 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBytes are All You Need: End-to-End Multilingual Speech Recognition and Synthesis with Bytes
Nov 22, 2018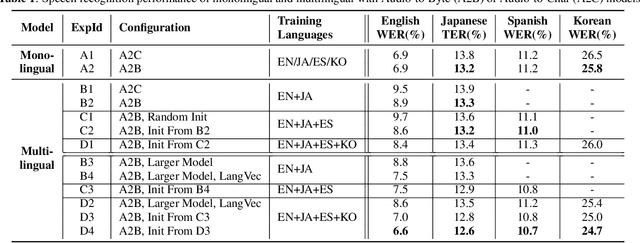

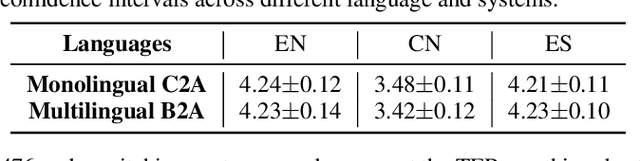
We present two end-to-end models: Audio-to-Byte (A2B) and Byte-to-Audio (B2A), for multilingual speech recognition and synthesis. Prior work has predominantly used characters, sub-words or words as the unit of choice to model text. These units are difficult to scale to languages with large vocabularies, particularly in the case of multilingual processing. In this work, we model text via a sequence of Unicode bytes, specifically, the UTF-8 variable length byte sequence for each character. Bytes allow us to avoid large softmaxes in languages with large vocabularies, and share representations in multilingual models. We show that bytes are superior to grapheme characters over a wide variety of languages in monolingual end-to-end speech recognition. Additionally, our multilingual byte model outperform each respective single language baseline on average by 4.4% relatively. In Japanese-English code-switching speech, our multilingual byte model outperform our monolingual baseline by 38.6% relatively. Finally, we present an end-to-end multilingual speech synthesis model using byte representations which matches the performance of our monolingual baselines.
Optimal Completion Distillation for Sequence Learning
Oct 02, 2018
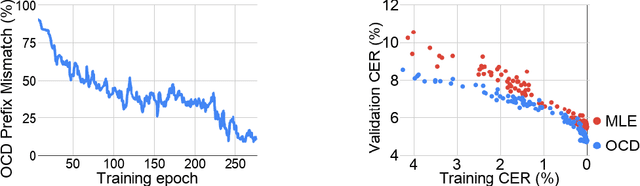

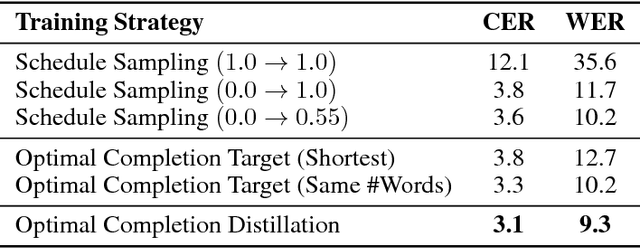
We present Optimal Completion Distillation (OCD), a training procedure for optimizing sequence to sequence models based on edit distance. OCD is efficient, has no hyper-parameters of its own, and does not require pretraining or joint optimization with conditional log-likelihood. Given a partial sequence generated by the model, we first identify the set of optimal suffixes that minimize the total edit distance, using an efficient dynamic programming algorithm. Then, for each position of the generated sequence, we use a target distribution that puts equal probability on the first token of all the optimal suffixes. OCD achieves the state-of-the-art performance on end-to-end speech recognition, on both Wall Street Journal and Librispeech datasets, achieving $9.3\%$ WER and $4.5\%$ WER respectively.
Advances in Joint CTC-Attention based End-to-End Speech Recognition with a Deep CNN Encoder and RNN-LM
Jun 08, 2017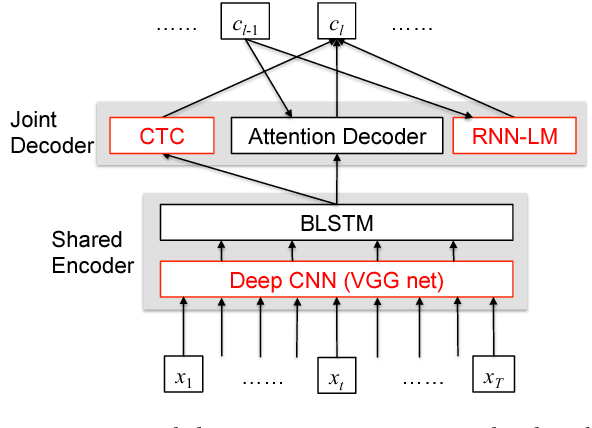
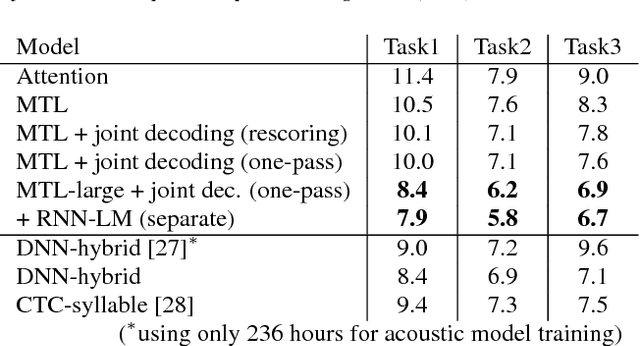
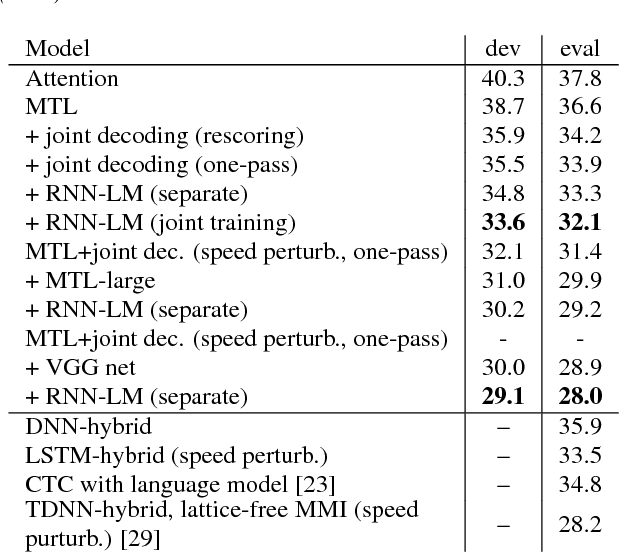
We present a state-of-the-art end-to-end Automatic Speech Recognition (ASR) model. We learn to listen and write characters with a joint Connectionist Temporal Classification (CTC) and attention-based encoder-decoder network. The encoder is a deep Convolutional Neural Network (CNN) based on the VGG network. The CTC network sits on top of the encoder and is jointly trained with the attention-based decoder. During the beam search process, we combine the CTC predictions, the attention-based decoder predictions and a separately trained LSTM language model. We achieve a 5-10\% error reduction compared to prior systems on spontaneous Japanese and Chinese speech, and our end-to-end model beats out traditional hybrid ASR systems.
Latent Sequence Decompositions
Feb 07, 2017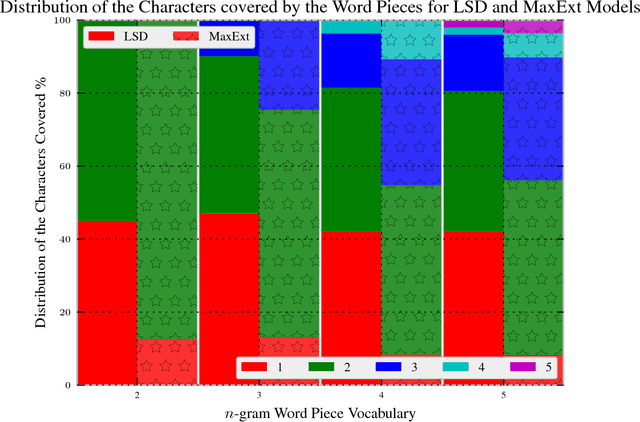
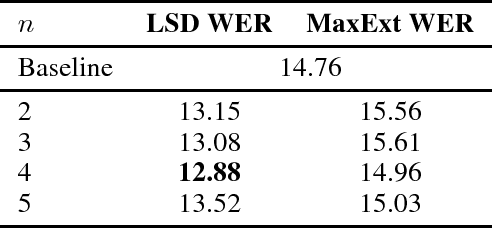
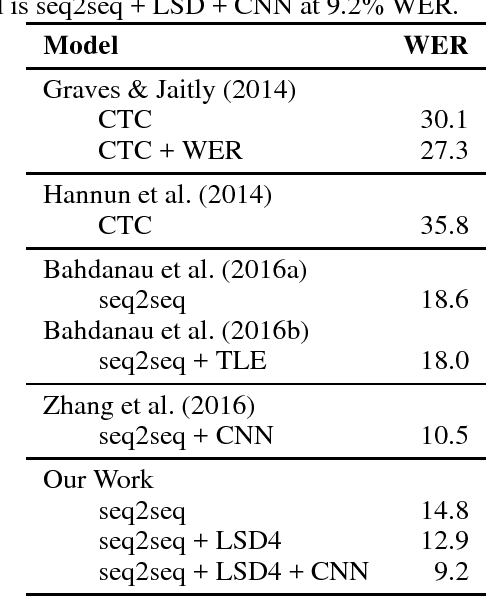
We present the Latent Sequence Decompositions (LSD) framework. LSD decomposes sequences with variable lengthed output units as a function of both the input sequence and the output sequence. We present a training algorithm which samples valid extensions and an approximate decoding algorithm. We experiment with the Wall Street Journal speech recognition task. Our LSD model achieves 12.9% WER compared to a character baseline of 14.8% WER. When combined with a convolutional network on the encoder, we achieve 9.6% WER.
Very Deep Convolutional Networks for End-to-End Speech Recognition
Oct 10, 2016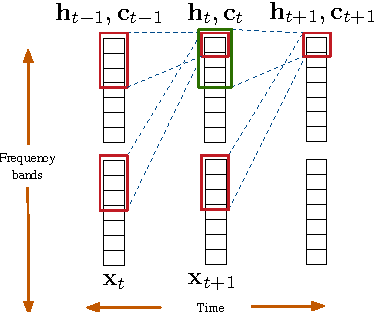
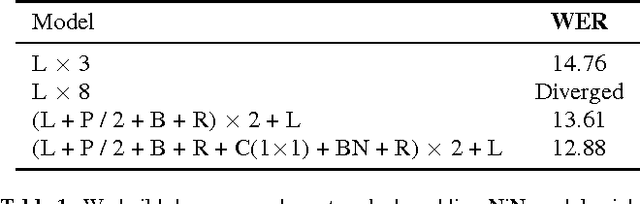
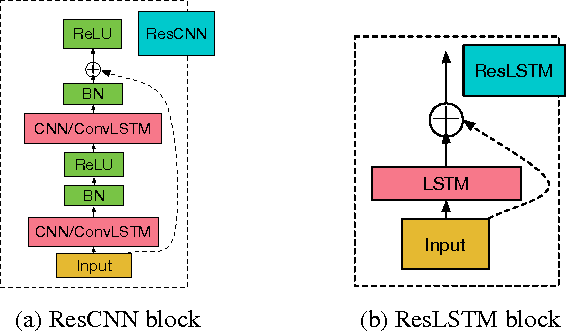

Sequence-to-sequence models have shown success in end-to-end speech recognition. However these models have only used shallow acoustic encoder networks. In our work, we successively train very deep convolutional networks to add more expressive power and better generalization for end-to-end ASR models. We apply network-in-network principles, batch normalization, residual connections and convolutional LSTMs to build very deep recurrent and convolutional structures. Our models exploit the spectral structure in the feature space and add computational depth without overfitting issues. We experiment with the WSJ ASR task and achieve 10.5\% word error rate without any dictionary or language using a 15 layer deep network.
Listen, Attend and Spell
Aug 20, 2015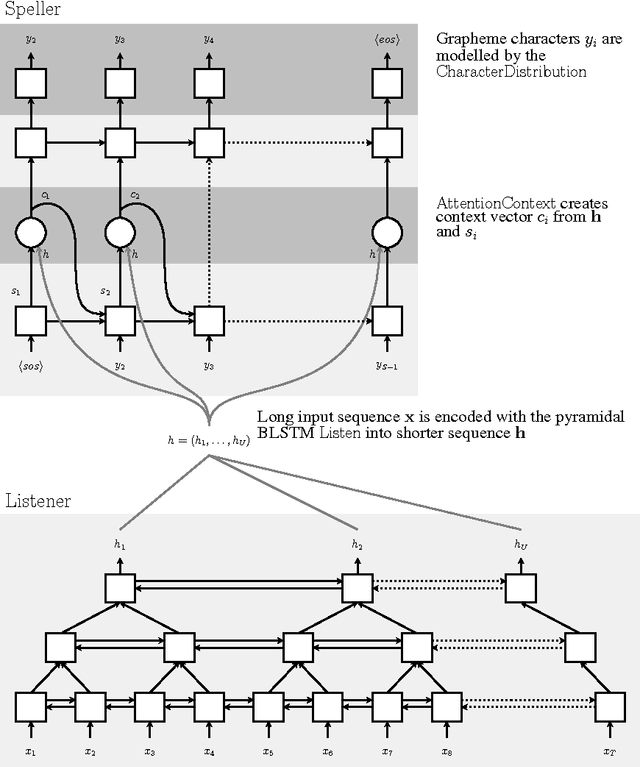
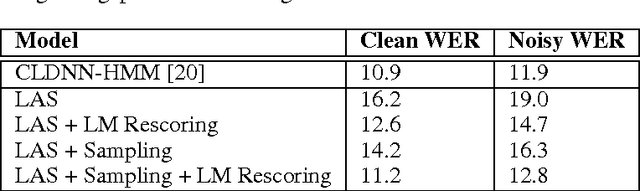
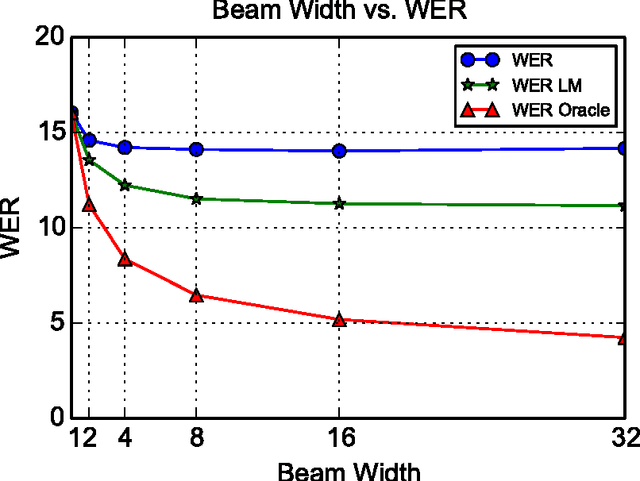

We present Listen, Attend and Spell (LAS), a neural network that learns to transcribe speech utterances to characters. Unlike traditional DNN-HMM models, this model learns all the components of a speech recognizer jointly. Our system has two components: a listener and a speller. The listener is a pyramidal recurrent network encoder that accepts filter bank spectra as inputs. The speller is an attention-based recurrent network decoder that emits characters as outputs. The network produces character sequences without making any independence assumptions between the characters. This is the key improvement of LAS over previous end-to-end CTC models. On a subset of the Google voice search task, LAS achieves a word error rate (WER) of 14.1% without a dictionary or a language model, and 10.3% with language model rescoring over the top 32 beams. By comparison, the state-of-the-art CLDNN-HMM model achieves a WER of 8.0%.
Transferring Knowledge from a RNN to a DNN
Apr 07, 2015
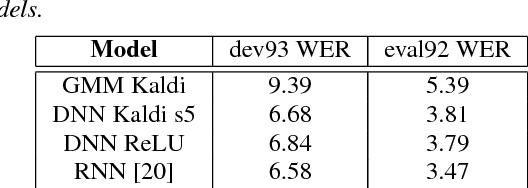
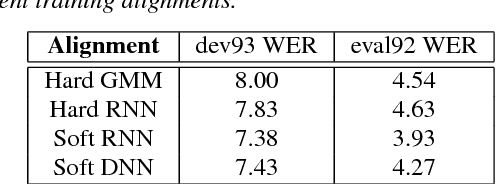
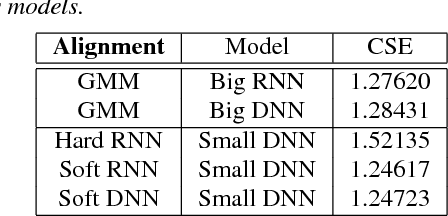
Deep Neural Network (DNN) acoustic models have yielded many state-of-the-art results in Automatic Speech Recognition (ASR) tasks. More recently, Recurrent Neural Network (RNN) models have been shown to outperform DNNs counterparts. However, state-of-the-art DNN and RNN models tend to be impractical to deploy on embedded systems with limited computational capacity. Traditionally, the approach for embedded platforms is to either train a small DNN directly, or to train a small DNN that learns the output distribution of a large DNN. In this paper, we utilize a state-of-the-art RNN to transfer knowledge to small DNN. We use the RNN model to generate soft alignments and minimize the Kullback-Leibler divergence against the small DNN. The small DNN trained on the soft RNN alignments achieved a 3.93 WER on the Wall Street Journal (WSJ) eval92 task compared to a baseline 4.54 WER or more than 13% relative improvement.
Deep Recurrent Neural Networks for Acoustic Modelling
Apr 07, 2015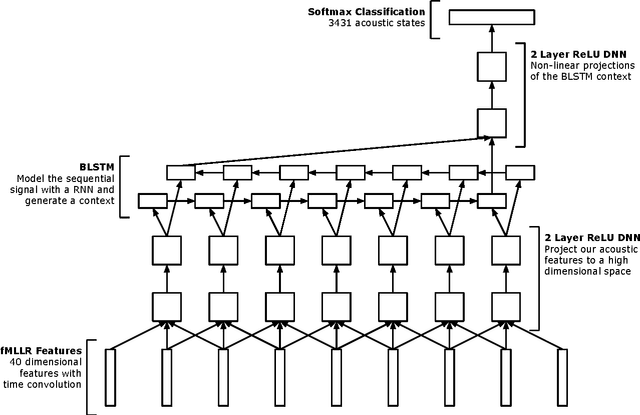

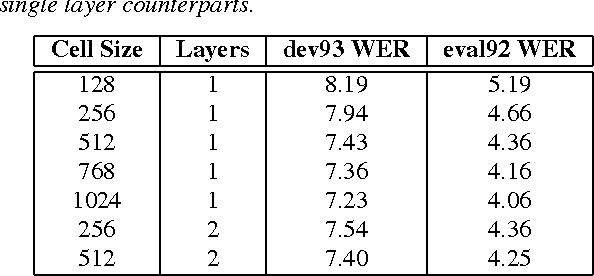
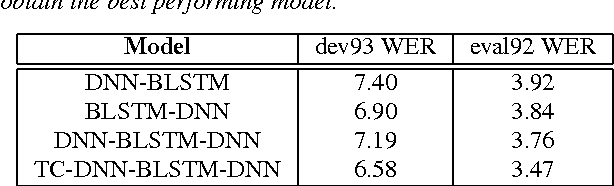
We present a novel deep Recurrent Neural Network (RNN) model for acoustic modelling in Automatic Speech Recognition (ASR). We term our contribution as a TC-DNN-BLSTM-DNN model, the model combines a Deep Neural Network (DNN) with Time Convolution (TC), followed by a Bidirectional Long Short-Term Memory (BLSTM), and a final DNN. The first DNN acts as a feature processor to our model, the BLSTM then generates a context from the sequence acoustic signal, and the final DNN takes the context and models the posterior probabilities of the acoustic states. We achieve a 3.47 WER on the Wall Street Journal (WSJ) eval92 task or more than 8% relative improvement over the baseline DNN models.
Leveraging Subjective Human Annotation for Clustering Historic Newspaper Articles
Aug 17, 2012
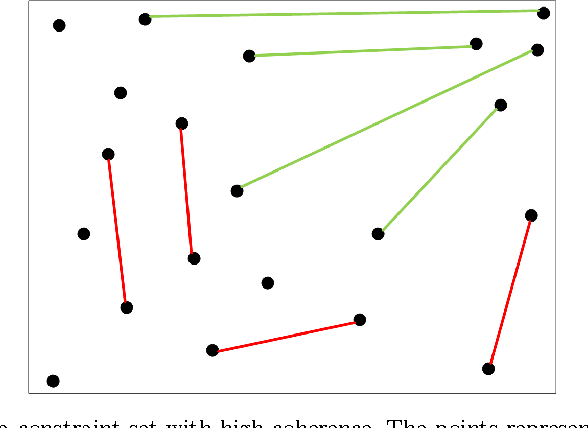
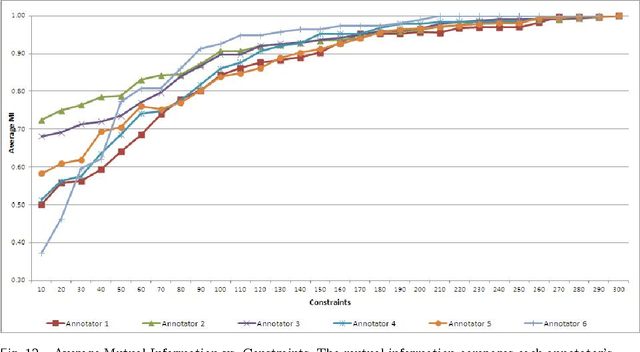
The New York Public Library is participating in the Chronicling America initiative to develop an online searchable database of historically significant newspaper articles. Microfilm copies of the newspapers are scanned and high resolution Optical Character Recognition (OCR) software is run on them. The text from the OCR provides a wealth of data and opinion for researchers and historians. However, categorization of articles provided by the OCR engine is rudimentary and a large number of the articles are labeled editorial without further grouping. Manually sorting articles into fine-grained categories is time consuming if not impossible given the size of the corpus. This paper studies techniques for automatic categorization of newspaper articles so as to enhance search and retrieval on the archive. We explore unsupervised (e.g. KMeans) and semi-supervised (e.g. constrained clustering) learning algorithms to develop article categorization schemes geared towards the needs of end-users. A pilot study was designed to understand whether there was unanimous agreement amongst patrons regarding how articles can be categorized. It was found that the task was very subjective and consequently automated algorithms that could deal with subjective labels were used. While the small scale pilot study was extremely helpful in designing machine learning algorithms, a much larger system needs to be developed to collect annotations from users of the archive. The "BODHI" system currently being developed is a step in that direction, allowing users to correct wrongly scanned OCR and providing keywords and tags for newspaper articles used frequently. On successful implementation of the beta version of this system, we hope that it can be integrated with existing software being developed for the Chronicling America project.