 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridgeIV: Bridging Customized Image and Video Generation through Test-Time Autoregressive Identity Propagation
May 11, 2025



Both zero-shot and tuning-based customized text-to-image (CT2I) generation have made significant progress for storytelling content creation. In contrast, research on customized text-to-video (CT2V) generation remains relatively limited. Existing zero-shot CT2V methods suffer from poor generalization, while another line of work directly combining tuning-based T2I models with temporal motion modules often leads to the loss of structural and texture information. To bridge this gap, we propose an autoregressive structure and texture propagation module (STPM), which extracts key structural and texture features from the reference subject and injects them autoregressively into each video frame to enhance consistency. Additionally, we introduce a test-time reward optimization (TTRO) method to further refine fine-grained details. Quantitative and qualitative experiments validate the effectiveness of STPM and TTRO, demonstrating improvements of 7.8 and 13.1 in CLIP-I and DINO consistency metrics over the baseline, respectively.
CombiBench: Benchmarking LLM Capability for Combinatorial Mathematics
May 06, 2025Neurosymbolic approaches integrating large language models with formal reasoning have recently achieved human-level performance on mathematics competition problems in algebra, geometry and number theory. In comparison, combinatorics remains a challenging domain, characterized by a lack of appropriate benchmarks and theorem libraries. To address this gap, we introduce CombiBench, a comprehensive benchmark comprising 100 combinatorial problems, each formalized in Lean~4 and paired with its corresponding informal statement. The problem set covers a wide spectrum of difficulty levels, ranging from middle school to IMO and university level, and span over ten combinatorial topics. CombiBench is suitable for testing IMO solving capabilities since it includes all IMO combinatorial problems since 2000 (except IMO 2004 P3 as its statement contain an images). Furthermore, we provide a comprehensive and standardized evaluation framework, dubbed Fine-Eval (for $\textbf{F}$ill-in-the-blank $\textbf{in}$ L$\textbf{e}$an Evaluation), for formal mathematics. It accommodates not only proof-based problems but also, for the first time, the evaluation of fill-in-the-blank questions. Using Fine-Eval as the evaluation method and Kimina Lean Server as the backend, we benchmark several LLMs on CombiBench and observe that their capabilities for formally solving combinatorial problems remain limited. Among all models tested (none of which has been trained for this particular task), Kimina-Prover attains the best results, solving 7 problems (out of 100) under both ``with solution'' and ``without solution'' scenarios. We open source the benchmark dataset alongside with the code of the proposed evaluation method at https://github.com/MoonshotAI/CombiBench/.
RoBridge: A Hierarchical Architecture Bridging Cognition and Execution for General Robotic Manipulation
May 03, 2025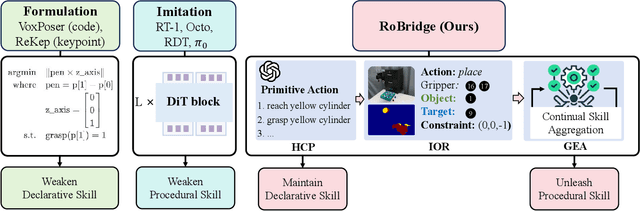
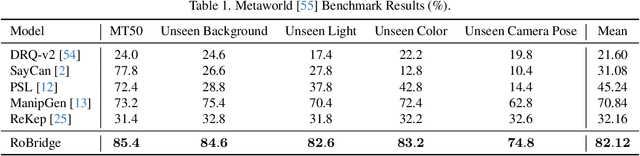
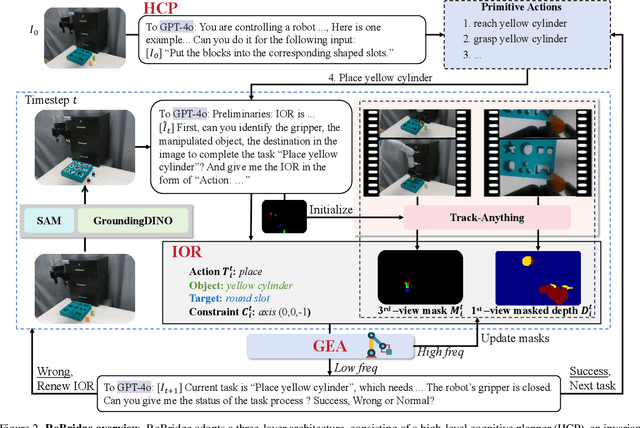
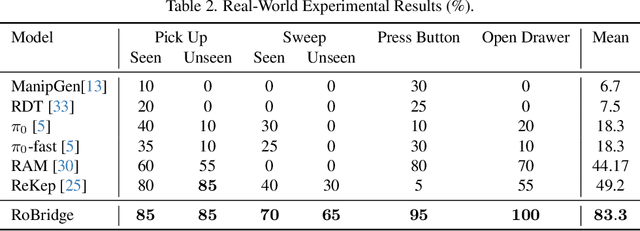
Operating robots in open-ended scenarios with diverse tasks is a crucial research and application direction in robotics. While recent progress in natural language processing and large multimodal models has enhanced robots' ability to understand complex instructions, robot manipulation still faces the procedural skill dilemma and the declarative skill dilemma in open environments. Existing methods often compromise cognitive and executive capabilities. To address these challenges, in this paper, we propose RoBridge, a hierarchical intelligent architecture for general robotic manipulation. It consists of a high-level cognitive planner (HCP) based on a large-scale pre-trained vision-language model (VLM), an invariant operable representation (IOR) serving as a symbolic bridge, and a generalist embodied agent (GEA). RoBridge maintains the declarative skill of VLM and unleashes the procedural skill of reinforcement learning, effectively bridging the gap between cognition and execution. RoBridge demonstrates significant performance improvements over existing baselines, achieving a 75% success rate on new tasks and an 83% average success rate in sim-to-real generalization using only five real-world data samples per task. This work represents a significant step towards integrating cognitive reasoning with physical execution in robotic systems, offering a new paradigm for general robotic manipulation.
SPC: Evolving Self-Play Critic via Adversarial Games for LLM Reasoning
Apr 27, 2025Evaluating the step-by-step reliability of large language model (LLM) reasoning, such as Chain-of-Thought, remains challenging due to the difficulty and cost of obtaining high-quality step-level supervision. In this paper, we introduce Self-Play Critic (SPC), a novel approach where a critic model evolves its ability to assess reasoning steps through adversarial self-play games, eliminating the need for manual step-level annotation. SPC involves fine-tuning two copies of a base model to play two roles, namely a "sneaky generator" that deliberately produces erroneous steps designed to be difficult to detect, and a "critic" that analyzes the correctness of reasoning steps. These two models engage in an adversarial game in which the generator aims to fool the critic, while the critic model seeks to identify the generator's errors. Using reinforcement learning based on the game outcomes, the models iteratively improve; the winner of each confrontation receives a positive reward and the loser receives a negative reward, driving continuous self-evolution. Experiments on three reasoning process benchmarks (ProcessBench, PRM800K, DeltaBench) demonstrate that our SPC progressively enhances its error detection capabilities (e.g., accuracy increases from 70.8% to 77.7% on ProcessBench) and surpasses strong baselines, including distilled R1 model. Furthermore, applying SPC to guide the test-time search of diverse LLMs significantly improves their mathematical reasoning performance on MATH500 and AIME2024, outperforming state-of-the-art process reward models.
A0: An Affordance-Aware Hierarchical Model for General Robotic Manipulation
Apr 21, 2025



Robotic manipulation faces critical challenges in understanding spatial affordances--the "where" and "how" of object interactions--essential for complex manipulation tasks like wiping a board or stacking objects. Existing methods, including modular-based and end-to-end approaches, often lack robust spatial reasoning capabilities. Unlike recent point-based and flow-based affordance methods that focus on dense spatial representations or trajectory modeling, we propose A0, a hierarchical affordance-aware diffusion model that decomposes manipulation tasks into high-level spatial affordance understanding and low-level action execution. A0 leverages the Embodiment-Agnostic Affordance Representation, which captures object-centric spatial affordances by predicting contact points and post-contact trajectories. A0 is pre-trained on 1 million contact points data and fine-tuned on annotated trajectories, enabling generalization across platforms. Key components include Position Offset Attention for motion-aware feature extraction and a Spatial Information Aggregation Layer for precise coordinate mapping. The model's output is executed by the action execution module. Experiments on multiple robotic systems (Franka, Kinova, Realman, and Dobot) demonstrate A0's superior performance in complex tasks, showcasing its efficiency, flexibility, and real-world applicability.
FireEdit: Fine-grained Instruction-based Image Editing via Region-aware Vision Language Model
Mar 25, 2025Currently, instruction-based image editing methods have made significant progress by leveraging the powerful cross-modal understanding capabilities of vision language models (VLMs). However, they still face challenges in three key areas: 1) complex scenarios; 2) semantic consistency; and 3) fine-grained editing. To address these issues, we propose FireEdit, an innovative Fine-grained Instruction-based image editing framework that exploits a REgion-aware VLM. FireEdit is designed to accurately comprehend user instructions and ensure effective control over the editing process. Specifically, we enhance the fine-grained visual perception capabilities of the VLM by introducing additional region tokens. Relying solely on the output of the LLM to guide the diffusion model may lead to suboptimal editing results. Therefore, we propose a Time-Aware Target Injection module and a Hybrid Visual Cross Attention module. The former dynamically adjusts the guidance strength at various denoising stages by integrating timestep embeddings with the text embeddings. The latter enhances visual details for image editing, thereby preserving semantic consistency between the edited result and the source image. By combining the VLM enhanced with fine-grained region tokens and the time-dependent diffusion model, FireEdit demonstrates significant advantages in comprehending editing instructions and maintaining high semantic consistency. Extensive experiments indicate that our approach surpasses the state-of-the-art instruction-based image editing methods. Our project is available at https://zjgans.github.io/fireedit.github.io.
Video SimpleQA: Towards Factuality Evaluation in Large Video Language Models
Mar 24, 2025



Recent advancements in Large Video Language Models (LVLMs) have highlighted their potential for multi-modal understanding, yet evaluating their factual grounding in video contexts remains a critical unsolved challenge. To address this gap, we introduce Video SimpleQA, the first comprehensive benchmark tailored for factuality evaluation of LVLMs. Our work distinguishes from existing video benchmarks through the following key features: 1) Knowledge required: demanding integration of external knowledge beyond the explicit narrative; 2) Fact-seeking question: targeting objective, undisputed events or relationships, avoiding subjective interpretation; 3) Definitive & short-form answer: Answers are crafted as unambiguous and definitively correct in a short format, enabling automated evaluation through LLM-as-a-judge frameworks with minimal scoring variance; 4) External-source verified: All annotations undergo rigorous validation against authoritative external references to ensure the reliability; 5) Temporal reasoning required: The annotated question types encompass both static single-frame understanding and dynamic temporal reasoning, explicitly evaluating LVLMs factuality under the long-context dependencies. We extensively evaluate 41 state-of-the-art LVLMs and summarize key findings as follows: 1) Current LVLMs exhibit notable deficiencies in factual adherence, particularly for open-source models. The best-performing model Gemini-1.5-Pro achieves merely an F-score of 54.4%; 2) Test-time compute paradigms show insignificant performance gains, revealing fundamental constraints for enhancing factuality through post-hoc computation; 3) Retrieval-Augmented Generation demonstrates consistent improvements at the cost of additional inference time overhead, presenting a critical efficiency-performance trade-off.
WISA: World Simulator Assistant for Physics-Aware Text-to-Video Generation
Mar 11, 2025Recent rapid advancements in text-to-video (T2V) generation, such as SoRA and Kling, have shown great potential for building world simulators. However, current T2V models struggle to grasp abstract physical principles and generate videos that adhere to physical laws. This challenge arises primarily from a lack of clear guidance on physical information due to a significant gap between abstract physical principles and generation models. To this end, we introduce the World Simulator Assistant (WISA), an effective framework for decomposing and incorporating physical principles into T2V models. Specifically, WISA decomposes physical principles into textual physical descriptions, qualitative physical categories, and quantitative physical properties. To effectively embed these physical attributes into the generation process, WISA incorporates several key designs, including Mixture-of-Physical-Experts Attention (MoPA) and a Physical Classifier, enhancing the model's physics awareness. Furthermore, most existing datasets feature videos where physical phenomena are either weakly represented or entangled with multiple co-occurring processes, limiting their suitability as dedicated resources for learning explicit physical principles. We propose a novel video dataset, WISA-32K, collected based on qualitative physical categories. It consists of 32,000 videos, representing 17 physical laws across three domains of physics: dynamics, thermodynamics, and optics. Experimental results demonstrate that WISA can effectively enhance the compatibility of T2V models with real-world physical laws, achieving a considerable improvement on the VideoPhy benchmark. The visual exhibitions of WISA and WISA-32K are available in the https://360cvgroup.github.io/WISA/.
Can Atomic Step Decomposition Enhance the Self-structured Reasoning of Multimodal Large Models?
Mar 08, 2025In this paper, we address the challenging task of multimodal mathematical reasoning by incorporating the ability of "slow thinking" into multimodal large language models (MLLMs). Our core idea is that different levels of reasoning abilities can be combined dynamically to tackle questions with different complexity. To this end, we propose a paradigm of Self-structured Chain of Thought (SCoT), which is composed of minimal semantic atomic steps. Different from existing methods that rely on structured templates or free-form paradigms, our method can not only generate cognitive CoT structures for various complex tasks but also mitigates the phenomenon of overthinking. To introduce structured reasoning capabilities into visual understanding models, we further design a novel AtomThink framework with four key modules, including (i) a data engine to generate high-quality multimodal reasoning paths; (ii) a supervised fine-tuning process with serialized inference data; (iii) a policy-guided multi-turn inference method; and (iv) an atomic capability metric to evaluate the single step utilization rate. We conduct extensive experiments to show that the proposed AtomThink significantly improves the performance of baseline MLLMs, achieving more than 10\% average accuracy gains on MathVista and MathVerse. Compared to state-of-the-art structured CoT approaches, our method not only achieves higher accuracy but also improves data utilization by 5 times and boosts inference efficiency by 85.3\%. Our code is now public available in https://github.com/Quinn777/AtomThink.
Structured Preference Optimization for Vision-Language Long-Horizon Task Planning
Feb 28, 2025Existing methods for vision-language task planning excel in short-horizon tasks but often fall short in complex, long-horizon planning within dynamic environments. These challenges primarily arise from the difficulty of effectively training models to produce high-quality reasoning processes for long-horizon tasks. To address this, we propose Structured Preference Optimization (SPO), which aims to enhance reasoning and action selection in long-horizon task planning through structured preference evaluation and optimized training strategies. Specifically, SPO introduces: 1) Preference-Based Scoring and Optimization, which systematically evaluates reasoning chains based on task relevance, visual grounding, and historical consistency; and 2) Curriculum-Guided Training, where the model progressively adapts from simple to complex tasks, improving its generalization ability in long-horizon scenarios and enhancing reasoning robustness. To advance research in vision-language long-horizon task planning, we introduce ExtendaBench, a comprehensive benchmark covering 1,509 tasks across VirtualHome and Habitat 2.0, categorized into ultra-short, short, medium, and long tasks. Experimental results demonstrate that SPO significantly improves reasoning quality and final decision accuracy, outperforming prior methods on long-horizon tasks and underscoring the effectiveness of preference-driven optimization in vision-language task planning. Specifically, SPO achieves a +5.98% GCR and +4.68% SR improvement in VirtualHome and a +3.30% GCR and +2.11% SR improvement in Habitat over the best-performing baselines.