 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning with Counterfactual Explanations for Radiology Report Generation
Jul 19, 2024



Due to the common content of anatomy, radiology images with their corresponding reports exhibit high similarity. Such inherent data bias can predispose automatic report generation models to learn entangled and spurious representations resulting in misdiagnostic reports. To tackle these, we propose a novel \textbf{Co}unter\textbf{F}actual \textbf{E}xplanations-based framework (CoFE) for radiology report generation. Counterfactual explanations serve as a potent tool for understanding how decisions made by algorithms can be changed by asking ``what if'' scenarios. By leveraging this concept, CoFE can learn non-spurious visual representations by contrasting the representations between factual and counterfactual images. Specifically, we derive counterfactual images by swapping a patch between positive and negative samples until a predicted diagnosis shift occurs. Here, positive and negative samples are the most semantically similar but have different diagnosis labels. Additionally, CoFE employs a learnable prompt to efficiently fine-tune the pre-trained large language model, encapsulating both factual and counterfactual content to provide a more generalizable prompt representation. Extensive experiments on two benchmarks demonstrate that leveraging the counterfactual explanations enables CoFE to generate semantically coherent and factually complete reports and outperform in terms of language generation and clinical efficacy metrics.
Noise-Tolerant Unsupervised Adapter for Vision-Language Models
Sep 26, 2023



Recent advances in large-scale vision-language models have achieved very impressive performance in various zero-shot image classification tasks. While prior studies have demonstrated significant improvements by introducing few-shot labelled target samples, they still require labelling of target samples, which greatly degrades their scalability while handling various visual recognition tasks. We design NtUA, a Noise-tolerant Unsupervised Adapter that allows learning superior target models with few-shot unlabelled target samples. NtUA works as a key-value cache that formulates visual features and predicted pseudo-labels of the few-shot unlabelled target samples as key-value pairs. It consists of two complementary designs. The first is adaptive cache formation that combats pseudo-label noises by weighting the key-value pairs according to their prediction confidence. The second is pseudo-label rectification, which corrects both pair values (i.e., pseudo-labels) and cache weights by leveraging knowledge distillation from large-scale vision language models. Extensive experiments show that NtUA achieves superior performance consistently across multiple widely adopted benchmarks.
DC-Net: Divide-and-Conquer for Salient Object Detection
May 24, 2023



In this paper, we introduce Divide-and-Conquer into the salient object detection (SOD) task to enable the model to learn prior knowledge that is for predicting the saliency map. We design a novel network, Divide-and-Conquer Network (DC-Net) which uses two encoders to solve different subtasks that are conducive to predicting the final saliency map, here is to predict the edge maps with width 4 and location maps of salient objects and then aggregate the feature maps with different semantic information into the decoder to predict the final saliency map. The decoder of DC-Net consists of our newly designed two-level Residual nested-ASPP (ResASPP$^{2}$) modules, which have the ability to capture a large number of different scale features with a small number of convolution operations and have the advantages of maintaining high resolution all the time and being able to obtain a large and compact effective receptive field (ERF). Based on the advantage of Divide-and-Conquer's parallel computing, we use Parallel Acceleration to speed up DC-Net, allowing it to achieve competitive performance on six LR-SOD and five HR-SOD datasets under high efficiency (60 FPS and 55 FPS). Codes and results are available: https://github.com/PiggyJerry/DC-Net.
Semi-Supervised Cross-Modal Salient Object Detection with U-Structure Networks
Aug 08, 2022
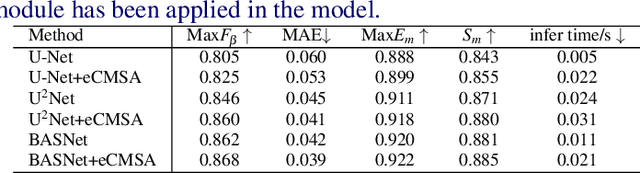

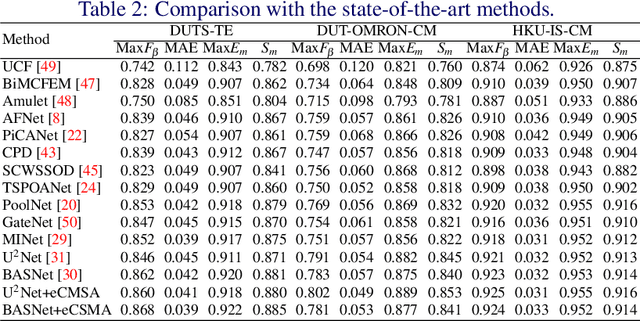
Salient Object Detection (SOD) is a popular and important topic aimed at precise detection and segmentation of the interesting regions in the images. We integrate the linguistic information into the vision-based U-Structure networks designed for salient object detection tasks. The experiments are based on the newly created DUTS Cross Modal (DUTS-CM) dataset, which contains both visual and linguistic labels. We propose a new module called efficient Cross-Modal Self-Attention (eCMSA) to combine visual and linguistic features and improve the performance of the original U-structure networks. Meanwhile, to reduce the heavy burden of labeling, we employ a semi-supervised learning method by training an image caption model based on the DUTS-CM dataset, which can automatically label other datasets like DUT-OMRON and HKU-IS. The comprehensive experiments show that the performance of SOD can be improved with the natural language input and is competitive compared with other SOD methods.