multi-agent system that structures biomarker discovery as an iterative process combining hypothesis generation, statistical analysis, adversarial validation, and literature-grounded reasoning with human oversight using large-scale wearable datasets. Across three cohorts totaling 9,279 participant-observations, CoDaS identified 41 candidate digital biomarkers for mental health and 25 for metabolic outcomes, each subjected to an internal validation battery spanning replication, stability, robustness, and discriminative power. Across two independent depression cohorts, CoDaS surfaced circadian instability-related features in both datasets, reflected in sleep duration variability (DWB, ρ= 0.252, p < 0.001) and sleep onset variability (GLOBEM, ρ= 0.126, p < 0.001). In a metabolic cohort, CoDaS derived a cardiovascular fitness index (steps/resting heart rate; ρ= -0.374, p < 0.001), and recovered established clinical associations, including the hepatic function ratio (AST/ALT; ρ= -0.375, p < 0.001), a known correlate of insulin resistance. Incorporating CoDaS-derived features alongside demographic variables led to modest but consistent improvements in predictive performance, with cross-validated ΔR^2 increases of 0.040 for depression and 0.021 for insulin resistance. These findings suggest that CoDaS enables systematic and traceable hypothesis generation and prioritization for biomarker discovery from large-scale wearable data.
MedGemma 1.5 Technical Report
Apr 06, 2026We introduce MedGemma 1.5 4B, the latest model in the MedGemma collection. MedGemma 1.5 expands on MedGemma 1 by integrating additional capabilities: high-dimensional medical imaging (CT/MRI volumes and histopathology whole slide images), anatomical localization via bounding boxes, multi-timepoint chest X-ray analysis, and improved medical document understanding (lab reports, electronic health records). We detail the innovations required to enable these modalities within a single architecture, including new training data, long-context 3D volume slicing, and whole-slide pathology sampling. Compared to MedGemma 1 4B, MedGemma 1.5 4B demonstrates significant gains in these new areas, improving 3D MRI condition classification accuracy by 11% and 3D CT condition classification by 3% (absolute improvements). In whole slide pathology imaging, MedGemma 1.5 4B achieves a 47% macro F1 gain. Additionally, it improves anatomical localization with a 35% increase in Intersection over Union on chest X-rays and achieves a 4% macro accuracy for longitudinal (multi-timepoint) chest x-ray analysis. Beyond its improved multimodal performance over MedGemma 1, MedGemma 1.5 improves on text-based clinical knowledge and reasoning, improving by 5% on MedQA accuracy and 22% on EHRQA accuracy. It also achieves an average of 18% macro F1 on 4 different lab report information extraction datasets (EHR Datasets 2, 3, 4, and Mendeley Clinical Laboratory Test Reports). Taken together, MedGemma 1.5 serves as a robust, open resource for the community, designed as an improved foundation on which developers can create the next generation of medical AI systems. Resources and tutorials for building upon MedGemma 1.5 can be found at https://goo.gle/MedGemma.
Towards a Science of Scaling Agent Systems
Dec 17, 2025Agents, language model-based systems that are capable of reasoning, planning, and acting are becoming the dominant paradigm for real-world AI applications. Despite this widespread adoption, the principles that determine their performance remain underexplored. We address this by deriving quantitative scaling principles for agent systems. We first formalize a definition for agentic evaluation and characterize scaling laws as the interplay between agent quantity, coordination structure, model capability, and task properties. We evaluate this across four benchmarks: Finance-Agent, BrowseComp-Plus, PlanCraft, and Workbench. With five canonical agent architectures (Single-Agent and four Multi-Agent Systems: Independent, Centralized, Decentralized, Hybrid), instantiated across three LLM families, we perform a controlled evaluation spanning 180 configurations. We derive a predictive model using coordination metrics, that achieves cross-validated R^2=0.524, enabling prediction on unseen task domains. We identify three effects: (1) a tool-coordination trade-off: under fixed computational budgets, tool-heavy tasks suffer disproportionately from multi-agent overhead. (2) a capability saturation: coordination yields diminishing or negative returns once single-agent baselines exceed ~45%. (3) topology-dependent error amplification: independent agents amplify errors 17.2x, while centralized coordination contains this to 4.4x. Centralized coordination improves performance by 80.8% on parallelizable tasks, while decentralized coordination excels on web navigation (+9.2% vs. +0.2%). Yet for sequential reasoning tasks, every multi-agent variants degraded performance by 39-70%. The framework predicts the optimal coordination strategy for 87% of held-out configurations. Out-of-sample validation on GPT-5.2, achieves MAE=0.071 and confirms four of five scaling principles generalize to unseen frontier models.
InvThink: Towards AI Safety via Inverse Reasoning
Oct 02, 2025



We present InvThink, a simple yet powerful approach that gives large language models (LLMs) the capability of inverse thinking: reasoning through failure modes before generating responses. Unlike existing safety alignment methods that optimize directly for safe response, InvThink instructs models to 1) enumerate potential harms, 2) analyze their consequences, and 3) generate safe outputs that proactively avoid these risks. Our method reveals three key findings: (i) safety improvements show stronger scaling with model size compared to existing safety methods. (ii) InvThink mitigates safety tax; by training models to systematically consider failure modes, it preserves general reasoning capabilities on standard benchmarks. (iii) beyond general safety tasks, InvThink excels in high-stakes domains including external-facing (medicine, finance, law) and agentic (blackmail, murder) risk scenarios, achieving up to 15.7% reduction in harmful responses compared to baseline methods like SafetyPrompt. We further implement InvThink via supervised fine-tuning, and reinforcement learning across three LLM families. These results suggest that inverse reasoning provides a scalable and generalizable path toward safer, more capable language models.
Advancing Conversational Diagnostic AI with Multimodal Reasoning
May 06, 2025



Large Language Models (LLMs) have demonstrated great potential for conducting diagnostic conversations but evaluation has been largely limited to language-only interactions, deviating from the real-world requirements of remote care delivery. Instant messaging platforms permit clinicians and patients to upload and discuss multimodal medical artifacts seamlessly in medical consultation, but the ability of LLMs to reason over such data while preserving other attributes of competent diagnostic conversation remains unknown. Here we advance the conversational diagnosis and management performance of the Articulate Medical Intelligence Explorer (AMIE) through a new capability to gather and interpret multimodal data, and reason about this precisely during consultations. Leveraging Gemini 2.0 Flash, our system implements a state-aware dialogue framework, where conversation flow is dynamically controlled by intermediate model outputs reflecting patient states and evolving diagnoses. Follow-up questions are strategically directed by uncertainty in such patient states, leading to a more structured multimodal history-taking process that emulates experienced clinicians. We compared AMIE to primary care physicians (PCPs) in a randomized, blinded, OSCE-style study of chat-based consultations with patient actors. We constructed 105 evaluation scenarios using artifacts like smartphone skin photos, ECGs, and PDFs of clinical documents across diverse conditions and demographics. Our rubric assessed multimodal capabilities and other clinically meaningful axes like history-taking, diagnostic accuracy, management reasoning, communication, and empathy. Specialist evaluation showed AMIE to be superior to PCPs on 7/9 multimodal and 29/32 non-multimodal axes (including diagnostic accuracy). The results show clear progress in multimodal conversational diagnostic AI, but real-world translation needs further research.
Capabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
A Bag of Tricks for Few-Shot Class-Incremental Learning
Mar 21, 2024



We present a bag of tricks framework for few-shot class-incremental learning (FSCIL), which is a challenging form of continual learning that involves continuous adaptation to new tasks with limited samples. FSCIL requires both stability and adaptability, i.e., preserving proficiency in previously learned tasks while learning new ones. Our proposed bag of tricks brings together eight key and highly influential techniques that improve stability, adaptability, and overall performance under a unified framework for FSCIL. We organize these tricks into three categories: stability tricks, adaptability tricks, and training tricks. Stability tricks aim to mitigate the forgetting of previously learned classes by enhancing the separation between the embeddings of learned classes and minimizing interference when learning new ones. On the other hand, adaptability tricks focus on the effective learning of new classes. Finally, training tricks improve the overall performance without compromising stability or adaptability. We perform extensive experiments on three benchmark datasets, CIFAR-100, CUB-200, and miniIMageNet, to evaluate the impact of our proposed framework. Our detailed analysis shows that our approach substantially improves both stability and adaptability, establishing a new state-of-the-art by outperforming prior works in the area. We believe our method provides a go-to solution and establishes a robust baseline for future research in this area.
Reliable and Trustworthy Machine Learning for Health Using Dataset Shift Detection
Oct 26, 2021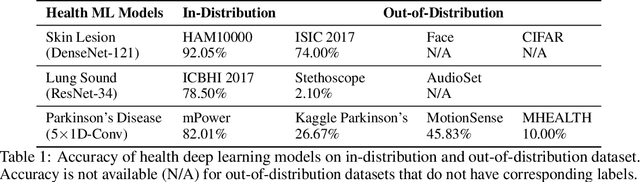
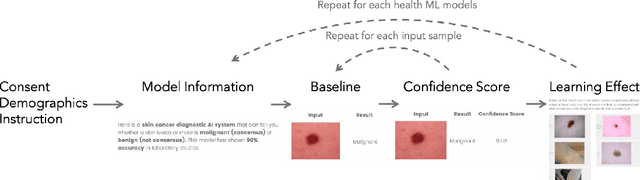
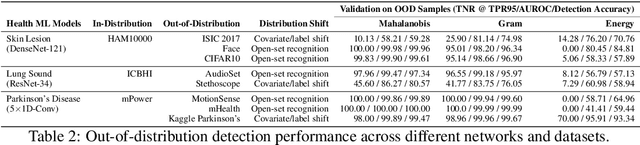

Unpredictable ML model behavior on unseen data, especially in the health domain, raises serious concerns about its safety as repercussions for mistakes can be fatal. In this paper, we explore the feasibility of using state-of-the-art out-of-distribution detectors for reliable and trustworthy diagnostic predictions. We select publicly available deep learning models relating to various health conditions (e.g., skin cancer, lung sound, and Parkinson's disease) using various input data types (e.g., image, audio, and motion data). We demonstrate that these models show unreasonable predictions on out-of-distribution datasets. We show that Mahalanobis distance- and Gram matrices-based out-of-distribution detection methods are able to detect out-of-distribution data with high accuracy for the health models that operate on different modalities. We then translate the out-of-distribution score into a human interpretable CONFIDENCE SCORE to investigate its effect on the users' interaction with health ML applications. Our user study shows that the \textsc{confidence score} helped the participants only trust the results with a high score to make a medical decision and disregard results with a low score. Through this work, we demonstrate that dataset shift is a critical piece of information for high-stake ML applications, such as medical diagnosis and healthcare, to provide reliable and trustworthy predictions to the users.