 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffectSeek: Agentic Affective Understanding in Long Videos under Vague User Queries
May 07, 2026Existing affective understanding studies have mainly focused on recognizing emotions from images, audio signals, or pre-cliped video clips, where the affective evidence is already given. This passive and clip-centered setting does not fully reflect real-world scenarios, in which users often interact with long videos and express their needs through natural-language queries. In this paper, we study \textbf{Vague-Query-driven video Affective Understanding (VQAU)}, a new task that requires models to localize affective moments in long videos, predict their emotion categories, and generate evidence-grounded rationales under vague user queries. To support this task, we construct \textbf{VQAU-Bench}, a benchmark that integrates long videos, vague affective queries, temporal clip annotations, emotion labels, and rationale explanations into a unified evaluation framework. VQAU-Bench enables systematic assessment of semantic-temporal-affective alignment, affective moment localization, emotion classification, and rationale generation. To address the multi-step reasoning challenges of VQAU, we further propose \textbf{AffectSeek}, an agentic framework that actively seeks, verifies, and explains affective moments in long videos. AffectSeek decomposes VQAU into intent interpretation, candidate localization, clip verification, emotion reasoning, and rationale generation, and progressively aligns vague user intent with long-video evidence through role-specialized reasoning and cross-stage verification. Experiments show that VQAU remains challenging for existing affective recognition models and single-step vision-language models, while AffectSeek provides a simple yet effective framework for agentic long-video affective understanding.
SensingAgents: A Multi-Agent Collaborative Framework for Robust IMU Activity Recognition
May 06, 2026Human Activity Recognition (HAR) using Inertial Measurement Unit (IMU) sensors is a cornerstone of mobile health, smart environments, and human-computer interaction. However, current deep learning-based HAR models often struggle with heavy reliance on labeled data, position-specific ambiguity, and a lack of transparent reasoning. Inspired by the advanced agents framework, which emulates a collaborative agent using Large Language Models (LLMs), we propose SensingAgents, a novel multi-agent system for robust IMU activity recognition. SensingAgents organizes LLM-powered agents into specialized roles: a group of Analyst Agents for position-specific sensor analysis (arm, wrist, belt, pocket), a pair of Advocate Agents that resolves sensor conflicts through dynamic and static dialectical debates, and a Decision Agent that ensures reliability under sensor drift or failure. Evaluation on the Shoaib dataset demonstrates that SensingAgents significantly outperforms state-of-the-art single-agent and multi-agent LLM models, achieving an accuracy of 79.5% in a zero setting--29% higher than existing agent models and 9.4% higher than deep learning baselines--particularly in complex scenarios where multi-sensor data is conflicting or noisy. Our work highlights the potential of multi-agent collaborative reasoning for advancing the robustness and interpretability of ubiquitous sensing systems.
Well Begun is Half Done: Training-Free and Model-Agnostic Semantically Guaranteed User Representation Initialization for Multimodal Recommendation
Apr 16, 2026Recent advancements in multimodal recommendations, which leverage diverse modality information to mitigate data sparsity and improve recommendation accuracy, have gained significant attention. However, existing multimodal recommendations overlook the critical role of user representation initialization. Unlike items, which are naturally associated with rich modality information, users lack such inherent information. Consequently, item representations initialized based on meaningful modality information and user representations initialized randomly exhibit a significant semantic gap. To this end, we propose a Semantically Guaranteed User Representation Initialization (SG-URInit). SG-URInit constructs the initial representation for each user by integrating both the modality features of the items they have interacted with and the global features of their corresponding clusters. SG-URInit enables the initialization of semantically enriched user representations that effectively capture both local (item-level) and global (cluster-level) semantics. Our SG-URInit is training-free and model-agnostic, meaning it can be seamlessly integrated into existing multimodal recommendation models without incurring any additional computational overhead during training. Extensive experiments on multiple real-world datasets demonstrate that incorporating SG-URInit into advanced multimodal recommendation models significantly enhances recommendation performance. Furthermore, the results show that SG-URInit can further alleviate the item cold-start problem and also accelerate model convergence, making it an efficient and practical solution for multimodal recommendations.
Sparse Shortcuts: Facilitating Efficient Fusion in Multimodal Large Language Models
Jan 31, 2026With the remarkable success of large language models (LLMs) in natural language understanding and generation, multimodal large language models (MLLMs) have rapidly advanced in their ability to process data across multiple modalities. While most existing efforts focus on scaling up language models or constructing higher-quality training data, limited attention has been paid to effectively integrating cross-modal knowledge into the language space. In vision-language models, for instance, aligning modalities using only high-level visual features often discards the rich semantic information present in mid- and low-level features, limiting the model's ability of cross-modality understanding. To address this issue, we propose SparseCut, a general cross-modal fusion architecture for MLLMs, introducing sparse shortcut connections between the cross-modal encoder and the LLM. These shortcut connections enable the efficient and hierarchical integration of visual features at multiple levels, facilitating richer semantic fusion without increasing computational overhead. We further introduce an efficient multi-grained feature fusion module, which performs the fusion of visual features before routing them through the shortcuts. This preserves the original language context and does not increase the overall input length, thereby avoiding an increase in computational complexity for the LLM. Experiments demonstrate that SparseCut significantly enhances the performance of MLLMs across various multimodal benchmarks with generality and scalability for different base LLMs.
Opening the Black Box: Preliminary Insights into Affective Modeling in Multimodal Foundation Models
Jan 22, 2026Understanding where and how emotions are represented in large-scale foundation models remains an open problem, particularly in multimodal affective settings. Despite the strong empirical performance of recent affective models, the internal architectural mechanisms that support affective understanding and generation are still poorly understood. In this work, we present a systematic mechanistic study of affective modeling in multimodal foundation models. Across multiple architectures, training strategies, and affective tasks, we analyze how emotion-oriented supervision reshapes internal model parameters. Our results consistently reveal a clear and robust pattern: affective adaptation does not primarily focus on the attention module, but instead localizes to the feed-forward gating projection (\texttt{gate\_proj}). Through controlled module transfer, targeted single-module adaptation, and destructive ablation, we further demonstrate that \texttt{gate\_proj} is sufficient, efficient, and necessary for affective understanding and generation. Notably, by tuning only approximately 24.5\% of the parameters tuned by AffectGPT, our approach achieves 96.6\% of its average performance across eight affective tasks, highlighting substantial parameter efficiency. Together, these findings provide empirical evidence that affective capabilities in foundation models are structurally mediated by feed-forward gating mechanisms and identify \texttt{gate\_proj} as a central architectural locus of affective modeling.
Revisiting Cross-Architecture Distillation: Adaptive Dual-Teacher Transfer for Lightweight Video Models
Nov 12, 2025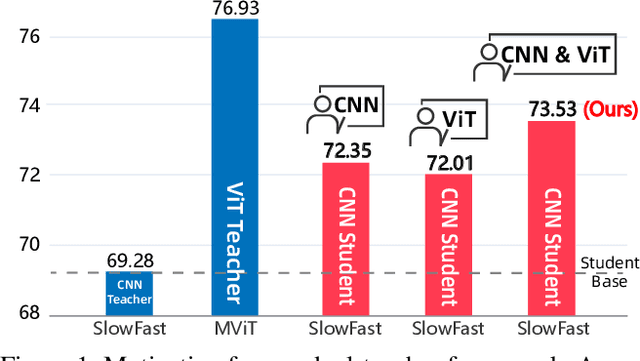

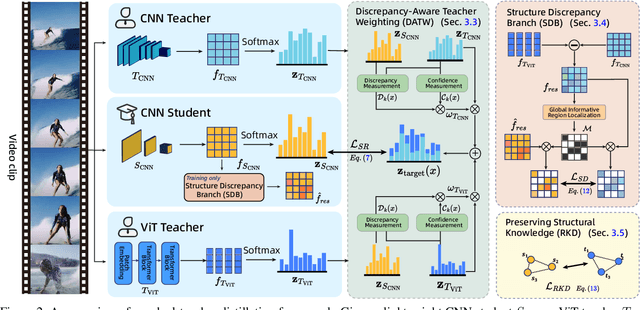

Vision Transformers (ViTs) have achieved strong performance in video action recognition, but their high computational cost limits their practicality. Lightweight CNNs are more efficient but suffer from accuracy gaps. Cross-Architecture Knowledge Distillation (CAKD) addresses this by transferring knowledge from ViTs to CNNs, yet existing methods often struggle with architectural mismatch and overlook the value of stronger homogeneous CNN teachers. To tackle these challenges, we propose a Dual-Teacher Knowledge Distillation framework that leverages both a heterogeneous ViT teacher and a homogeneous CNN teacher to collaboratively guide a lightweight CNN student. We introduce two key components: (1) Discrepancy-Aware Teacher Weighting, which dynamically fuses the predictions from ViT and CNN teachers by assigning adaptive weights based on teacher confidence and prediction discrepancy with the student, enabling more informative and effective supervision; and (2) a Structure Discrepancy-Aware Distillation strategy, where the student learns the residual features between ViT and CNN teachers via a lightweight auxiliary branch, focusing on transferable architectural differences without mimicking all of ViT's high-dimensional patterns. Extensive experiments on benchmarks including HMDB51, EPIC-KITCHENS-100, and Kinetics-400 demonstrate that our method consistently outperforms state-of-the-art distillation approaches, achieving notable performance improvements with a maximum accuracy gain of 5.95% on HMDB51.
FedSM: Robust Semantics-Guided Feature Mixup for Bias Reduction in Federated Learning with Long-Tail Data
Oct 31, 2025Federated Learning (FL) enables collaborative model training across decentralized clients without sharing private data. However, FL suffers from biased global models due to non-IID and long-tail data distributions. We propose \textbf{FedSM}, a novel client-centric framework that mitigates this bias through semantics-guided feature mixup and lightweight classifier retraining. FedSM uses a pretrained image-text-aligned model to compute category-level semantic relevance, guiding the category selection of local features to mix-up with global prototypes to generate class-consistent pseudo-features. These features correct classifier bias, especially when data are heavily skewed. To address the concern of potential domain shift between the pretrained model and the data, we propose probabilistic category selection, enhancing feature diversity to effectively mitigate biases. All computations are performed locally, requiring minimal server overhead. Extensive experiments on long-tail datasets with various imbalanced levels demonstrate that FedSM consistently outperforms state-of-the-art methods in accuracy, with high robustness to domain shift and computational efficiency.
Emotion Recognition from Skeleton Data: A Comprehensive Survey
Jul 24, 2025Emotion recognition through body movements has emerged as a compelling and privacy-preserving alternative to traditional methods that rely on facial expressions or physiological signals. Recent advancements in 3D skeleton acquisition technologies and pose estimation algorithms have significantly enhanced the feasibility of emotion recognition based on full-body motion. This survey provides a comprehensive and systematic review of skeleton-based emotion recognition techniques. First, we introduce psychological models of emotion and examine the relationship between bodily movements and emotional expression. Next, we summarize publicly available datasets, highlighting the differences in data acquisition methods and emotion labeling strategies. We then categorize existing methods into posture-based and gait-based approaches, analyzing them from both data-driven and technical perspectives. In particular, we propose a unified taxonomy that encompasses four primary technical paradigms: Traditional approaches, Feat2Net, FeatFusionNet, and End2EndNet. Representative works within each category are reviewed and compared, with benchmarking results across commonly used datasets. Finally, we explore the extended applications of emotion recognition in mental health assessment, such as detecting depression and autism, and discuss the open challenges and future research directions in this rapidly evolving field.
NLGCL: Naturally Existing Neighbor Layers Graph Contrastive Learning for Recommendation
Jul 10, 2025



Graph Neural Networks (GNNs) are widely used in collaborative filtering to capture high-order user-item relationships. To address the data sparsity problem in recommendation systems, Graph Contrastive Learning (GCL) has emerged as a promising paradigm that maximizes mutual information between contrastive views. However, existing GCL methods rely on augmentation techniques that introduce semantically irrelevant noise and incur significant computational and storage costs, limiting effectiveness and efficiency. To overcome these challenges, we propose NLGCL, a novel contrastive learning framework that leverages naturally contrastive views between neighbor layers within GNNs. By treating each node and its neighbors in the next layer as positive pairs, and other nodes as negatives, NLGCL avoids augmentation-based noise while preserving semantic relevance. This paradigm eliminates costly view construction and storage, making it computationally efficient and practical for real-world scenarios. Extensive experiments on four public datasets demonstrate that NLGCL outperforms state-of-the-art baselines in effectiveness and efficiency.
Exploring Audio Cues for Enhanced Test-Time Video Model Adaptation
Jun 14, 2025Test-time adaptation (TTA) aims to boost the generalization capability of a trained model by conducting self-/unsupervised learning during the testing phase. While most existing TTA methods for video primarily utilize visual supervisory signals, they often overlook the potential contribution of inherent audio data. To address this gap, we propose a novel approach that incorporates audio information into video TTA. Our method capitalizes on the rich semantic content of audio to generate audio-assisted pseudo-labels, a new concept in the context of video TTA. Specifically, we propose an audio-to-video label mapping method by first employing pre-trained audio models to classify audio signals extracted from videos and then mapping the audio-based predictions to video label spaces through large language models, thereby establishing a connection between the audio categories and video labels. To effectively leverage the generated pseudo-labels, we present a flexible adaptation cycle that determines the optimal number of adaptation iterations for each sample, based on changes in loss and consistency across different views. This enables a customized adaptation process for each sample. Experimental results on two widely used datasets (UCF101-C and Kinetics-Sounds-C), as well as on two newly constructed audio-video TTA datasets (AVE-C and AVMIT-C) with various corruption types, demonstrate the superiority of our approach. Our method consistently improves adaptation performance across different video classification models and represents a significant step forward in integrating audio information into video TTA. Code: https://github.com/keikeiqi/Audio-Assisted-TTA.