 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk a Strong LLM Judge when Your Reward Model is Uncertain
Oct 23, 2025Reward model (RM) plays a pivotal role in reinforcement learning with human feedback (RLHF) for aligning large language models (LLMs). However, classical RMs trained on human preferences are vulnerable to reward hacking and generalize poorly to out-of-distribution (OOD) inputs. By contrast, strong LLM judges equipped with reasoning capabilities demonstrate superior generalization, even without additional training, but incur significantly higher inference costs, limiting their applicability in online RLHF. In this work, we propose an uncertainty-based routing framework that efficiently complements a fast RM with a strong but costly LLM judge. Our approach formulates advantage estimation in policy gradient (PG) methods as pairwise preference classification, enabling principled uncertainty quantification to guide routing. Uncertain pairs are forwarded to the LLM judge, while confident ones are evaluated by the RM. Experiments on RM benchmarks demonstrate that our uncertainty-based routing strategy significantly outperforms random judge calling at the same cost, and downstream alignment results showcase its effectiveness in improving online RLHF.
WebAgent-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
May 22, 2025While reinforcement learning (RL) has demonstrated remarkable success in enhancing large language models (LLMs), it has primarily focused on single-turn tasks such as solving math problems. Training effective web agents for multi-turn interactions remains challenging due to the complexity of long-horizon decision-making across dynamic web interfaces. In this work, we present WebAgent-R1, a simple yet effective end-to-end multi-turn RL framework for training web agents. It learns directly from online interactions with web environments by asynchronously generating diverse trajectories, entirely guided by binary rewards depending on task success. Experiments on the WebArena-Lite benchmark demonstrate the effectiveness of WebAgent-R1, boosting the task success rate of Qwen-2.5-3B from 6.1% to 33.9% and Llama-3.1-8B from 8.5% to 44.8%, significantly outperforming existing state-of-the-art methods and strong proprietary models such as OpenAI o3. In-depth analyses reveal the effectiveness of the thinking-based prompting strategy and test-time scaling through increased interactions for web tasks. We further investigate different RL initialization policies by introducing two variants, namely WebAgent-R1-Zero and WebAgent-R1-CoT, which highlight the importance of the warm-up training stage (i.e., behavior cloning) and provide insights on incorporating long chain-of-thought (CoT) reasoning in web agents.
Think-RM: Enabling Long-Horizon Reasoning in Generative Reward Models
May 22, 2025Reinforcement learning from human feedback (RLHF) has become a powerful post-training paradigm for aligning large language models with human preferences. A core challenge in RLHF is constructing accurate reward signals, where the conventional Bradley-Terry reward models (BT RMs) often suffer from sensitivity to data size and coverage, as well as vulnerability to reward hacking. Generative reward models (GenRMs) offer a more robust alternative by generating chain-of-thought (CoT) rationales followed by a final reward. However, existing GenRMs rely on shallow, vertically scaled reasoning, limiting their capacity to handle nuanced or complex (e.g., reasoning-intensive) tasks. Moreover, their pairwise preference outputs are incompatible with standard RLHF algorithms that require pointwise reward signals. In this work, we introduce Think-RM, a training framework that enables long-horizon reasoning in GenRMs by modeling an internal thinking process. Rather than producing structured, externally provided rationales, Think-RM generates flexible, self-guided reasoning traces that support advanced capabilities such as self-reflection, hypothetical reasoning, and divergent reasoning. To elicit these reasoning abilities, we first warm-up the models by supervised fine-tuning (SFT) over long CoT data. We then further improve the model's long-horizon abilities by rule-based reinforcement learning (RL). In addition, we propose a novel pairwise RLHF pipeline that directly optimizes policies using pairwise preference rewards, eliminating the need for pointwise reward conversion and enabling more effective use of Think-RM outputs. Experiments show that Think-RM achieves state-of-the-art results on RM-Bench, outperforming both BT RM and vertically scaled GenRM by 8%. When combined with our pairwise RLHF pipeline, it demonstrates superior end-policy performance compared to traditional approaches.
Artificial Intelligence-Enhanced Couinaud Segmentation for Precision Liver Cancer Therapy
Nov 05, 2024



Precision therapy for liver cancer necessitates accurately delineating liver sub-regions to protect healthy tissue while targeting tumors, which is essential for reducing recurrence and improving survival rates. However, the segmentation of hepatic segments, known as Couinaud segmentation, is challenging due to indistinct sub-region boundaries and the need for extensive annotated datasets. This study introduces LiverFormer, a novel Couinaud segmentation model that effectively integrates global context with low-level local features based on a 3D hybrid CNN-Transformer architecture. Additionally, a registration-based data augmentation strategy is equipped to enhance the segmentation performance with limited labeled data. Evaluated on CT images from 123 patients, LiverFormer demonstrated high accuracy and strong concordance with expert annotations across various metrics, allowing for enhanced treatment planning for surgery and radiation therapy. It has great potential to reduces complications and minimizes potential damages to surrounding tissue, leading to improved outcomes for patients undergoing complex liver cancer treatments.
ST-NeRP: Spatial-Temporal Neural Representation Learning with Prior Embedding for Patient-specific Imaging Study
Oct 25, 2024



During and after a course of therapy, imaging is routinely used to monitor the disease progression and assess the treatment responses. Despite of its significance, reliably capturing and predicting the spatial-temporal anatomic changes from a sequence of patient-specific image series presents a considerable challenge. Thus, the development of a computational framework becomes highly desirable for a multitude of practical applications. In this context, we propose a strategy of Spatial-Temporal Neural Representation learning with Prior embedding (ST-NeRP) for patient-specific imaging study. Our strategy involves leveraging an Implicit Neural Representation (INR) network to encode the image at the reference time point into a prior embedding. Subsequently, a spatial-temporally continuous deformation function is learned through another INR network. This network is trained using the whole patient-specific image sequence, enabling the prediction of deformation fields at various target time points. The efficacy of the ST-NeRP model is demonstrated through its application to diverse sequential image series, including 4D CT and longitudinal CT datasets within thoracic and abdominal imaging. The proposed ST-NeRP model exhibits substantial potential in enabling the monitoring of anatomical changes within a patient throughout the therapeutic journey.
Contrastive Learning with Counterfactual Explanations for Radiology Report Generation
Jul 19, 2024



Due to the common content of anatomy, radiology images with their corresponding reports exhibit high similarity. Such inherent data bias can predispose automatic report generation models to learn entangled and spurious representations resulting in misdiagnostic reports. To tackle these, we propose a novel \textbf{Co}unter\textbf{F}actual \textbf{E}xplanations-based framework (CoFE) for radiology report generation. Counterfactual explanations serve as a potent tool for understanding how decisions made by algorithms can be changed by asking ``what if'' scenarios. By leveraging this concept, CoFE can learn non-spurious visual representations by contrasting the representations between factual and counterfactual images. Specifically, we derive counterfactual images by swapping a patch between positive and negative samples until a predicted diagnosis shift occurs. Here, positive and negative samples are the most semantically similar but have different diagnosis labels. Additionally, CoFE employs a learnable prompt to efficiently fine-tune the pre-trained large language model, encapsulating both factual and counterfactual content to provide a more generalizable prompt representation. Extensive experiments on two benchmarks demonstrate that leveraging the counterfactual explanations enables CoFE to generate semantically coherent and factually complete reports and outperform in terms of language generation and clinical efficacy metrics.
Aligning Large Language Models via Fine-grained Supervision
Jun 04, 2024



Pre-trained large-scale language models (LLMs) excel at producing coherent articles, yet their outputs may be untruthful, toxic, or fail to align with user expectations. Current approaches focus on using reinforcement learning with human feedback (RLHF) to improve model alignment, which works by transforming coarse human preferences of LLM outputs into a feedback signal that guides the model learning process. However, because this approach operates on sequence-level feedback, it lacks the precision to identify the exact parts of the output affecting user preferences. To address this gap, we propose a method to enhance LLM alignment through fine-grained token-level supervision. Specifically, we ask annotators to minimally edit less preferred responses within the standard reward modeling dataset to make them more favorable, ensuring changes are made only where necessary while retaining most of the original content. The refined dataset is used to train a token-level reward model, which is then used for training our fine-grained Proximal Policy Optimization (PPO) model. Our experiment results demonstrate that this approach can achieve up to an absolute improvement of $5.1\%$ in LLM performance, in terms of win rate against the reference model, compared with the traditional PPO model.
A Survey of Deep Learning for Mathematical Reasoning
Dec 20, 2022



Mathematical reasoning is a fundamental aspect of human intelligence and is applicable in various fields, including science, engineering, finance, and everyday life. The development of artificial intelligence (AI) systems capable of solving math problems and proving theorems has garnered significant interest in the fields of machine learning and natural language processing. For example, mathematics serves as a testbed for aspects of reasoning that are challenging for powerful deep learning models, driving new algorithmic and modeling advances. On the other hand, recent advances in large-scale neural language models have opened up new benchmarks and opportunities to use deep learning for mathematical reasoning. In this survey paper, we review the key tasks, datasets, and methods at the intersection of mathematical reasoning and deep learning over the past decade. We also evaluate existing benchmarks and methods, and discuss future research directions in this domain.
OpenD: A Benchmark for Language-Driven Door and Drawer Opening
Dec 10, 2022



We introduce OPEND, a benchmark for learning how to use a hand to open cabinet doors or drawers in a photo-realistic and physics-reliable simulation environment driven by language instruction. To solve the task, we propose a multi-step planner composed of a deep neural network and rule-base controllers. The network is utilized to capture spatial relationships from images and understand semantic meaning from language instructions. Controllers efficiently execute the plan based on the spatial and semantic understanding. We evaluate our system by measuring its zero-shot performance in test data set. Experimental results demonstrate the effectiveness of decision planning by our multi-step planner for different hands, while suggesting that there is significant room for developing better models to address the challenge brought by language understanding, spatial reasoning, and long-term manipulation. We will release OPEND and host challenges to promote future research in this area.
Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning
Sep 29, 2022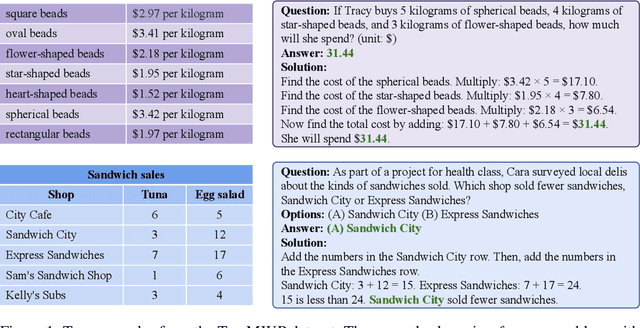
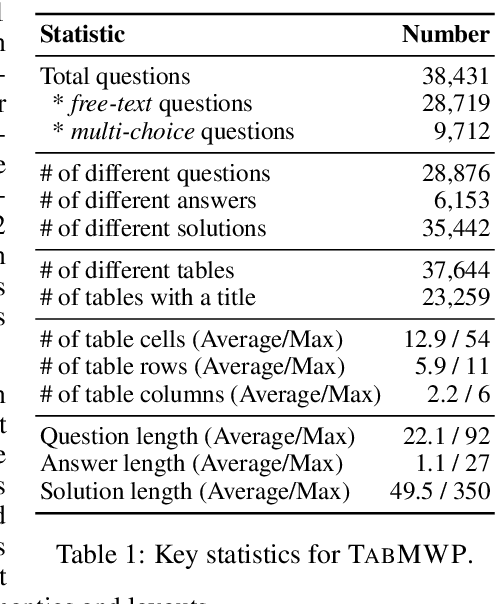
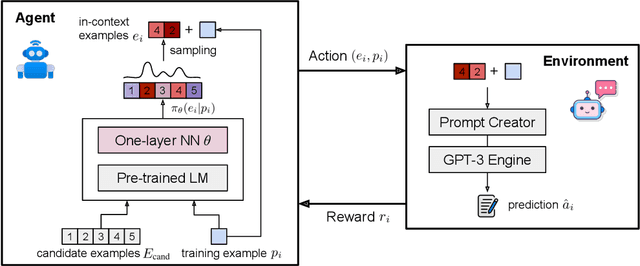
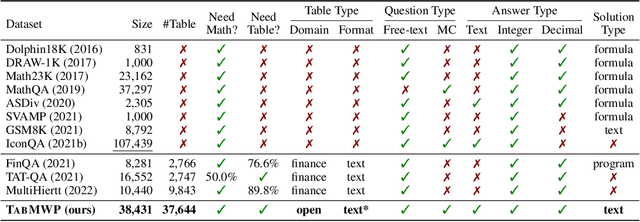
Mathematical reasoning, a core ability of human intelligence, presents unique challenges for machines in abstract thinking and logical reasoning. Recent large pre-trained language models such as GPT-3 have achieved remarkable progress on mathematical reasoning tasks written in text form, such as math word problems (MWP). However, it is unknown if the models can handle more complex problems that involve math reasoning over heterogeneous information, such as tabular data. To fill the gap, we present Tabular Math Word Problems (TabMWP), a new dataset containing 38,431 open-domain grade-level problems that require mathematical reasoning on both textual and tabular data. Each question in TabMWP is aligned with a tabular context, which is presented as an image, semi-structured text, and a structured table. There are two types of questions: free-text and multi-choice, and each problem is annotated with gold solutions to reveal the multi-step reasoning process. We evaluate different pre-trained models on TabMWP, including the GPT-3 model in a few-shot setting. As earlier studies suggest, since few-shot GPT-3 relies on the selection of in-context examples, its performance is unstable and can degrade to near chance. The unstable issue is more severe when handling complex problems like TabMWP. To mitigate this, we further propose a novel approach, PromptPG, which utilizes policy gradient to learn to select in-context examples from a small amount of training data and then constructs the corresponding prompt for the test example. Experimental results show that our method outperforms the best baseline by 5.31% on the accuracy metric and reduces the prediction variance significantly compared to random selection, which verifies its effectiveness in the selection of in-context examples.