 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeCo: Task Decomposition and Skill Composition for Zero-Shot Generalization in Long-Horizon 3D Manipulation
May 01, 2025Generalizing language-conditioned multi-task imitation learning (IL) models to novel long-horizon 3D manipulation tasks remains a significant challenge. To address this, we propose DeCo (Task Decomposition and Skill Composition), a model-agnostic framework compatible with various multi-task IL models, designed to enhance their zero-shot generalization to novel, compositional, long-horizon 3D manipulation tasks. DeCo first decomposes IL demonstrations into a set of modular atomic tasks based on the physical interaction between the gripper and objects, and constructs an atomic training dataset that enables models to learn a diverse set of reusable atomic skills during imitation learning. At inference time, DeCo leverages a vision-language model (VLM) to parse high-level instructions for novel long-horizon tasks, retrieve the relevant atomic skills, and dynamically schedule their execution; a spatially-aware skill-chaining module then ensures smooth, collision-free transitions between sequential skills. We evaluate DeCo in simulation using DeCoBench, a benchmark specifically designed to assess zero-shot generalization of multi-task IL models in compositional long-horizon 3D manipulation. Across three representative multi-task IL models (RVT-2, 3DDA, and ARP), DeCo achieves success rate improvements of 66.67%, 21.53%, and 57.92%, respectively, on 12 novel compositional tasks. Moreover, in real-world experiments, a DeCo-enhanced model trained on only 6 atomic tasks successfully completes 9 novel long-horizon tasks, yielding an average success rate improvement of 53.33% over the base multi-task IL model. Video demonstrations are available at: https://deco226.github.io.
GravMAD: Grounded Spatial Value Maps Guided Action Diffusion for Generalized 3D Manipulation
Sep 30, 2024Robots' ability to follow language instructions and execute diverse 3D tasks is vital in robot learning. Traditional imitation learning-based methods perform well on seen tasks but struggle with novel, unseen ones due to variability. Recent approaches leverage large foundation models to assist in understanding novel tasks, thereby mitigating this issue. However, these methods lack a task-specific learning process, which is essential for an accurate understanding of 3D environments, often leading to execution failures. In this paper, we introduce GravMAD, a sub-goal-driven, language-conditioned action diffusion framework that combines the strengths of imitation learning and foundation models. Our approach breaks tasks into sub-goals based on language instructions, allowing auxiliary guidance during both training and inference. During training, we introduce Sub-goal Keypose Discovery to identify key sub-goals from demonstrations. Inference differs from training, as there are no demonstrations available, so we use pre-trained foundation models to bridge the gap and identify sub-goals for the current task. In both phases, GravMaps are generated from sub-goals, providing flexible 3D spatial guidance compared to fixed 3D positions. Empirical evaluations on RLBench show that GravMAD significantly outperforms state-of-the-art methods, with a 28.63% improvement on novel tasks and a 13.36% gain on tasks encountered during training. These results demonstrate GravMAD's strong multi-task learning and generalization in 3D manipulation. Video demonstrations are available at: https://gravmad.github.io.
LibFewShot: A Comprehensive Library for Few-shot Learning
Sep 10, 2021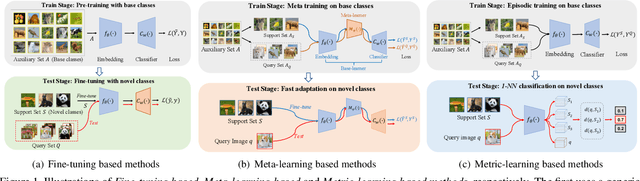
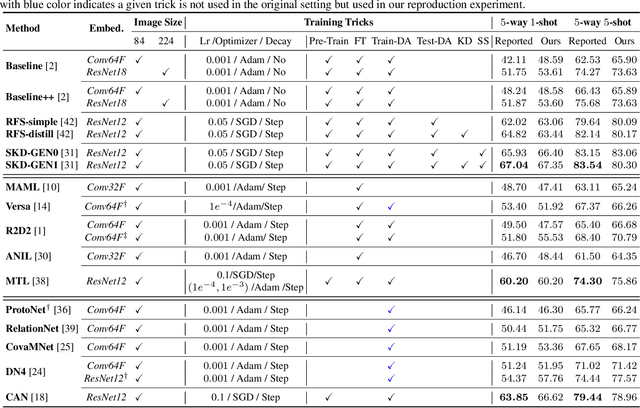
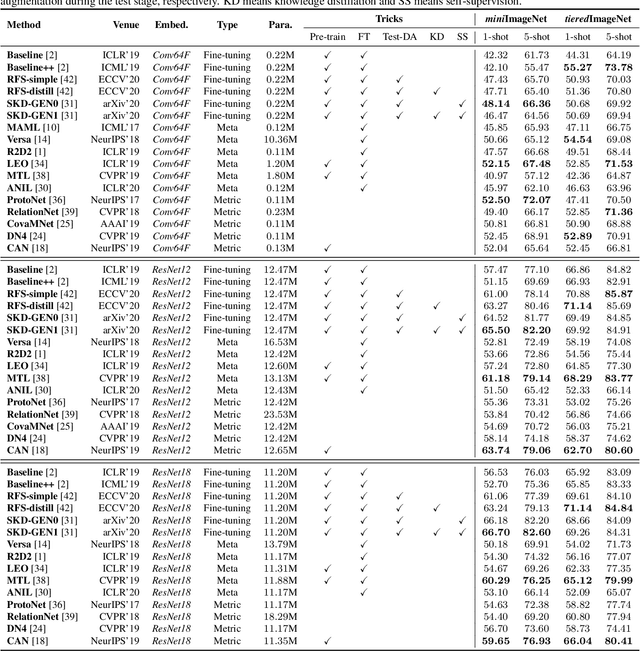
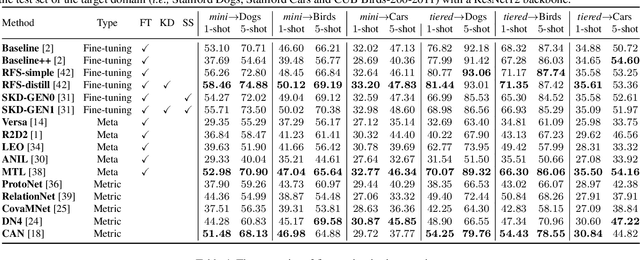
Few-shot learning, especially few-shot image classification, has received increasing attention and witnessed significant advances in recent years. Some recent studies implicitly show that many generic techniques or ``tricks'', such as data augmentation, pre-training, knowledge distillation, and self-supervision, may greatly boost the performance of a few-shot learning method. Moreover, different works may employ different software platforms, different training schedules, different backbone architectures and even different input image sizes, making fair comparisons difficult and practitioners struggle with reproducibility. To address these situations, we propose a comprehensive library for few-shot learning (LibFewShot) by re-implementing seventeen state-of-the-art few-shot learning methods in a unified framework with the same single codebase in PyTorch. Furthermore, based on LibFewShot, we provide comprehensive evaluations on multiple benchmark datasets with multiple backbone architectures to evaluate common pitfalls and effects of different training tricks. In addition, given the recent doubts on the necessity of meta- or episodic-training mechanism, our evaluation results show that such kind of mechanism is still necessary especially when combined with pre-training. We hope our work can not only lower the barriers for beginners to work on few-shot learning but also remove the effects of the nontrivial tricks to facilitate intrinsic research on few-shot learning. The source code is available from https://github.com/RL-VIG/LibFewShot.
Improving the Generalization of Meta-learning on Unseen Domains via Adversarial Shift
Jul 23, 2021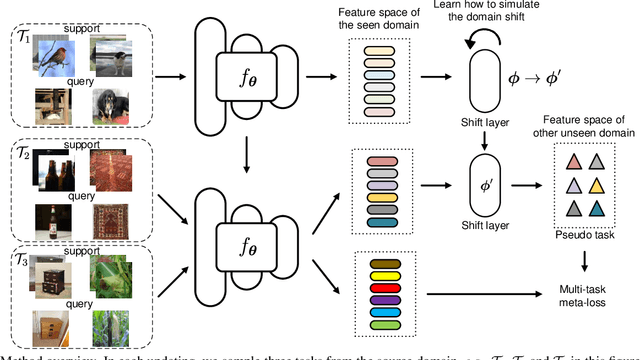
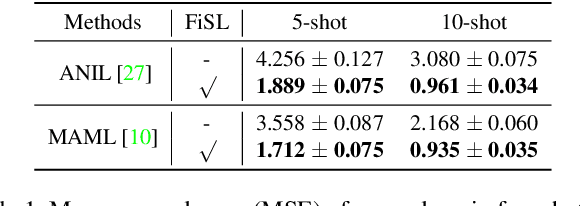
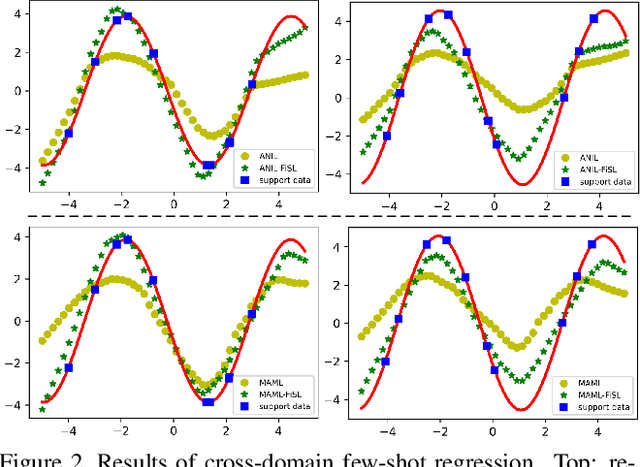
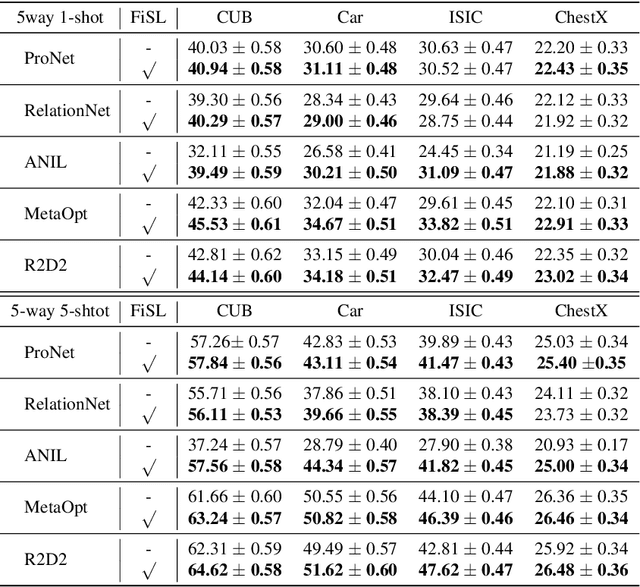
Meta-learning provides a promising way for learning to efficiently learn and achieves great success in many applications. However, most meta-learning literature focuses on dealing with tasks from a same domain, making it brittle to generalize to tasks from the other unseen domains. In this work, we address this problem by simulating tasks from the other unseen domains to improve the generalization and robustness of meta-learning method. Specifically, we propose a model-agnostic shift layer to learn how to simulate the domain shift and generate pseudo tasks, and develop a new adversarial learning-to-learn mechanism to train it. Based on the pseudo tasks, the meta-learning model can learn cross-domain meta-knowledge, which can generalize well on unseen domains. We conduct extensive experiments under the domain generalization setting. Experimental results demonstrate that the proposed shift layer is applicable to various meta-learning frameworks. Moreover, our method also leads to state-of-the-art performance on different cross-domain few-shot classification benchmarks and produces good results on cross-domain few-shot regression.
Differentiable Meta-learning Model for Few-shot Semantic Segmentation
Nov 23, 2019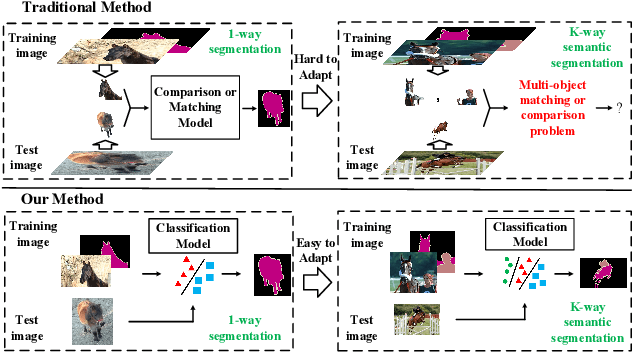
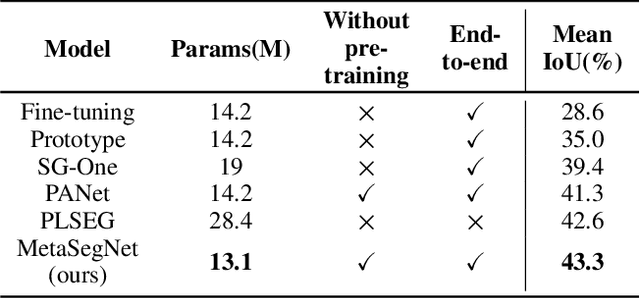
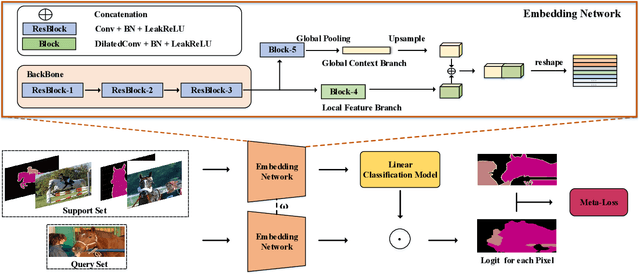
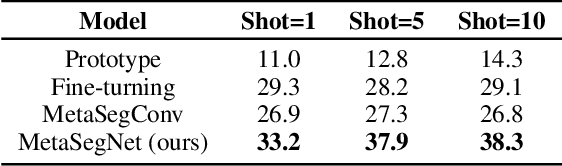
To address the annotation scarcity issue in some cases of semantic segmentation, there have been a few attempts to develop the segmentation model in the few-shot learning paradigm. However, most existing methods only focus on the traditional 1-way segmentation setting (i.e., one image only contains a single object). This is far away from practical semantic segmentation tasks where the K-way setting (K>1) is usually required by performing the accurate multi-object segmentation. To deal with this issue, we formulate the few-shot semantic segmentation task as a learning-based pixel classification problem and propose a novel framework called MetaSegNet based on meta-learning. In MetaSegNet, an architecture of embedding module consisting of the global and local feature branches is developed to extract the appropriate meta-knowledge for the few-shot segmentation. Moreover, we incorporate a linear model into MetaSegNet as a base learner to directly predict the label of each pixel for the multi-object segmentation. Furthermore, our MetaSegNet can be trained by the episodic training mechanism in an end-to-end manner from scratch. Experiments on two popular semantic segmentation datasets, i.e., PASCAL VOC and COCO, reveal the effectiveness of the proposed MetaSegNet in the K-way few-shot semantic segmentation task.