 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemDelta: Controlled Baselines and Hidden Confounds in Agent Memory Evaluation
Jun 29, 2026Agent memory systems are increasingly evaluated against RAG and full-context baselines, but reported gains often mix changes in the memory method with changes in the language model, embedding model, or retrieval pipeline, making it unclear what is actually being measured. We present MemDelta, a controlled evaluation protocol that varies one component at a time on LongMemEval-S (500 questions, 50+ sessions, three model families). Four findings emerge: (1) verbatim RAG matches full-context GPT-4o-mini (47.2% vs. 49.8%, p = 0.34), but the ranking reverses across models: Gemini gains +14pp from full context, while Sonnet gains +31pp from RAG, partly because it refuses 63% of full-context queries; (2) swapping only the embedding model in an identical pipeline shifts accuracy by +6.2pp at n = 500 (p = 0.004), and Mem0 beats MiniLM-RAG by +11pp but loses to cloud-RAG by 1.2pp, so one variable flips the conclusion; (3) agent self-memory (42%) underperforms basic retrieval (47%); (4) on 2 of 6 question types (n = 88), Mem0 matches cloud RAG (72.7% vs. 73.9%, p = 1.0) at 50x the cost, suggesting narrow rather than general gains. We recommend memory evaluations fix embedding models across comparisons, stratify by model family, and report write-path cost before attributing gains to architecture.
MemLeak: Diagnosing Information Leaks in Multimodal Agent Memory
Jun 29, 2026When a multimodal AI agent is asked to forget a fact, current memory systems usually delete the text entry and report success. We find that the fact can remain recoverable from retained user images, including images tagged to entirely different facts, because VLMs use implicit visual cues at inference time. We introduce the Information Provenance Graph (IPG), a taxonomy that classifies memory representations by deletion affordance. The IPG reveals that deletion fails through multiple channels. Our benchmark, MemLeak, measures this across a deletion cascade: direct probing of deletion-capable systems yields <1%, but retained correlated text enables 18.3% recovery, and retained images enable 12.0% recovery (0.0% blind baseline, 0.3% FPR) -- with 47% of image leaks not text-recoverable. Content-aware semantic deletion reduces the image residual to 2.0%. The residual appears across multiple VLMs, a production memory system, and real Unsplash-licensed photographs. Dual-annotator human validation (kappa = 0.88) confirms judge reliability.
Assisted Refinement Network Based on Channel Information Interaction for Camouflaged and Salient Object Detection
Dec 12, 2025Camouflaged Object Detection (COD) stands as a significant challenge in computer vision, dedicated to identifying and segmenting objects visually highly integrated with their backgrounds. Current mainstream methods have made progress in cross-layer feature fusion, but two critical issues persist during the decoding stage. The first is insufficient cross-channel information interaction within the same-layer features, limiting feature expressiveness. The second is the inability to effectively co-model boundary and region information, making it difficult to accurately reconstruct complete regions and sharp boundaries of objects. To address the first issue, we propose the Channel Information Interaction Module (CIIM), which introduces a horizontal-vertical integration mechanism in the channel dimension. This module performs feature reorganization and interaction across channels to effectively capture complementary cross-channel information. To address the second issue, we construct a collaborative decoding architecture guided by prior knowledge. This architecture generates boundary priors and object localization maps through Boundary Extraction (BE) and Region Extraction (RE) modules, then employs hybrid attention to collaboratively calibrate decoded features, effectively overcoming semantic ambiguity and imprecise boundaries. Additionally, the Multi-scale Enhancement (MSE) module enriches contextual feature representations. Extensive experiments on four COD benchmark datasets validate the effectiveness and state-of-the-art performance of the proposed model. We further transferred our model to the Salient Object Detection (SOD) task and demonstrated its adaptability across downstream tasks, including polyp segmentation, transparent object detection, and industrial and road defect detection. Code and experimental results are publicly available at: https://github.com/akuan1234/ARNet-v2.
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Apr 29, 2025



We show that reinforcement learning with verifiable reward using one training example (1-shot RLVR) is effective in incentivizing the math reasoning capabilities of large language models (LLMs). Applying RLVR to the base model Qwen2.5-Math-1.5B, we identify a single example that elevates model performance on MATH500 from 36.0% to 73.6%, and improves the average performance across six common mathematical reasoning benchmarks from 17.6% to 35.7%. This result matches the performance obtained using the 1.2k DeepScaleR subset (MATH500: 73.6%, average: 35.9%), which includes the aforementioned example. Similar substantial improvements are observed across various models (Qwen2.5-Math-7B, Llama3.2-3B-Instruct, DeepSeek-R1-Distill-Qwen-1.5B), RL algorithms (GRPO and PPO), and different math examples (many of which yield approximately 30% or greater improvement on MATH500 when employed as a single training example). In addition, we identify some interesting phenomena during 1-shot RLVR, including cross-domain generalization, increased frequency of self-reflection, and sustained test performance improvement even after the training accuracy has saturated, a phenomenon we term post-saturation generalization. Moreover, we verify that the effectiveness of 1-shot RLVR primarily arises from the policy gradient loss, distinguishing it from the "grokking" phenomenon. We also show the critical role of promoting exploration (e.g., by adding entropy loss with an appropriate coefficient) in 1-shot RLVR training. As a bonus, we observe that applying entropy loss alone, without any outcome reward, significantly enhances Qwen2.5-Math-1.5B's performance on MATH500 by 27.4%. These findings can inspire future work on RLVR data efficiency and encourage a re-examination of both recent progress and the underlying mechanisms in RLVR. Our code, model, and data are open source at https://github.com/ypwang61/One-Shot-RLVR
Is Your World Simulator a Good Story Presenter? A Consecutive Events-Based Benchmark for Future Long Video Generation
Dec 17, 2024



The current state-of-the-art video generative models can produce commercial-grade videos with highly realistic details. However, they still struggle to coherently present multiple sequential events in the stories specified by the prompts, which is foreseeable an essential capability for future long video generation scenarios. For example, top T2V generative models still fail to generate a video of the short simple story 'how to put an elephant into a refrigerator.' While existing detail-oriented benchmarks primarily focus on fine-grained metrics like aesthetic quality and spatial-temporal consistency, they fall short of evaluating models' abilities to handle event-level story presentation. To address this gap, we introduce StoryEval, a story-oriented benchmark specifically designed to assess text-to-video (T2V) models' story-completion capabilities. StoryEval features 423 prompts spanning 7 classes, each representing short stories composed of 2-4 consecutive events. We employ advanced vision-language models, such as GPT-4V and LLaVA-OV-Chat-72B, to verify the completion of each event in the generated videos, applying a unanimous voting method to enhance reliability. Our methods ensure high alignment with human evaluations, and the evaluation of 11 models reveals its challenge, with none exceeding an average story-completion rate of 50%. StoryEval provides a new benchmark for advancing T2V models and highlights the challenges and opportunities in developing next-generation solutions for coherent story-driven video generation.
Mojito: Motion Trajectory and Intensity Control for Video Generation
Dec 12, 2024



Recent advancements in diffusion models have shown great promise in producing high-quality video content. However, efficiently training diffusion models capable of integrating directional guidance and controllable motion intensity remains a challenging and under-explored area. This paper introduces Mojito, a diffusion model that incorporates both \textbf{Mo}tion tra\textbf{j}ectory and \textbf{i}ntensi\textbf{t}y contr\textbf{o}l for text to video generation. Specifically, Mojito features a Directional Motion Control module that leverages cross-attention to efficiently direct the generated object's motion without additional training, alongside a Motion Intensity Modulator that uses optical flow maps generated from videos to guide varying levels of motion intensity. Extensive experiments demonstrate Mojito's effectiveness in achieving precise trajectory and intensity control with high computational efficiency, generating motion patterns that closely match specified directions and intensities, providing realistic dynamics that align well with natural motion in real-world scenarios.
ARL2: Aligning Retrievers for Black-box Large Language Models via Self-guided Adaptive Relevance Labeling
Feb 21, 2024



Retrieval-augmented generation enhances large language models (LLMs) by incorporating relevant information from external knowledge sources. This enables LLMs to adapt to specific domains and mitigate hallucinations in knowledge-intensive tasks. However, existing retrievers are often misaligned with LLMs due to their separate training processes and the black-box nature of LLMs. To address this challenge, we propose ARL2, a retriever learning technique that harnesses LLMs as labelers. ARL2 leverages LLMs to annotate and score relevant evidence, enabling learning the retriever from robust LLM supervision. Furthermore, ARL2 uses an adaptive self-training strategy for curating high-quality and diverse relevance data, which can effectively reduce the annotation cost. Extensive experiments demonstrate the effectiveness of ARL2, achieving accuracy improvements of 5.4% on NQ and 4.6% on MMLU compared to the state-of-the-art methods. Additionally, ARL2 exhibits robust transfer learning capabilities and strong zero-shot generalization abilities. Our code will be published at \url{https://github.com/zhanglingxi-cs/ARL2}.
Adapting LLM Agents Through Communication
Oct 10, 2023



Recent advancements in large language models (LLMs) have shown potential for human-like agents. To help these agents adapt to new tasks without extensive human supervision, we propose the Learning through Communication (LTC) paradigm, a novel training approach enabling LLM agents to improve continuously through interactions with their environments and other agents. Recent advancements in large language models (LLMs) have shown potential for human-like agents. To help these agents adapt to new tasks without extensive human supervision, we propose the Learning through Communication (LTC) paradigm, a novel training approach enabling LLM agents to improve continuously through interactions with their environments and other agents. Through iterative exploration and PPO training, LTC empowers the agent to assimilate short-term experiences into long-term memory. To optimize agent interactions for task-specific learning, we introduce three structured communication patterns: Monologue, Dialogue, and Analogue-tailored for common tasks such as decision-making, knowledge-intensive reasoning, and numerical reasoning. We evaluated LTC on three datasets: ALFWorld (decision-making), HotpotQA (knowledge-intensive reasoning), and GSM8k (numerical reasoning). On ALFWorld, it exceeds the instruction tuning baseline by 12% in success rate. On HotpotQA, LTC surpasses the instruction-tuned LLaMA-7B agent by 5.1% in EM score, and it outperforms the instruction-tuned 9x larger PaLM-62B agent by 0.6%. On GSM8k, LTC outperforms the CoT-Tuning baseline by 3.6% in accuracy. The results showcase the versatility and efficiency of the LTC approach across diverse domains. We will open-source our code to promote further development of the community.
ToolQA: A Dataset for LLM Question Answering with External Tools
Jun 23, 2023

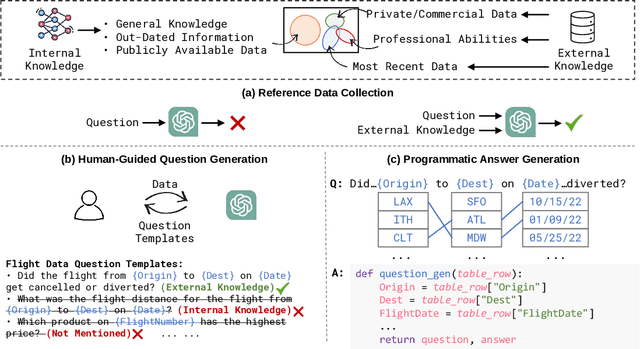

Large Language Models (LLMs) have demonstrated impressive performance in various NLP tasks, but they still suffer from challenges such as hallucination and weak numerical reasoning. To overcome these challenges, external tools can be used to enhance LLMs' question-answering abilities. However, current evaluation methods do not distinguish between questions that can be answered using LLMs' internal knowledge and those that require external information through tool use. To address this issue, we introduce a new dataset called ToolQA, which is designed to faithfully evaluate LLMs' ability to use external tools for question answering. Our development of ToolQA involved a scalable, automated process for dataset curation, along with 13 specialized tools designed for interaction with external knowledge in order to answer questions. Importantly, we strive to minimize the overlap between our benchmark data and LLMs' pre-training data, enabling a more precise evaluation of LLMs' tool-use reasoning abilities. We conducted an in-depth diagnosis of existing tool-use LLMs to highlight their strengths, weaknesses, and potential improvements. Our findings set a new benchmark for evaluating LLMs and suggest new directions for future advancements. Our data and code are freely available to the broader scientific community on GitHub.
Generation-Augmented Query Expansion For Code Retrieval
Dec 20, 2022



Pre-trained language models have achieved promising success in code retrieval tasks, where a natural language documentation query is given to find the most relevant existing code snippet. However, existing models focus only on optimizing the documentation code pairs by embedding them into latent space, without the association of external knowledge. In this paper, we propose a generation-augmented query expansion framework. Inspired by the human retrieval process - sketching an answer before searching, in this work, we utilize the powerful code generation model to benefit the code retrieval task. Specifically, we demonstrate that rather than merely retrieving the target code snippet according to the documentation query, it would be helpful to augment the documentation query with its generation counterpart - generated code snippets from the code generation model. To the best of our knowledge, this is the first attempt that leverages the code generation model to enhance the code retrieval task. We achieve new state-of-the-art results on the CodeSearchNet benchmark and surpass the baselines significantly.