 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Speech-LLM Integration for ASR: Effective Joint Speech-Text Training by Interleaving
Jul 02, 2026Speech-LLM integration has shown promising results by leveraging extensive textual pretraining, yet its specific benefits for automatic speech recognition (ASR) remain unclear. We observe that as supervised ASR training data increases, the contribution of LLM priors becomes less evident, and simple speech-text joint training under-utilizes textual knowledge. We therefore propose Joint Speech-Text Interleaved Pretraining (JSTIP), an ASR-oriented pretraining strategy that constructs word-level and segment-level interleaved speech-text sequences within aligned pairs for speech-LLM architectures that accept continuous inputs. Experiments on 38k hours of ASR data show consistent entity accuracy improvement compared to ASR-only and joint speech-text training baselines. JSTIP achieves on-par entity recognition performance using domain transcription text compared to synthetic speech-text pairs, simplifying domain adaptation. Benefiting from textual pretraining and domain text data, JSTIP is competitive with open-source ASR and Speech-LLM systems in medical entity recognition. The zero-shot speech question answering behaviors further suggest that interleaving reduces the speech-text modality gap and preserves the LLM generative prior, which is likely the reason for the entity improvements on the ASR task.
Shuffle the Context: RoPE-Perturbed Self-Distillation for Long-Context Adaptation
Apr 15, 2026Large language models (LLMs) increasingly operate in settings that require reliable long-context understanding, such as retrieval-augmented generation and multi-document reasoning. A common strategy is to fine-tune pretrained short-context models at the target sequence length. However, we find that standard long-context adaptation can remain brittle: model accuracy depends strongly on the absolute placement of relevant evidence, exhibiting high positional variance even when controlling for task format and difficulty. We propose RoPE-Perturbed Self-Distillation, a training regularizer that improves positional robustness. The core idea is to form alternative "views" of the same training sequence by perturbing its RoPE indices -- effectively moving parts of the context to different positions -- and to train the model to produce consistent predictions across views via self-distillation. This encourages reliance on semantic signals instead of brittle position dependencies. Experiments on long-context adaptation of Llama-3-8B and Qwen-3-4B demonstrate consistent gains on long-context benchmarks, including up to 12.04% improvement on RULER-64K for Llama-3-8B and 2.71% on RULER-256K for Qwen-3-4B after SFT, alongside improved length extrapolation beyond the training context window.
Rethinking Language Model Scaling under Transferable Hypersphere Optimization
Mar 30, 2026Scaling laws for large language models depend critically on the optimizer and parameterization. Existing hyperparameter transfer laws are mainly developed for first-order optimizers, and they do not structurally prevent training instability at scale. Recent hypersphere optimization methods constrain weight matrices to a fixed-norm hypersphere, offering a promising alternative for more stable scaling. We introduce HyperP (Hypersphere Parameterization), the first framework for transferring optimal learning rates across model width, depth, training tokens, and Mixture-of-Experts (MoE) granularity under the Frobenius-sphere constraint with the Muon optimizer. We prove that weight decay is a first-order no-op on the Frobenius sphere, show that Depth-$μ$P remains necessary, and find that the optimal learning rate follows the same data-scaling power law with the "magic exponent" 0.32 previously observed for AdamW. A single base learning rate tuned at the smallest scale transfers across all compute budgets under HyperP, yielding $1.58\times$ compute efficiency over a strong Muon baseline at $6\times10^{21}$ FLOPs. Moreover, HyperP delivers transferable stability: all monitored instability indicators, including $Z$-values, output RMS, and activation outliers, remain bounded and non-increasing under training FLOPs scaling. We also propose SqrtGate, an MoE gating mechanism derived from the hypersphere constraint that preserves output RMS across MoE granularities for improved granularity scaling, and show that hypersphere optimization enables substantially larger auxiliary load-balancing weights, yielding both strong performance and good expert balance. We release our training codebase at https://github.com/microsoft/ArchScale.
GeoNorm: Unify Pre-Norm and Post-Norm with Geodesic Optimization
Jan 29, 2026The placement of normalization layers, specifically Pre-Norm and Post-Norm, remains an open question in Transformer architecture design. In this work, we rethink these approaches through the lens of manifold optimization, interpreting the outputs of the Feed-Forward Network (FFN) and attention layers as update directions in optimization. Building on this perspective, we introduce GeoNorm, a novel method that replaces standard normalization with geodesic updates on the manifold. Furthermore, analogous to learning rate schedules, we propose a layer-wise update decay for the FFN and attention components. Comprehensive experiments demonstrate that GeoNorm consistently outperforms existing normalization methods in Transformer models. Crucially, GeoNorm can be seamlessly integrated into standard Transformer architectures, achieving performance improvements with negligible additional computational cost.
SAS: Simulated Attention Score
Jul 10, 2025The attention mechanism is a core component of the Transformer architecture. Various methods have been developed to compute attention scores, including multi-head attention (MHA), multi-query attention, group-query attention and so on. We further analyze the MHA and observe that its performance improves as the number of attention heads increases, provided the hidden size per head remains sufficiently large. Therefore, increasing both the head count and hidden size per head with minimal parameter overhead can lead to significant performance gains at a low cost. Motivated by this insight, we introduce Simulated Attention Score (SAS), which maintains a compact model size while simulating a larger number of attention heads and hidden feature dimension per head. This is achieved by projecting a low-dimensional head representation into a higher-dimensional space, effectively increasing attention capacity without increasing parameter count. Beyond the head representations, we further extend the simulation approach to feature dimension of the key and query embeddings, enhancing expressiveness by mimicking the behavior of a larger model while preserving the original model size. To control the parameter cost, we also propose Parameter-Efficient Attention Aggregation (PEAA). Comprehensive experiments on a variety of datasets and tasks demonstrate the effectiveness of the proposed SAS method, achieving significant improvements over different attention variants.
Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation
Jul 09, 2025



Recent advances in language modeling have demonstrated the effectiveness of State Space Models (SSMs) for efficient sequence modeling. While hybrid architectures such as Samba and the decoder-decoder architecture, YOCO, have shown promising performance gains over Transformers, prior works have not investigated the efficiency potential of representation sharing between SSM layers. In this paper, we introduce the Gated Memory Unit (GMU), a simple yet effective mechanism for efficient memory sharing across layers. We apply it to create SambaY, a decoder-hybrid-decoder architecture that incorporates GMUs in the cross-decoder to share memory readout states from a Samba-based self-decoder. SambaY significantly enhances decoding efficiency, preserves linear pre-filling time complexity, and boosts long-context performance, all while eliminating the need for explicit positional encoding. Through extensive scaling experiments, we demonstrate that our model exhibits a significantly lower irreducible loss compared to a strong YOCO baseline, indicating superior performance scalability under large-scale compute regimes. Our largest model enhanced with Differential Attention, Phi4-mini-Flash-Reasoning, achieves significantly better performance than Phi4-mini-Reasoning on reasoning tasks such as Math500, AIME24/25, and GPQA Diamond without any reinforcement learning, while delivering up to 10x higher decoding throughput on 2K-length prompts with 32K generation length under the vLLM inference framework. We release our training codebase on open-source data at https://github.com/microsoft/ArchScale.
PaTH Attention: Position Encoding via Accumulating Householder Transformations
May 22, 2025The attention mechanism is a core primitive in modern large language models (LLMs) and AI more broadly. Since attention by itself is permutation-invariant, position encoding is essential for modeling structured domains such as language. Rotary position encoding (RoPE) has emerged as the de facto standard approach for position encoding and is part of many modern LLMs. However, in RoPE the key/query transformation between two elements in a sequence is only a function of their relative position and otherwise independent of the actual input. This limits the expressivity of RoPE-based transformers. This paper describes PaTH, a flexible data-dependent position encoding scheme based on accumulated products of Householder(like) transformations, where each transformation is data-dependent, i.e., a function of the input. We derive an efficient parallel algorithm for training through exploiting a compact representation of products of Householder matrices, and implement a FlashAttention-style blockwise algorithm that minimizes I/O cost. Across both targeted synthetic benchmarks and moderate-scale real-world language modeling experiments, we find that PaTH demonstrates superior performance compared to RoPE and other recent baselines.
Phi-4-Mini-Reasoning: Exploring the Limits of Small Reasoning Language Models in Math
Apr 30, 2025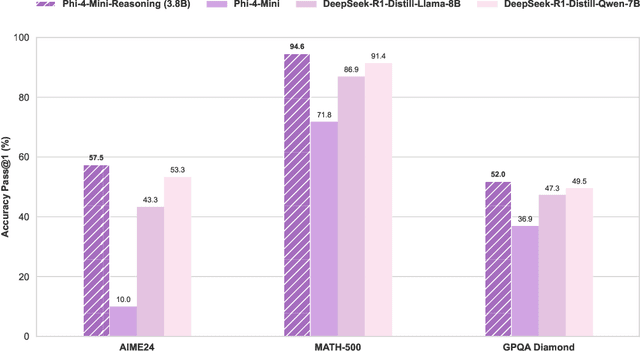
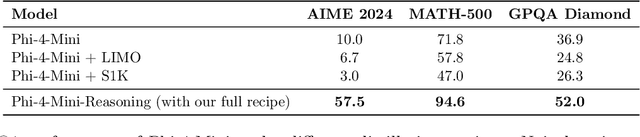
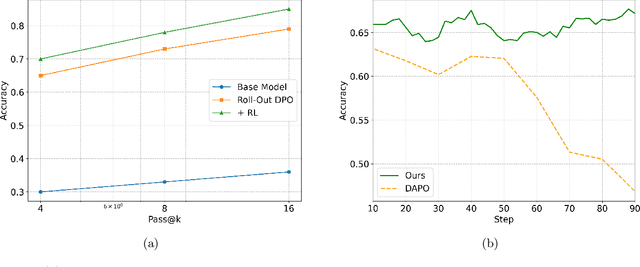
Chain-of-Thought (CoT) significantly enhances formal reasoning capabilities in Large Language Models (LLMs) by training them to explicitly generate intermediate reasoning steps. While LLMs readily benefit from such techniques, improving reasoning in Small Language Models (SLMs) remains challenging due to their limited model capacity. Recent work by Deepseek-R1 demonstrates that distillation from LLM-generated synthetic data can substantially improve the reasoning ability of SLM. However, the detailed modeling recipe is not disclosed. In this work, we present a systematic training recipe for SLMs that consists of four steps: (1) large-scale mid-training on diverse distilled long-CoT data, (2) supervised fine-tuning on high-quality long-CoT data, (3) Rollout DPO leveraging a carefully curated preference dataset, and (4) Reinforcement Learning (RL) with Verifiable Reward. We apply our method on Phi-4-Mini, a compact 3.8B-parameter model. The resulting Phi-4-Mini-Reasoning model exceeds, on math reasoning tasks, much larger reasoning models, e.g., outperforming DeepSeek-R1-Distill-Qwen-7B by 3.2 points and DeepSeek-R1-Distill-Llama-8B by 7.7 points on Math-500. Our results validate that a carefully designed training recipe, with large-scale high-quality CoT data, is effective to unlock strong reasoning capabilities even in resource-constrained small models.
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Apr 29, 2025



We show that reinforcement learning with verifiable reward using one training example (1-shot RLVR) is effective in incentivizing the math reasoning capabilities of large language models (LLMs). Applying RLVR to the base model Qwen2.5-Math-1.5B, we identify a single example that elevates model performance on MATH500 from 36.0% to 73.6%, and improves the average performance across six common mathematical reasoning benchmarks from 17.6% to 35.7%. This result matches the performance obtained using the 1.2k DeepScaleR subset (MATH500: 73.6%, average: 35.9%), which includes the aforementioned example. Similar substantial improvements are observed across various models (Qwen2.5-Math-7B, Llama3.2-3B-Instruct, DeepSeek-R1-Distill-Qwen-1.5B), RL algorithms (GRPO and PPO), and different math examples (many of which yield approximately 30% or greater improvement on MATH500 when employed as a single training example). In addition, we identify some interesting phenomena during 1-shot RLVR, including cross-domain generalization, increased frequency of self-reflection, and sustained test performance improvement even after the training accuracy has saturated, a phenomenon we term post-saturation generalization. Moreover, we verify that the effectiveness of 1-shot RLVR primarily arises from the policy gradient loss, distinguishing it from the "grokking" phenomenon. We also show the critical role of promoting exploration (e.g., by adding entropy loss with an appropriate coefficient) in 1-shot RLVR training. As a bonus, we observe that applying entropy loss alone, without any outcome reward, significantly enhances Qwen2.5-Math-1.5B's performance on MATH500 by 27.4%. These findings can inspire future work on RLVR data efficiency and encourage a re-examination of both recent progress and the underlying mechanisms in RLVR. Our code, model, and data are open source at https://github.com/ypwang61/One-Shot-RLVR
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.