 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniAppBench: Evaluating the Shift from Text to Interactive HTML Responses in LLM-Powered Assistants
Mar 10, 2026With the rapid advancement of Large Language Models (LLMs) in code generation, human-AI interaction is evolving from static text responses to dynamic, interactive HTML-based applications, which we term MiniApps. These applications require models to not only render visual interfaces but also construct customized interaction logic that adheres to real-world principles. However, existing benchmarks primarily focus on algorithmic correctness or static layout reconstruction, failing to capture the capabilities required for this new paradigm. To address this gap, we introduce MiniAppBench, the first comprehensive benchmark designed to evaluate principle-driven, interactive application generation. Sourced from a real-world application with 10M+ generations, MiniAppBench distills 500 tasks across six domains (e.g., Games, Science, and Tools). Furthermore, to tackle the challenge of evaluating open-ended interactions where no single ground truth exists, we propose MiniAppEval, an agentic evaluation framework. Leveraging browser automation, it performs human-like exploratory testing to systematically assess applications across three dimensions: Intention, Static, and Dynamic. Our experiments reveal that current LLMs still face significant challenges in generating high-quality MiniApps, while MiniAppEval demonstrates high alignment with human judgment, establishing a reliable standard for future research. Our code is available in github.com/MiniAppBench.
From Observations to States: Latent Time Series Forecasting
Jan 30, 2026Deep learning has achieved strong performance in Time Series Forecasting (TSF). However, we identify a critical representation paradox, termed Latent Chaos: models with accurate predictions often learn latent representations that are temporally disordered and lack continuity. We attribute this phenomenon to the dominant observation-space forecasting paradigm. Most TSF models minimize point-wise errors on noisy and partially observed data, which encourages shortcut solutions instead of the recovery of underlying system dynamics. To address this issue, we propose Latent Time Series Forecasting (LatentTSF), a novel paradigm that shifts TSF from observation regression to latent state prediction. Specifically, LatentTSF employs an AutoEncoder to project observations at each time step into a higher-dimensional latent state space. This expanded representation aims to capture underlying system variables and impose a smoother temporal structure. Forecasting is then performed entirely in the latent space, allowing the model to focus on learning structured temporal dynamics. Theoretical analysis demonstrates that our proposed latent objectives implicitly maximize mutual information between predicted latent states and ground-truth states and observations. Extensive experiments on widely-used benchmarks confirm that LatentTSF effectively mitigates latent chaos, achieving superior performance. Our code is available in https://github.com/Muyiiiii/LatentTSF.
R&D-Agent-Quant: A Multi-Agent Framework for Data-Centric Factors and Model Joint Optimization
May 21, 2025



Financial markets pose fundamental challenges for asset return prediction due to their high dimensionality, non-stationarity, and persistent volatility. Despite advances in large language models and multi-agent systems, current quantitative research pipelines suffer from limited automation, weak interpretability, and fragmented coordination across key components such as factor mining and model innovation. In this paper, we propose R&D-Agent for Quantitative Finance, in short RD-Agent(Q), the first data-centric multi-agent framework designed to automate the full-stack research and development of quantitative strategies via coordinated factor-model co-optimization. RD-Agent(Q) decomposes the quant process into two iterative stages: a Research stage that dynamically sets goal-aligned prompts, formulates hypotheses based on domain priors, and maps them to concrete tasks, and a Development stage that employs a code-generation agent, Co-STEER, to implement task-specific code, which is then executed in real-market backtests. The two stages are connected through a feedback stage that thoroughly evaluates experimental outcomes and informs subsequent iterations, with a multi-armed bandit scheduler for adaptive direction selection. Empirically, RD-Agent(Q) achieves up to 2X higher annualized returns than classical factor libraries using 70% fewer factors, and outperforms state-of-the-art deep time-series models on real markets. Its joint factor-model optimization delivers a strong balance between predictive accuracy and strategy robustness. Our code is available at: https://github.com/microsoft/RD-Agent.
R&D-Agent: Automating Data-Driven AI Solution Building Through LLM-Powered Automated Research, Development, and Evolution
May 20, 2025Recent advances in AI and ML have transformed data science, yet increasing complexity and expertise requirements continue to hinder progress. While crowdsourcing platforms alleviate some challenges, high-level data science tasks remain labor-intensive and iterative. To overcome these limitations, we introduce R&D-Agent, a dual-agent framework for iterative exploration. The Researcher agent uses performance feedback to generate ideas, while the Developer agent refines code based on error feedback. By enabling multiple parallel exploration traces that merge and enhance one another, R&D-Agent narrows the gap between automated solutions and expert-level performance. Evaluated on MLE-Bench, R&D-Agent emerges as the top-performing machine learning engineering agent, demonstrating its potential to accelerate innovation and improve precision across diverse data science applications. We have open-sourced R&D-Agent on GitHub: https://github.com/microsoft/RD-Agent.
DeepMath-Creative: A Benchmark for Evaluating Mathematical Creativity of Large Language Models
May 13, 2025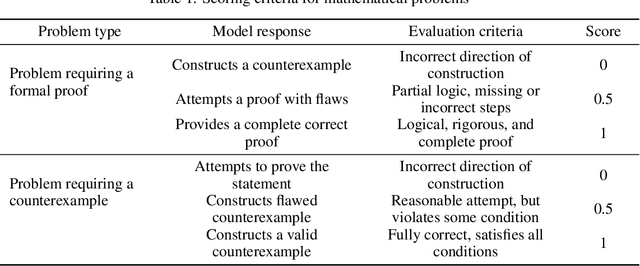
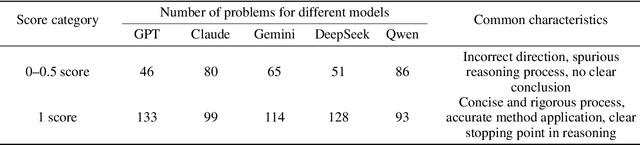
To advance the mathematical proficiency of large language models (LLMs), the DeepMath team has launched an open-source initiative aimed at developing an open mathematical LLM and systematically evaluating its mathematical creativity. This paper represents the initial contribution of this initiative. While recent developments in mathematical LLMs have predominantly emphasized reasoning skills, as evidenced by benchmarks on elementary to undergraduate-level mathematical tasks, the creative capabilities of these models have received comparatively little attention, and evaluation datasets remain scarce. To address this gap, we propose an evaluation criteria for mathematical creativity and introduce DeepMath-Creative, a novel, high-quality benchmark comprising constructive problems across algebra, geometry, analysis, and other domains. We conduct a systematic evaluation of mainstream LLMs' creative problem-solving abilities using this dataset. Experimental results show that even under lenient scoring criteria -- emphasizing core solution components and disregarding minor inaccuracies, such as small logical gaps, incomplete justifications, or redundant explanations -- the best-performing model, O3 Mini, achieves merely 70% accuracy, primarily on basic undergraduate-level constructive tasks. Performance declines sharply on more complex problems, with models failing to provide substantive strategies for open problems. These findings suggest that, although current LLMs display a degree of constructive proficiency on familiar and lower-difficulty problems, such performance is likely attributable to the recombination of memorized patterns rather than authentic creative insight or novel synthesis.
FinTSB: A Comprehensive and Practical Benchmark for Financial Time Series Forecasting
Feb 26, 2025



Financial time series (FinTS) record the behavior of human-brain-augmented decision-making, capturing valuable historical information that can be leveraged for profitable investment strategies. Not surprisingly, this area has attracted considerable attention from researchers, who have proposed a wide range of methods based on various backbones. However, the evaluation of the area often exhibits three systemic limitations: 1. Failure to account for the full spectrum of stock movement patterns observed in dynamic financial markets. (Diversity Gap), 2. The absence of unified assessment protocols undermines the validity of cross-study performance comparisons. (Standardization Deficit), and 3. Neglect of critical market structure factors, resulting in inflated performance metrics that lack practical applicability. (Real-World Mismatch). Addressing these limitations, we propose FinTSB, a comprehensive and practical benchmark for financial time series forecasting (FinTSF). To increase the variety, we categorize movement patterns into four specific parts, tokenize and pre-process the data, and assess the data quality based on some sequence characteristics. To eliminate biases due to different evaluation settings, we standardize the metrics across three dimensions and build a user-friendly, lightweight pipeline incorporating methods from various backbones. To accurately simulate real-world trading scenarios and facilitate practical implementation, we extensively model various regulatory constraints, including transaction fees, among others. Finally, we conduct extensive experiments on FinTSB, highlighting key insights to guide model selection under varying market conditions. Overall, FinTSB provides researchers with a novel and comprehensive platform for improving and evaluating FinTSF methods. The code is available at https://github.com/TongjiFinLab/FinTSBenchmark.