 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
Nov 13, 2025Recent progress in large language models (LLMs) has led to impressive performance on a range of tasks, yet advanced instruction following (IF)-especially for complex, multi-turn, and system-prompted instructions-remains a significant challenge. Rigorous evaluation and effective training for such capabilities are hindered by the lack of high-quality, human-annotated benchmarks and reliable, interpretable reward signals. In this work, we introduce AdvancedIF (we will release this benchmark soon), a comprehensive benchmark featuring over 1,600 prompts and expert-curated rubrics that assess LLMs ability to follow complex, multi-turn, and system-level instructions. We further propose RIFL (Rubric-based Instruction-Following Learning), a novel post-training pipeline that leverages rubric generation, a finetuned rubric verifier, and reward shaping to enable effective reinforcement learning for instruction following. Extensive experiments demonstrate that RIFL substantially improves the instruction-following abilities of LLMs, achieving a 6.7% absolute gain on AdvancedIF and strong results on public benchmarks. Our ablation studies confirm the effectiveness of each component in RIFL. This work establishes rubrics as a powerful tool for both training and evaluating advanced IF in LLMs, paving the way for more capable and reliable AI systems.
Phi-4-Mini-Reasoning: Exploring the Limits of Small Reasoning Language Models in Math
Apr 30, 2025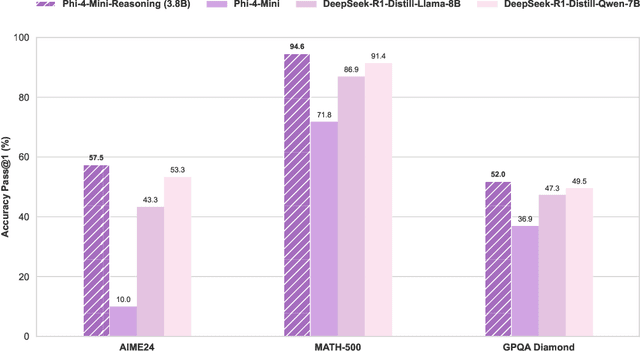
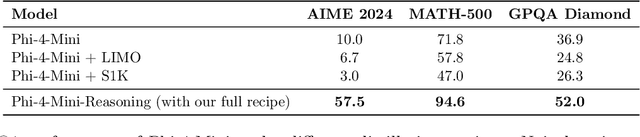
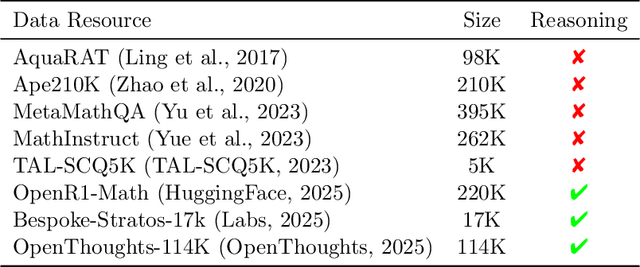
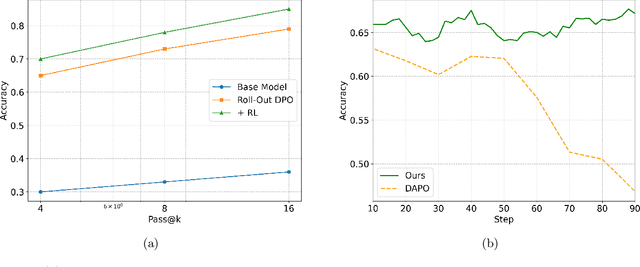
Chain-of-Thought (CoT) significantly enhances formal reasoning capabilities in Large Language Models (LLMs) by training them to explicitly generate intermediate reasoning steps. While LLMs readily benefit from such techniques, improving reasoning in Small Language Models (SLMs) remains challenging due to their limited model capacity. Recent work by Deepseek-R1 demonstrates that distillation from LLM-generated synthetic data can substantially improve the reasoning ability of SLM. However, the detailed modeling recipe is not disclosed. In this work, we present a systematic training recipe for SLMs that consists of four steps: (1) large-scale mid-training on diverse distilled long-CoT data, (2) supervised fine-tuning on high-quality long-CoT data, (3) Rollout DPO leveraging a carefully curated preference dataset, and (4) Reinforcement Learning (RL) with Verifiable Reward. We apply our method on Phi-4-Mini, a compact 3.8B-parameter model. The resulting Phi-4-Mini-Reasoning model exceeds, on math reasoning tasks, much larger reasoning models, e.g., outperforming DeepSeek-R1-Distill-Qwen-7B by 3.2 points and DeepSeek-R1-Distill-Llama-8B by 7.7 points on Math-500. Our results validate that a carefully designed training recipe, with large-scale high-quality CoT data, is effective to unlock strong reasoning capabilities even in resource-constrained small models.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Chain-of-Reasoning: Towards Unified Mathematical Reasoning in Large Language Models via a Multi-Paradigm Perspective
Jan 19, 2025Large Language Models (LLMs) have made notable progress in mathematical reasoning, yet they often rely on single-paradigm reasoning that limits their effectiveness across diverse tasks. In this paper, we introduce Chain-of-Reasoning (CoR), a novel unified framework that integrates multiple reasoning paradigms--Natural Language Reasoning (NLR), Algorithmic Reasoning (AR), and Symbolic Reasoning (SR)--to enable synergistic collaboration. CoR generates multiple potential answers using different reasoning paradigms and synthesizes them into a coherent final solution. We propose a Progressive Paradigm Training (PPT) strategy that allows models to progressively master these paradigms, culminating in the development of CoR-Math-7B. Experimental results demonstrate that CoR-Math-7B significantly outperforms current SOTA models, achieving up to a 41.0% absolute improvement over GPT-4 in theorem proving tasks and a 7.9% improvement over RL-based methods in arithmetic tasks. These results showcase the enhanced mathematical comprehensive ability of our model, achieving significant performance gains on specific tasks and enabling zero-shot generalization across tasks.
Segmenting Text and Learning Their Rewards for Improved RLHF in Language Model
Jan 06, 2025Reinforcement learning from human feedback (RLHF) has been widely adopted to align language models (LMs) with human preference. Prior RLHF works typically take a bandit formulation, which, though intuitive, ignores the sequential nature of LM generation and can suffer from the sparse reward issue. While recent works propose dense token-level RLHF, treating each token as an action may be oversubtle to proper reward assignment. In this paper, we seek to get the best of both by training and utilizing a segment-level reward model, which assigns a reward to each semantically complete text segment that spans over a short sequence of tokens. For reward learning, our method allows dynamic text segmentation and compatibility with standard sequence-preference datasets. For effective RL-based LM training against segment reward, we generalize the classical scalar bandit reward normalizers into location-aware normalizer functions and interpolate the segment reward for further densification. With these designs, our method performs competitively on three popular RLHF benchmarks for LM policy: AlpacaEval 2.0, Arena-Hard, and MT-Bench. Ablation studies are conducted to further demonstrate our method.
GRIN: GRadient-INformed MoE
Sep 18, 2024



Mixture-of-Experts (MoE) models scale more effectively than dense models due to sparse computation through expert routing, selectively activating only a small subset of expert modules. However, sparse computation challenges traditional training practices, as discrete expert routing hinders standard backpropagation and thus gradient-based optimization, which are the cornerstone of deep learning. To better pursue the scaling power of MoE, we introduce GRIN (GRadient-INformed MoE training), which incorporates sparse gradient estimation for expert routing and configures model parallelism to avoid token dropping. Applying GRIN to autoregressive language modeling, we develop a top-2 16$\times$3.8B MoE model. Our model, with only 6.6B activated parameters, outperforms a 7B dense model and matches the performance of a 14B dense model trained on the same data. Extensive evaluations across diverse tasks demonstrate the potential of GRIN to significantly enhance MoE efficacy, achieving 79.4 on MMLU, 83.7 on HellaSwag, 74.4 on HumanEval, and 58.9 on MATH.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Training Small Multimodal Models to Bridge Biomedical Competency Gap: A Case Study in Radiology Imaging
Mar 20, 2024



The scaling laws and extraordinary performance of large foundation models motivate the development and utilization of such large models in biomedicine. However, despite early promising results on some biomedical benchmarks, there are still major challenges that need to be addressed before these models can be used in real-world applications. Frontier models such as GPT-4V still have major competency gaps in multimodal capabilities for biomedical applications. Moreover, pragmatic issues such as access, cost, latency, and compliance make it hard for clinicians to use privately-hosted state-of-the-art large models directly on private patient data. In this paper, we explore training open-source small multimodal models (SMMs) to bridge biomedical competency gaps for unmet clinical needs. To maximize data efficiency, we adopt a modular approach by incorporating state-of-the-art pre-trained models for image and text modalities, and focusing on training a lightweight adapter to ground each modality to the text embedding space. We conduct a comprehensive study of this approach on radiology imaging. For training, we assemble a large dataset with over 1 million image-text pairs. For evaluation, we propose a clinically driven novel approach using GPT-4 and demonstrate its parity with expert evaluation. We also study grounding qualitatively using attention. For best practice, we conduct a systematic ablation study on various choices in data engineering and multimodal training. The resulting LLaVA-Rad (7B) model attains state-of-the-art results on radiology tasks such as report generation and cross-modal retrieval, even outperforming much larger models such as GPT-4V and Med-PaLM M (84B). LLaVA-Rad is fast and can be run on a single V100 GPU in private settings, offering a promising state-of-the-art tool for real-world clinical applications.
SciAgent: Tool-augmented Language Models for Scientific Reasoning
Feb 21, 2024



Scientific reasoning poses an excessive challenge for even the most advanced Large Language Models (LLMs). To make this task more practical and solvable for LLMs, we introduce a new task setting named tool-augmented scientific reasoning. This setting supplements LLMs with scalable toolsets, and shifts the focus from pursuing an omniscient problem solver to a proficient tool-user. To facilitate the research of such setting, we construct a tool-augmented training corpus named MathFunc which encompasses over 30,000 samples and roughly 6,000 tools. Building on MathFunc, we develop SciAgent to retrieve, understand and, if necessary, use tools for scientific problem solving. Additionally, we craft a benchmark, SciToolBench, spanning five scientific domains to evaluate LLMs' abilities with tool assistance. Extensive experiments on SciToolBench confirm the effectiveness of SciAgent. Notably, SciAgent-Mistral-7B surpasses other LLMs with the same size by more than 13% in absolute accuracy. Furthermore, SciAgent-DeepMath-7B shows much superior performance than ChatGPT.