 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARE: A Conformal Safety Layer for Medical Summarization
Jun 08, 2026Large language models (LLMs) are increasingly used for medical summarization, but their outputs can omit medically important information and introduce unsupported claims. Existing error-detection methods produce heuristic or uncalibrated scores, providing no formal control over missed errors and no principled way to trade off safety against clinician review burden. We introduce Conformal Assessment for Risk Evaluation (CARE), a post-hoc, model-agnostic safety layer that uses conformal risk control to overlay calibrated omission and hallucination flags onto summaries from any LLM without retraining. CARE provides finite-sample, distribution-free guarantees through two controllers: a hallucination controller that bounds the probability of a document containing any unflagged hallucinated sentence, and an omission controller that bounds the expected fraction of important omissions not surfaced for review. Unlike hallucination detection, omissions depend jointly on whether a source sentence is important and whether it is covered by the summary. We show that calibrating only one dimension can violate the target risk bound, while marginal decompositions remain valid but overly conservative. By jointly calibrating over the full $(τ,γ)$ threshold space, CARE preserves formal guarantees while surfacing up to 5$\times$ fewer sentences than alternative calibrated baselines. Across five medical summarization tasks, CARE satisfies the target risk bound at $α= 0.15$ with 95% confidence across 100 calibration/test resplits, using only ~100 labeled documents per domain. In a preliminary clinician study (75 document reviews), calibrated flags improved omission detection by 28.6 percentage points on average. These results show that sentence-level safety guarantees are feasible for LLM-assisted medical summarization and offer a tunable mechanism for balancing residual risk and review effort.
Towards Conversational Medical AI with Eyes, Ears and a Voice
May 10, 2026The practice of medicine relies not only upon skillful dialogue but also on the nuanced exchange and interpretation of rich auditory and visual cues between doctors and patients. Building on the low-latency voice and video processing capabilities of Gemini, we introduce AI co-clinician, a first-of-its-kind conversational AI system utilizing continuous streams of audio-visual data from live patient conversations to inform real-time clinical decisions. Its dual-agent architecture balances deep clinical reasoning with the low latency required for natural dialogue. To assess this system, we implemented a video-based interface emulating telemedicine consultations. We crafted 20 standardized outpatient scenarios requiring proactive real-time auditory and visual reasoning and designed "TelePACES" evaluation criteria alongside case-specific rubrics. In a randomized, interface-blinded, crossover simulation study (n = 120 encounters) with 10 internal medicine residents as patient actors, we compared AI co-clinician with primary care physicians (PCPs), GPT-Realtime, and a baseline agent. AI co-clinician approached PCPs in key TelePACES dimensions, including management plans and differential diagnosis, while significantly outperforming GPT-Realtime across all general criteria. While our agent demonstrated parity with PCPs in case-specific triage measures, physicians maintained superior overall performance in case-specific assessments. Although AI co-clinician marks a significant advance in real-time telemedical AI, gaps remain in physical examination and disease-specific reasoning. Our work shows that text-only approaches fail to capture the true challenges of medical consultation and suggests that high-stakes real-time diagnostic AI is most safely advanced in collaborative, triadic models where AI can be a supportive co-clinician for doctors and patients.
A prospective clinical feasibility study of a conversational diagnostic AI in an ambulatory primary care clinic
Mar 10, 2026Large language model (LLM)-based AI systems have shown promise for patient-facing diagnostic and management conversations in simulated settings. Translating these systems into clinical practice requires assessment in real-world workflows with rigorous safety oversight. We report a prospective, single-arm feasibility study of an LLM-based conversational AI, the Articulate Medical Intelligence Explorer (AMIE), conducting clinical history taking and presentation of potential diagnoses for patients to discuss with their provider at urgent care appointments at a leading academic medical center. 100 adult patients completed an AMIE text-chat interaction up to 5 days before their appointment. We sought to assess the conversational safety and quality, patient and clinician experience, and clinical reasoning capabilities compared to primary care providers (PCPs). Human safety supervisors monitored all patient-AMIE interactions in real time and did not need to intervene to stop any consultations based on pre-defined criteria. Patients reported high satisfaction and their attitudes towards AI improved after interacting with AMIE (p < 0.001). PCPs found AMIE's output useful with a positive impact on preparedness. AMIE's differential diagnosis (DDx) included the final diagnosis, per chart review 8 weeks post-encounter, in 90% of cases, with 75% top-3 accuracy. Blinded assessment of AMIE and PCP DDx and management (Mx) plans suggested similar overall DDx and Mx plan quality, without significant differences for DDx (p = 0.6) and appropriateness and safety of Mx (p = 0.1 and 1.0, respectively). PCPs outperformed AMIE in the practicality (p = 0.003) and cost effectiveness (p = 0.004) of Mx. While further research is needed, this study demonstrates the initial feasibility, safety, and user acceptance of conversational AI in a real-world setting, representing crucial steps towards clinical translation.
Advancing Conversational Diagnostic AI with Multimodal Reasoning
May 06, 2025



Large Language Models (LLMs) have demonstrated great potential for conducting diagnostic conversations but evaluation has been largely limited to language-only interactions, deviating from the real-world requirements of remote care delivery. Instant messaging platforms permit clinicians and patients to upload and discuss multimodal medical artifacts seamlessly in medical consultation, but the ability of LLMs to reason over such data while preserving other attributes of competent diagnostic conversation remains unknown. Here we advance the conversational diagnosis and management performance of the Articulate Medical Intelligence Explorer (AMIE) through a new capability to gather and interpret multimodal data, and reason about this precisely during consultations. Leveraging Gemini 2.0 Flash, our system implements a state-aware dialogue framework, where conversation flow is dynamically controlled by intermediate model outputs reflecting patient states and evolving diagnoses. Follow-up questions are strategically directed by uncertainty in such patient states, leading to a more structured multimodal history-taking process that emulates experienced clinicians. We compared AMIE to primary care physicians (PCPs) in a randomized, blinded, OSCE-style study of chat-based consultations with patient actors. We constructed 105 evaluation scenarios using artifacts like smartphone skin photos, ECGs, and PDFs of clinical documents across diverse conditions and demographics. Our rubric assessed multimodal capabilities and other clinically meaningful axes like history-taking, diagnostic accuracy, management reasoning, communication, and empathy. Specialist evaluation showed AMIE to be superior to PCPs on 7/9 multimodal and 29/32 non-multimodal axes (including diagnostic accuracy). The results show clear progress in multimodal conversational diagnostic AI, but real-world translation needs further research.
Towards Conversational AI for Disease Management
Mar 08, 2025



While large language models (LLMs) have shown promise in diagnostic dialogue, their capabilities for effective management reasoning - including disease progression, therapeutic response, and safe medication prescription - remain under-explored. We advance the previously demonstrated diagnostic capabilities of the Articulate Medical Intelligence Explorer (AMIE) through a new LLM-based agentic system optimised for clinical management and dialogue, incorporating reasoning over the evolution of disease and multiple patient visit encounters, response to therapy, and professional competence in medication prescription. To ground its reasoning in authoritative clinical knowledge, AMIE leverages Gemini's long-context capabilities, combining in-context retrieval with structured reasoning to align its output with relevant and up-to-date clinical practice guidelines and drug formularies. In a randomized, blinded virtual Objective Structured Clinical Examination (OSCE) study, AMIE was compared to 21 primary care physicians (PCPs) across 100 multi-visit case scenarios designed to reflect UK NICE Guidance and BMJ Best Practice guidelines. AMIE was non-inferior to PCPs in management reasoning as assessed by specialist physicians and scored better in both preciseness of treatments and investigations, and in its alignment with and grounding of management plans in clinical guidelines. To benchmark medication reasoning, we developed RxQA, a multiple-choice question benchmark derived from two national drug formularies (US, UK) and validated by board-certified pharmacists. While AMIE and PCPs both benefited from the ability to access external drug information, AMIE outperformed PCPs on higher difficulty questions. While further research would be needed before real-world translation, AMIE's strong performance across evaluations marks a significant step towards conversational AI as a tool in disease management.
Conformalized Credal Regions for Classification with Ambiguous Ground Truth
Nov 07, 2024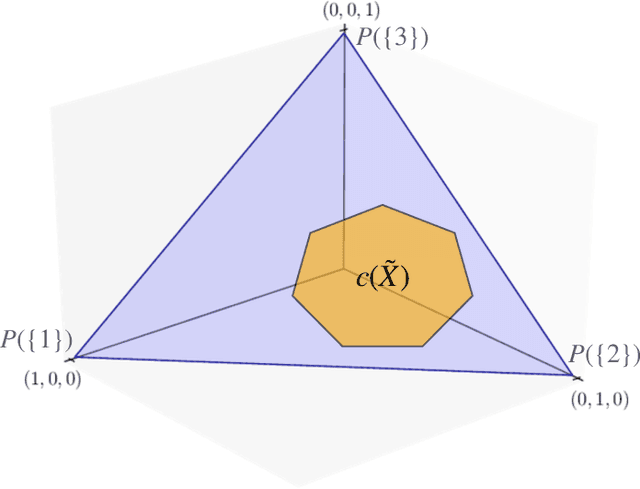
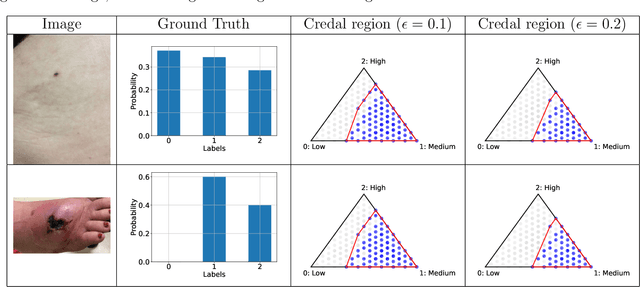
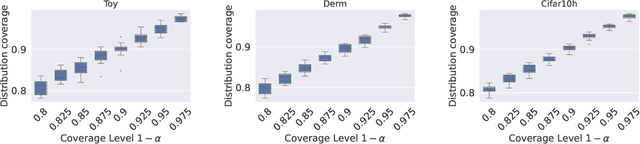
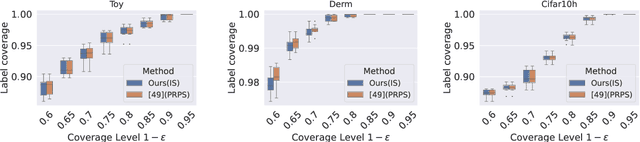
An open question in \emph{Imprecise Probabilistic Machine Learning} is how to empirically derive a credal region (i.e., a closed and convex family of probabilities on the output space) from the available data, without any prior knowledge or assumption. In classification problems, credal regions are a tool that is able to provide provable guarantees under realistic assumptions by characterizing the uncertainty about the distribution of the labels. Building on previous work, we show that credal regions can be directly constructed using conformal methods. This allows us to provide a novel extension of classical conformal prediction to problems with ambiguous ground truth, that is, when the exact labels for given inputs are not exactly known. The resulting construction enjoys desirable practical and theoretical properties: (i) conformal coverage guarantees, (ii) smaller prediction sets (compared to classical conformal prediction regions) and (iii) disentanglement of uncertainty sources (epistemic, aleatoric). We empirically verify our findings on both synthetic and real datasets.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Capabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
Conformalized Credal Set Predictors
Feb 16, 2024Credal sets are sets of probability distributions that are considered as candidates for an imprecisely known ground-truth distribution. In machine learning, they have recently attracted attention as an appealing formalism for uncertainty representation, in particular due to their ability to represent both the aleatoric and epistemic uncertainty in a prediction. However, the design of methods for learning credal set predictors remains a challenging problem. In this paper, we make use of conformal prediction for this purpose. More specifically, we propose a method for predicting credal sets in the classification task, given training data labeled by probability distributions. Since our method inherits the coverage guarantees of conformal prediction, our conformal credal sets are guaranteed to be valid with high probability (without any assumptions on model or distribution). We demonstrate the applicability of our method to natural language inference, a highly ambiguous natural language task where it is common to obtain multiple annotations per example.
Certified Robust Models with Slack Control and Large Lipschitz Constants
Sep 12, 2023



Despite recent success, state-of-the-art learning-based models remain highly vulnerable to input changes such as adversarial examples. In order to obtain certifiable robustness against such perturbations, recent work considers Lipschitz-based regularizers or constraints while at the same time increasing prediction margin. Unfortunately, this comes at the cost of significantly decreased accuracy. In this paper, we propose a Calibrated Lipschitz-Margin Loss (CLL) that addresses this issue and improves certified robustness by tackling two problems: Firstly, commonly used margin losses do not adjust the penalties to the shrinking output distribution; caused by minimizing the Lipschitz constant $K$. Secondly, and most importantly, we observe that minimization of $K$ can lead to overly smooth decision functions. This limits the model's complexity and thus reduces accuracy. Our CLL addresses these issues by explicitly calibrating the loss w.r.t. margin and Lipschitz constant, thereby establishing full control over slack and improving robustness certificates even with larger Lipschitz constants. On CIFAR-10, CIFAR-100 and Tiny-ImageNet, our models consistently outperform losses that leave the constant unattended. On CIFAR-100 and Tiny-ImageNet, CLL improves upon state-of-the-art deterministic $L_2$ robust accuracies. In contrast to current trends, we unlock potential of much smaller models without $K=1$ constraints.