 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRePO-VLA: Recovery-Driven Policy Optimization for Vision-Language-Action Models
May 10, 2026Vision-Language-Action (VLA) models remain brittle in long-horizon, contact-rich manipulation because success-only imitation provides little supervision for execution drift, while failed rollouts are often discarded. We introduce RePO-VLA, a recovery-driven policy optimization framework that assigns distinct roles to success, recovery, and failure trajectories. RePO-VLA first applies Recovery-Aware Initialization (RAI), slicing recovery segments and resetting history so corrective actions depend on the current adverse state rather than the preceding failure. It then learns a Progress-Aware Semantic Value Function (PAS-VF), aligning spatiotemporal trajectory features with instructions and successful references. The resulting labels salvage useful failure prefixes via reliability decay, while low-value labels mark drift and terminal breakdowns, teaching differences among nominal, failed, and corrective actions. The data engine turns adverse states into planner-generated or human-collected corrective rollouts, teaching recovery to the success manifold. Value-Conditioned Refinement (VCR) trains the policy to prefer high-progress actions. At deployment, a fixed high value ($v=1.0$) biases actions toward the learned success manifold without online failure detectors or heuristic retries. We introduce FRBench, with standardized error injection and recovery-focused evaluation. Across simulated and real-world bimanual tasks, RePO-VLA improves robustness, raising adversarial success from 20% to 75% on average and up to 80% in scaled real-world trials.
A1: A Fully Transparent Open-Source, Adaptive and Efficient Truncated Vision-Language-Action Model
Apr 07, 2026Vision--Language--Action (VLA) models have emerged as a powerful paradigm for open-world robot manipulation, but their practical deployment is often constrained by \emph{cost}: billion-scale VLM backbones and iterative diffusion/flow-based action heads incur high latency and compute, making real-time control expensive on commodity hardware. We present A1, a fully open-source and transparent VLA framework designed for low-cost, high-throughput inference without sacrificing manipulation success; Our approach leverages pretrained VLMs that provide implicit affordance priors for action generation. We release the full training stack (training code, data/data-processing pipeline, intermediate checkpoints, and evaluation scripts) to enable end-to-end reproducibility. Beyond optimizing the VLM alone, A1 targets the full inference pipeline by introducing a budget-aware adaptive inference scheme that jointly accelerates the backbone and the \emph{action head}. Specifically, we monitor action consistency across intermediate VLM layers to trigger early termination, and propose Inter-Layer Truncated Flow Matching that warm-starts denoising across layers, enabling accurate actions with substantially fewer effective denoising iterations. Across simulation benchmarks (LIBERO, VLABench) and real robots (Franka, AgiBot), A1 achieves state-of-the-art success rates while significantly reducing inference cost (e.g., up to 72% lower per-episode latency for flow-matching inference and up to 76.6% backbone computation reduction with minor performance degradation). On RoboChallenge, A1 achieves an average success rate of 29.00%, outperforming baselines including pi0(28.33%), X-VLA (21.33%), and RDT-1B (15.00%).
Semantic One-Dimensional Tokenizer for Image Reconstruction and Generation
Mar 17, 2026Visual generative models based on latent space have achieved great success, underscoring the significance of visual tokenization. Mapping images to latents boosts efficiency and enables multimodal alignment for scaling up in downstream tasks. Existing visual tokenizers primarily map images into fixed 2D spatial grids and focus on pixel-level restoration, which hinders the capture of representations with compact global semantics. To address these issues, we propose \textbf{SemTok}, a semantic one-dimensional tokenizer that compresses 2D images into 1D discrete tokens with high-level semantics. SemTok sets a new state-of-the-art in image reconstruction, achieving superior fidelity with a remarkably compact token representation. This is achieved via a synergistic framework with three key innovations: a 2D-to-1D tokenization scheme, a semantic alignment constraint, and a two-stage generative training strategy. Building on SemTok, we construct a masked autoregressive generation framework, which yields notable improvements in downstream image generation tasks. Experiments confirm the effectiveness of our semantic 1D tokenization. Our code will be open-sourced.
Mind the Generative Details: Direct Localized Detail Preference Optimization for Video Diffusion Models
Jan 08, 2026Aligning text-to-video diffusion models with human preferences is crucial for generating high-quality videos. Existing Direct Preference Otimization (DPO) methods rely on multi-sample ranking and task-specific critic models, which is inefficient and often yields ambiguous global supervision. To address these limitations, we propose LocalDPO, a novel post-training framework that constructs localized preference pairs from real videos and optimizes alignment at the spatio-temporal region level. We design an automated pipeline to efficiently collect preference pair data that generates preference pairs with a single inference per prompt, eliminating the need for external critic models or manual annotation. Specifically, we treat high-quality real videos as positive samples and generate corresponding negatives by locally corrupting them with random spatio-temporal masks and restoring only the masked regions using the frozen base model. During training, we introduce a region-aware DPO loss that restricts preference learning to corrupted areas for rapid convergence. Experiments on Wan2.1 and CogVideoX demonstrate that LocalDPO consistently improves video fidelity, temporal coherence and human preference scores over other post-training approaches, establishing a more efficient and fine-grained paradigm for video generator alignment.
RoBridge: A Hierarchical Architecture Bridging Cognition and Execution for General Robotic Manipulation
May 03, 2025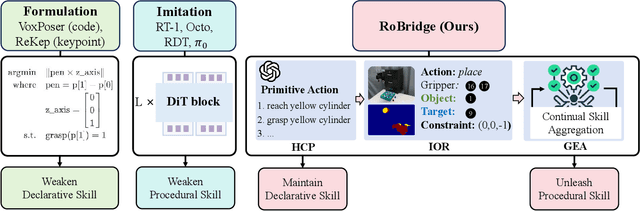
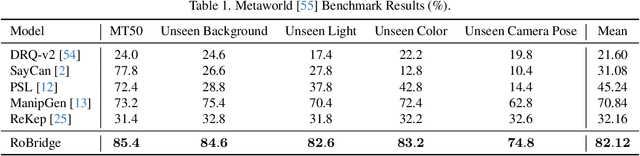
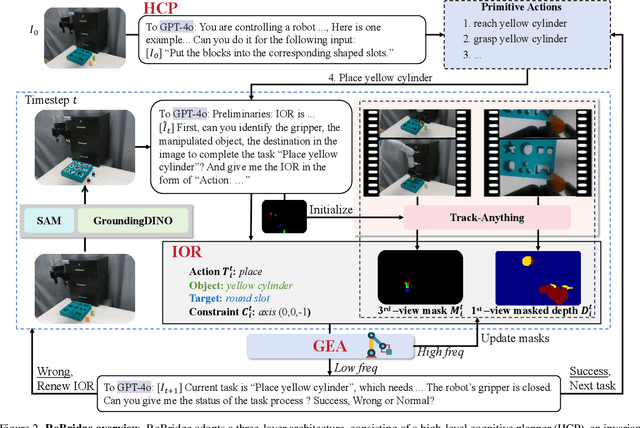
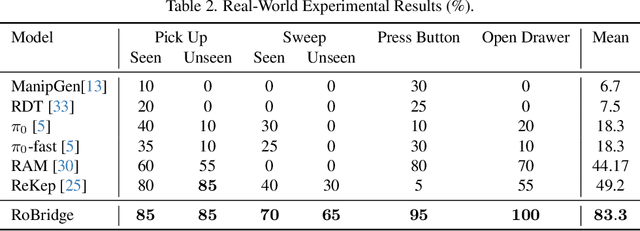
Operating robots in open-ended scenarios with diverse tasks is a crucial research and application direction in robotics. While recent progress in natural language processing and large multimodal models has enhanced robots' ability to understand complex instructions, robot manipulation still faces the procedural skill dilemma and the declarative skill dilemma in open environments. Existing methods often compromise cognitive and executive capabilities. To address these challenges, in this paper, we propose RoBridge, a hierarchical intelligent architecture for general robotic manipulation. It consists of a high-level cognitive planner (HCP) based on a large-scale pre-trained vision-language model (VLM), an invariant operable representation (IOR) serving as a symbolic bridge, and a generalist embodied agent (GEA). RoBridge maintains the declarative skill of VLM and unleashes the procedural skill of reinforcement learning, effectively bridging the gap between cognition and execution. RoBridge demonstrates significant performance improvements over existing baselines, achieving a 75% success rate on new tasks and an 83% average success rate in sim-to-real generalization using only five real-world data samples per task. This work represents a significant step towards integrating cognitive reasoning with physical execution in robotic systems, offering a new paradigm for general robotic manipulation.
A0: An Affordance-Aware Hierarchical Model for General Robotic Manipulation
Apr 21, 2025



Robotic manipulation faces critical challenges in understanding spatial affordances--the "where" and "how" of object interactions--essential for complex manipulation tasks like wiping a board or stacking objects. Existing methods, including modular-based and end-to-end approaches, often lack robust spatial reasoning capabilities. Unlike recent point-based and flow-based affordance methods that focus on dense spatial representations or trajectory modeling, we propose A0, a hierarchical affordance-aware diffusion model that decomposes manipulation tasks into high-level spatial affordance understanding and low-level action execution. A0 leverages the Embodiment-Agnostic Affordance Representation, which captures object-centric spatial affordances by predicting contact points and post-contact trajectories. A0 is pre-trained on 1 million contact points data and fine-tuned on annotated trajectories, enabling generalization across platforms. Key components include Position Offset Attention for motion-aware feature extraction and a Spatial Information Aggregation Layer for precise coordinate mapping. The model's output is executed by the action execution module. Experiments on multiple robotic systems (Franka, Kinova, Realman, and Dobot) demonstrate A0's superior performance in complex tasks, showcasing its efficiency, flexibility, and real-world applicability.
InfiniteWorld: A Unified Scalable Simulation Framework for General Visual-Language Robot Interaction
Dec 08, 2024



Realizing scaling laws in embodied AI has become a focus. However, previous work has been scattered across diverse simulation platforms, with assets and models lacking unified interfaces, which has led to inefficiencies in research. To address this, we introduce InfiniteWorld, a unified and scalable simulator for general vision-language robot interaction built on Nvidia Isaac Sim. InfiniteWorld encompasses a comprehensive set of physics asset construction methods and generalized free robot interaction benchmarks. Specifically, we first built a unified and scalable simulation framework for embodied learning that integrates a series of improvements in generation-driven 3D asset construction, Real2Sim, automated annotation framework, and unified 3D asset processing. This framework provides a unified and scalable platform for robot interaction and learning. In addition, to simulate realistic robot interaction, we build four new general benchmarks, including scene graph collaborative exploration and open-world social mobile manipulation. The former is often overlooked as an important task for robots to explore the environment and build scene knowledge, while the latter simulates robot interaction tasks with different levels of knowledge agents based on the former. They can more comprehensively evaluate the embodied agent's capabilities in environmental understanding, task planning and execution, and intelligent interaction. We hope that this work can provide the community with a systematic asset interface, alleviate the dilemma of the lack of high-quality assets, and provide a more comprehensive evaluation of robot interactions.
NeRF Inpainting with Geometric Diffusion Prior and Balanced Score Distillation
Nov 23, 2024



Recent advances in NeRF inpainting have leveraged pretrained diffusion models to enhance performance. However, these methods often yield suboptimal results due to their ineffective utilization of 2D diffusion priors. The limitations manifest in two critical aspects: the inadequate capture of geometric information by pretrained diffusion models and the suboptimal guidance provided by existing Score Distillation Sampling (SDS) methods. To address these problems, we introduce GB-NeRF, a novel framework that enhances NeRF inpainting through improved utilization of 2D diffusion priors. Our approach incorporates two key innovations: a fine-tuning strategy that simultaneously learns appearance and geometric priors and a specialized normal distillation loss that integrates these geometric priors into NeRF inpainting. We propose a technique called Balanced Score Distillation (BSD) that surpasses existing methods such as Score Distillation (SDS) and the improved version, Conditional Score Distillation (CSD). BSD offers improved inpainting quality in appearance and geometric aspects. Extensive experiments show that our method provides superior appearance fidelity and geometric consistency compared to existing approaches.
StableV2V: Stablizing Shape Consistency in Video-to-Video Editing
Nov 17, 2024Recent advancements of generative AI have significantly promoted content creation and editing, where prevailing studies further extend this exciting progress to video editing. In doing so, these studies mainly transfer the inherent motion patterns from the source videos to the edited ones, where results with inferior consistency to user prompts are often observed, due to the lack of particular alignments between the delivered motions and edited contents. To address this limitation, we present a shape-consistent video editing method, namely StableV2V, in this paper. Our method decomposes the entire editing pipeline into several sequential procedures, where it edits the first video frame, then establishes an alignment between the delivered motions and user prompts, and eventually propagates the edited contents to all other frames based on such alignment. Furthermore, we curate a testing benchmark, namely DAVIS-Edit, for a comprehensive evaluation of video editing, considering various types of prompts and difficulties. Experimental results and analyses illustrate the outperforming performance, visual consistency, and inference efficiency of our method compared to existing state-of-the-art studies.
PIVOT-R: Primitive-Driven Waypoint-Aware World Model for Robotic Manipulation
Oct 14, 2024



Language-guided robotic manipulation is a challenging task that requires an embodied agent to follow abstract user instructions to accomplish various complex manipulation tasks. Previous work trivially fitting the data without revealing the relation between instruction and low-level executable actions, these models are prone to memorizing the surficial pattern of the data instead of acquiring the transferable knowledge, and thus are fragile to dynamic environment changes. To address this issue, we propose a PrIrmitive-driVen waypOinT-aware world model for Robotic manipulation (PIVOT-R) that focuses solely on the prediction of task-relevant waypoints. Specifically, PIVOT-R consists of a Waypoint-aware World Model (WAWM) and a lightweight action prediction module. The former performs primitive action parsing and primitive-driven waypoint prediction, while the latter focuses on decoding low-level actions. Additionally, we also design an asynchronous hierarchical executor (AHE), which can use different execution frequencies for different modules of the model, thereby helping the model reduce computational redundancy and improve model execution efficiency. Our PIVOT-R outperforms state-of-the-art (SoTA) open-source models on the SeaWave benchmark, achieving an average relative improvement of 19.45% across four levels of instruction tasks. Moreover, compared to the synchronously executed PIVOT-R, the execution efficiency of PIVOT-R with AHE is increased by 28-fold, with only a 2.9% drop in performance. These results provide compelling evidence that our PIVOT-R can significantly improve both the performance and efficiency of robotic manipulation.