 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Jun 20, 2023



The ability to leverage heterogeneous robotic experience from different robots and tasks to quickly master novel skills and embodiments has the potential to transform robot learning. Inspired by recent advances in foundation models for vision and language, we propose a foundation agent for robotic manipulation. This agent, named RoboCat, is a visual goal-conditioned decision transformer capable of consuming multi-embodiment action-labelled visual experience. This data spans a large repertoire of motor control skills from simulated and real robotic arms with varying sets of observations and actions. With RoboCat, we demonstrate the ability to generalise to new tasks and robots, both zero-shot as well as through adaptation using only 100--1000 examples for the target task. We also show how a trained model itself can be used to generate data for subsequent training iterations, thus providing a basic building block for an autonomous improvement loop. We investigate the agent's capabilities, with large-scale evaluations both in simulation and on three different real robot embodiments. We find that as we grow and diversify its training data, RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.
How to Spend Your Robot Time: Bridging Kickstarting and Offline Reinforcement Learning for Vision-based Robotic Manipulation
May 06, 2022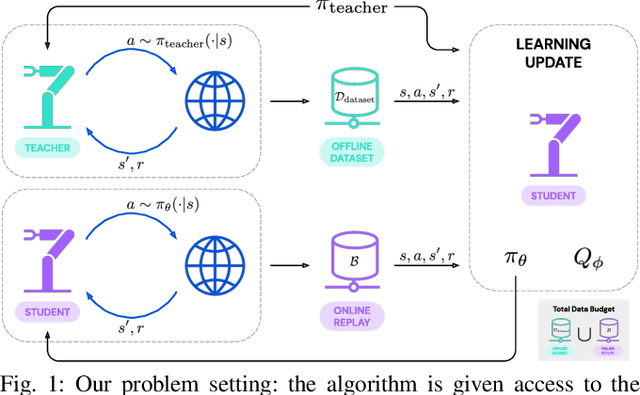

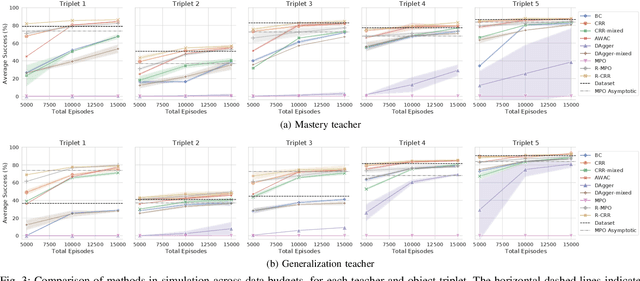
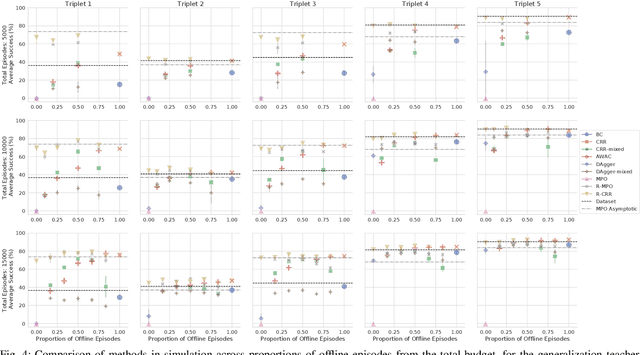
Reinforcement learning (RL) has been shown to be effective at learning control from experience. However, RL typically requires a large amount of online interaction with the environment. This limits its applicability to real-world settings, such as in robotics, where such interaction is expensive. In this work we investigate ways to minimize online interactions in a target task, by reusing a suboptimal policy we might have access to, for example from training on related prior tasks, or in simulation. To this end, we develop two RL algorithms that can speed up training by using not only the action distributions of teacher policies, but also data collected by such policies on the task at hand. We conduct a thorough experimental study of how to use suboptimal teachers on a challenging robotic manipulation benchmark on vision-based stacking with diverse objects. We compare our methods to offline, online, offline-to-online, and kickstarting RL algorithms. By doing so, we find that training on data from both the teacher and student, enables the best performance for limited data budgets. We examine how to best allocate a limited data budget -- on the target task -- between the teacher and the student policy, and report experiments using varying budgets, two teachers with different degrees of suboptimality, and five stacking tasks that require a diverse set of behaviors. Our analysis, both in simulation and in the real world, shows that our approach is the best across data budgets, while standard offline RL from teacher rollouts is surprisingly effective when enough data is given.
Beyond Pick-and-Place: Tackling Robotic Stacking of Diverse Shapes
Nov 03, 2021
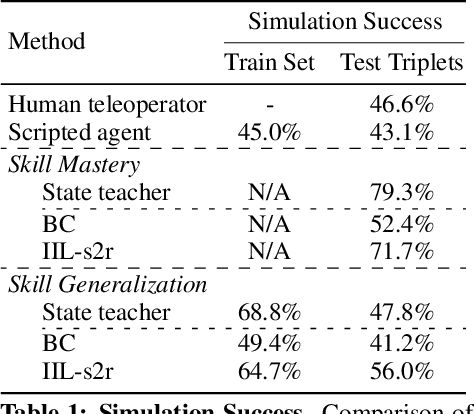
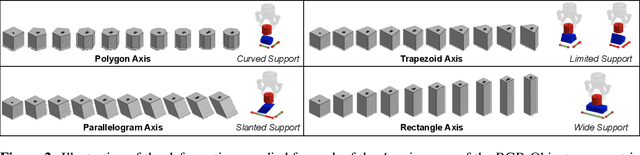
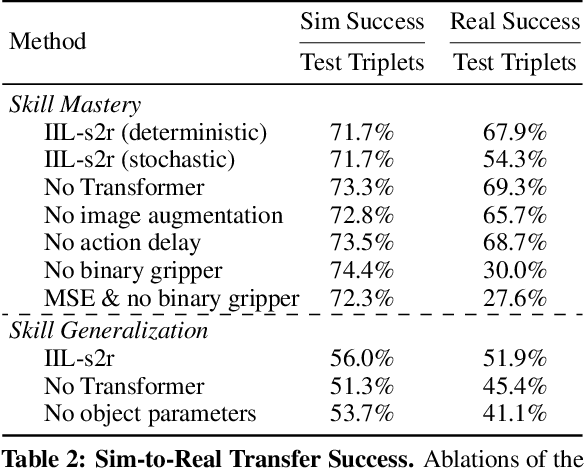
We study the problem of robotic stacking with objects of complex geometry. We propose a challenging and diverse set of such objects that was carefully designed to require strategies beyond a simple "pick-and-place" solution. Our method is a reinforcement learning (RL) approach combined with vision-based interactive policy distillation and simulation-to-reality transfer. Our learned policies can efficiently handle multiple object combinations in the real world and exhibit a large variety of stacking skills. In a large experimental study, we investigate what choices matter for learning such general vision-based agents in simulation, and what affects optimal transfer to the real robot. We then leverage data collected by such policies and improve upon them with offline RL. A video and a blog post of our work are provided as supplementary material.
Stochastic Latent Actor-Critic: Deep Reinforcement Learning with a Latent Variable Model
Jul 01, 2019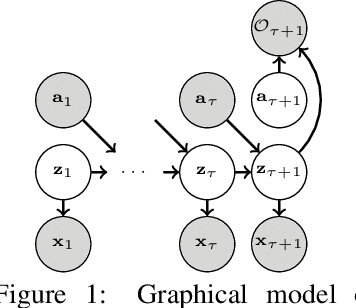
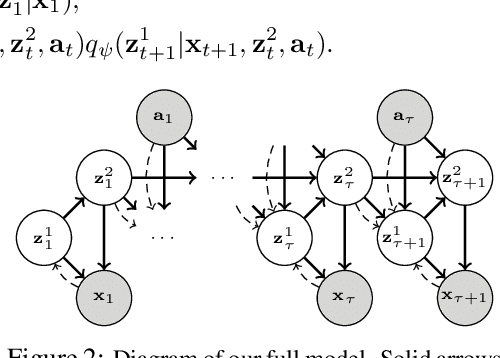

Deep reinforcement learning (RL) algorithms can use high-capacity deep networks to learn directly from image observations. However, these kinds of observation spaces present a number of challenges in practice, since the policy must now solve two problems: a representation learning problem, and a task learning problem. In this paper, we aim to explicitly learn representations that can accelerate reinforcement learning from images. We propose the stochastic latent actor-critic (SLAC) algorithm: a sample-efficient and high-performing RL algorithm for learning policies for complex continuous control tasks directly from high-dimensional image inputs. SLAC learns a compact latent representation space using a stochastic sequential latent variable model, and then learns a critic model within this latent space. By learning a critic within a compact state space, SLAC can learn much more efficiently than standard RL methods. The proposed model improves performance substantially over alternative representations as well, such as variational autoencoders. In fact, our experimental evaluation demonstrates that the sample efficiency of our resulting method is comparable to that of model-based RL methods that directly use a similar type of model for control. Furthermore, our method outperforms both model-free and model-based alternatives in terms of final performance and sample efficiency, on a range of difficult image-based control tasks.
Robustness via Retrying: Closed-Loop Robotic Manipulation with Self-Supervised Learning
Oct 06, 2018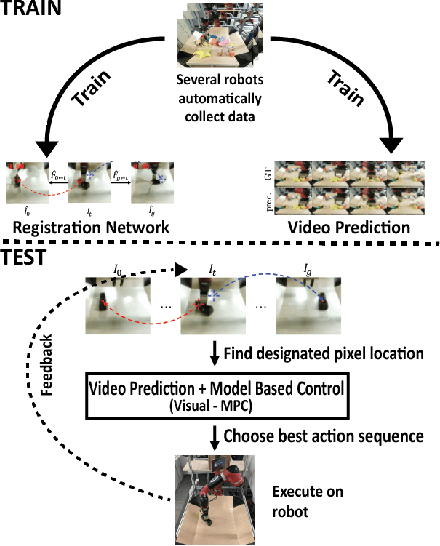

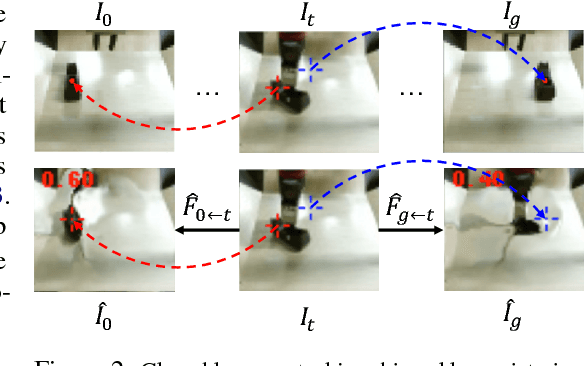
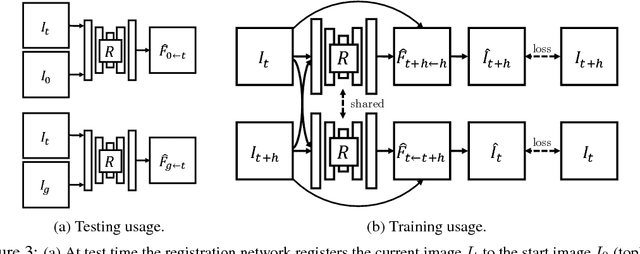
Prediction is an appealing objective for self-supervised learning of behavioral skills, particularly for autonomous robots. However, effectively utilizing predictive models for control, especially with raw image inputs, poses a number of major challenges. How should the predictions be used? What happens when they are inaccurate? In this paper, we tackle these questions by proposing a method for learning robotic skills from raw image observations, using only autonomously collected experience. We show that even an imperfect model can complete complex tasks if it can continuously retry, but this requires the model to not lose track of the objective (e.g., the object of interest). To enable a robot to continuously retry a task, we devise a self-supervised algorithm for learning image registration, which can keep track of objects of interest for the duration of the trial. We demonstrate that this idea can be combined with a video-prediction based controller to enable complex behaviors to be learned from scratch using only raw visual inputs, including grasping, repositioning objects, and non-prehensile manipulation. Our real-world experiments demonstrate that a model trained with 160 robot hours of autonomously collected, unlabeled data is able to successfully perform complex manipulation tasks with a wide range of objects not seen during training.
Stochastic Adversarial Video Prediction
Apr 04, 2018
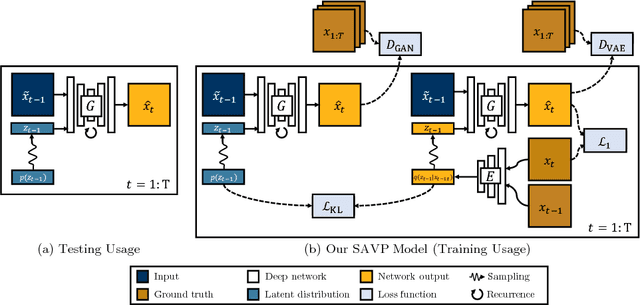

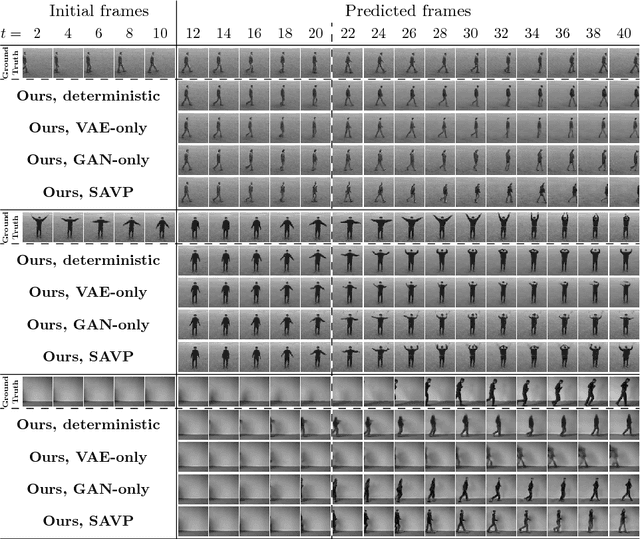
Being able to predict what may happen in the future requires an in-depth understanding of the physical and causal rules that govern the world. A model that is able to do so has a number of appealing applications, from robotic planning to representation learning. However, learning to predict raw future observations, such as frames in a video, is exceedingly challenging -- the ambiguous nature of the problem can cause a naively designed model to average together possible futures into a single, blurry prediction. Recently, this has been addressed by two distinct approaches: (a) latent variational variable models that explicitly model underlying stochasticity and (b) adversarially-trained models that aim to produce naturalistic images. However, a standard latent variable model can struggle to produce realistic results, and a standard adversarially-trained model underutilizes latent variables and fails to produce diverse predictions. We show that these distinct methods are in fact complementary. Combining the two produces predictions that look more realistic to human raters and better cover the range of possible futures. Our method outperforms prior and concurrent work in these aspects.
Self-Supervised Visual Planning with Temporal Skip Connections
Oct 15, 2017
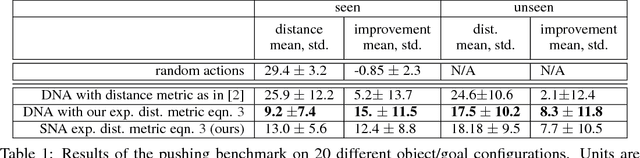
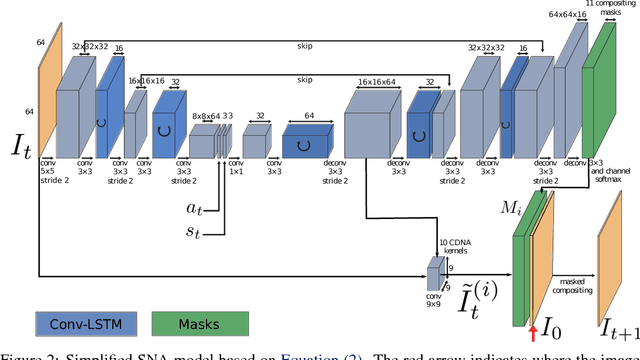

In order to autonomously learn wide repertoires of complex skills, robots must be able to learn from their own autonomously collected data, without human supervision. One learning signal that is always available for autonomously collected data is prediction: if a robot can learn to predict the future, it can use this predictive model to take actions to produce desired outcomes, such as moving an object to a particular location. However, in complex open-world scenarios, designing a representation for prediction is difficult. In this work, we instead aim to enable self-supervised robotic learning through direct video prediction: instead of attempting to design a good representation, we directly predict what the robot will see next, and then use this model to achieve desired goals. A key challenge in video prediction for robotic manipulation is handling complex spatial arrangements such as occlusions. To that end, we introduce a video prediction model that can keep track of objects through occlusion by incorporating temporal skip-connections. Together with a novel planning criterion and action space formulation, we demonstrate that this model substantially outperforms prior work on video prediction-based control. Our results show manipulation of objects not seen during training, handling multiple objects, and pushing objects around obstructions. These results represent a significant advance in the range and complexity of skills that can be performed entirely with self-supervised robotic learning.
Learning Visual Servoing with Deep Features and Fitted Q-Iteration
Jul 11, 2017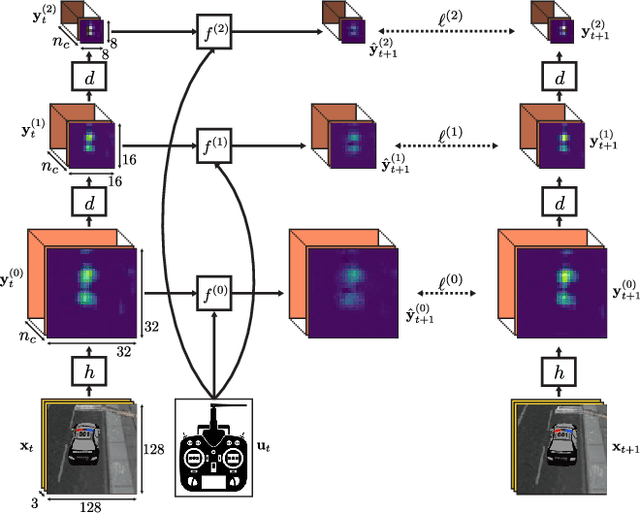

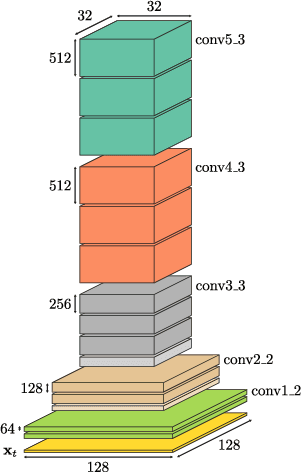
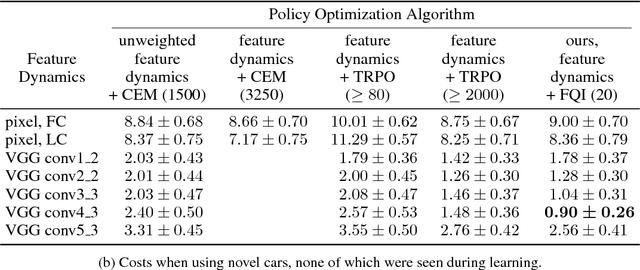
Visual servoing involves choosing actions that move a robot in response to observations from a camera, in order to reach a goal configuration in the world. Standard visual servoing approaches typically rely on manually designed features and analytical dynamics models, which limits their generalization capability and often requires extensive application-specific feature and model engineering. In this work, we study how learned visual features, learned predictive dynamics models, and reinforcement learning can be combined to learn visual servoing mechanisms. We focus on target following, with the goal of designing algorithms that can learn a visual servo using low amounts of data of the target in question, to enable quick adaptation to new targets. Our approach is based on servoing the camera in the space of learned visual features, rather than image pixels or manually-designed keypoints. We demonstrate that standard deep features, in our case taken from a model trained for object classification, can be used together with a bilinear predictive model to learn an effective visual servo that is robust to visual variation, changes in viewing angle and appearance, and occlusions. A key component of our approach is to use a sample-efficient fitted Q-iteration algorithm to learn which features are best suited for the task at hand. We show that we can learn an effective visual servo on a complex synthetic car following benchmark using just 20 training trajectory samples for reinforcement learning. We demonstrate substantial improvement over a conventional approach based on image pixels or hand-designed keypoints, and we show an improvement in sample-efficiency of more than two orders of magnitude over standard model-free deep reinforcement learning algorithms. Videos are available at http://rll.berkeley.edu/visual_servoing .