 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGHOST: Hierarchical Sub-Goal Policies for Generalizing Robot Manipulation
Jun 08, 2026We present GHOST, a framework for learning visuomotor manipulation policies that generalize beyond the training distribution. GHOST factorizes control into (i) a high-level policy that predicts the next sub-goal as a distribution over 3D end-effector poses from multi-view RGB-D observations, and (ii) a low-level goal-conditioned controller that executes embodiment-specific actions. To condition image-based policies on 3D goals, we introduce a simple spatial interface that projects predicted goals into the image plane and represents them as end-effector heatmaps. Across a suite of manipulation tasks, this hierarchical factorization consistently improves performance and robustness compared to a flat Diffusion Policy. Further, we show that this hierarchical interface also makes it easy to incorporate human demonstrations without relying on (noisy) action retargeting. As sub-goals are largely embodiment-agnostic, we train the high-level policy on human video to specify how learned skills should be applied and composed, while keeping the low-level policy trained purely on robot data. This hierarchy enables adaptation to novel objects and task variations using a small number of human demonstrations.
Planning from Point Clouds over Continuous Actions for Multi-object Rearrangement
Sep 04, 2025Long-horizon planning for robot manipulation is a challenging problem that requires reasoning about the effects of a sequence of actions on a physical 3D scene. While traditional task planning methods are shown to be effective for long-horizon manipulation, they require discretizing the continuous state and action space into symbolic descriptions of objects, object relationships, and actions. Instead, we propose a hybrid learning-and-planning approach that leverages learned models as domain-specific priors to guide search in high-dimensional continuous action spaces. We introduce SPOT: Search over Point cloud Object Transformations, which plans by searching for a sequence of transformations from an initial scene point cloud to a goal-satisfying point cloud. SPOT samples candidate actions from learned suggesters that operate on partially observed point clouds, eliminating the need to discretize actions or object relationships. We evaluate SPOT on multi-object rearrangement tasks, reporting task planning success and task execution success in both simulation and real-world environments. Our experiments show that SPOT generates successful plans and outperforms a policy-learning approach. We also perform ablations that highlight the importance of search-based planning.
Non-rigid Relative Placement through 3D Dense Diffusion
Oct 29, 2024



The task of "relative placement" is to predict the placement of one object in relation to another, e.g. placing a mug onto a mug rack. Through explicit object-centric geometric reasoning, recent methods for relative placement have made tremendous progress towards data-efficient learning for robot manipulation while generalizing to unseen task variations. However, they have yet to represent deformable transformations, despite the ubiquity of non-rigid bodies in real world settings. As a first step towards bridging this gap, we propose ``cross-displacement" - an extension of the principles of relative placement to geometric relationships between deformable objects - and present a novel vision-based method to learn cross-displacement through dense diffusion. To this end, we demonstrate our method's ability to generalize to unseen object instances, out-of-distribution scene configurations, and multimodal goals on multiple highly deformable tasks (both in simulation and in the real world) beyond the scope of prior works. Supplementary information and videos can be found at https://sites.google.com/view/tax3d-corl-2024 .
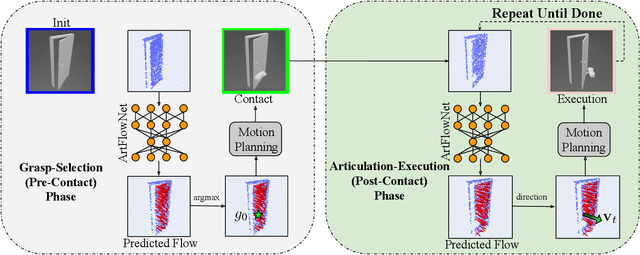
FlowBotHD: History-Aware Diffuser Handling Ambiguities in Articulated Objects Manipulation
Oct 09, 2024



We introduce a novel approach to manipulate articulated objects with ambiguities, such as opening a door, in which multi-modality and occlusions create ambiguities about the opening side and direction. Multi-modality occurs when the method to open a fully closed door (push, pull, slide) is uncertain, or the side from which it should be opened is uncertain. Occlusions further obscure the door's shape from certain angles, creating further ambiguities during the occlusion. To tackle these challenges, we propose a history-aware diffusion network that models the multi-modal distribution of the articulated object and uses history to disambiguate actions and make stable predictions under occlusions. Experiments and analysis demonstrate the state-of-art performance of our method and specifically improvements in ambiguity-caused failure modes. Our project website is available at https://flowbothd.github.io/.
Deep SE(3)-Equivariant Geometric Reasoning for Precise Placement Tasks
Apr 20, 2024



Many robot manipulation tasks can be framed as geometric reasoning tasks, where an agent must be able to precisely manipulate an object into a position that satisfies the task from a set of initial conditions. Often, task success is defined based on the relationship between two objects - for instance, hanging a mug on a rack. In such cases, the solution should be equivariant to the initial position of the objects as well as the agent, and invariant to the pose of the camera. This poses a challenge for learning systems which attempt to solve this task by learning directly from high-dimensional demonstrations: the agent must learn to be both equivariant as well as precise, which can be challenging without any inductive biases about the problem. In this work, we propose a method for precise relative pose prediction which is provably SE(3)-equivariant, can be learned from only a few demonstrations, and can generalize across variations in a class of objects. We accomplish this by factoring the problem into learning an SE(3) invariant task-specific representation of the scene and then interpreting this representation with novel geometric reasoning layers which are provably SE(3) equivariant. We demonstrate that our method can yield substantially more precise placement predictions in simulated placement tasks than previous methods trained with the same amount of data, and can accurately represent relative placement relationships data collected from real-world demonstrations. Supplementary information and videos can be found at https://sites.google.com/view/reldist-iclr-2023.
On Time-Indexing as Inductive Bias in Deep RL for Sequential Manipulation Tasks
Jan 03, 2024While solving complex manipulation tasks, manipulation policies often need to learn a set of diverse skills to accomplish these tasks. The set of skills is often quite multimodal - each one may have a quite distinct distribution of actions and states. Standard deep policy-learning algorithms often model policies as deep neural networks with a single output head (deterministic or stochastic). This structure requires the network to learn to switch between modes internally, which can lead to lower sample efficiency and poor performance. In this paper we explore a simple structure which is conducive to skill learning required for so many of the manipulation tasks. Specifically, we propose a policy architecture that sequentially executes different action heads for fixed durations, enabling the learning of primitive skills such as reaching and grasping. Our empirical evaluation on the Metaworld tasks reveals that this simple structure outperforms standard policy learning methods, highlighting its potential for improved skill acquisition.
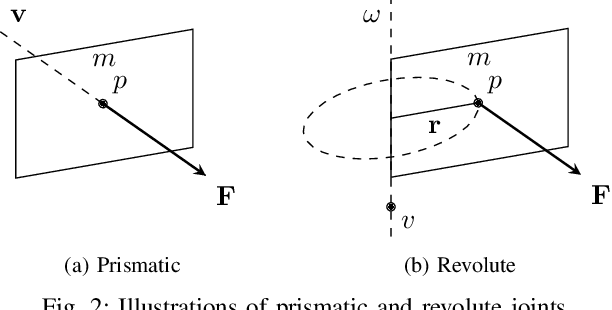
FlowBot++: Learning Generalized Articulated Objects Manipulation via Articulation Projection
Jun 22, 2023



Understanding and manipulating articulated objects, such as doors and drawers, is crucial for robots operating in human environments. We wish to develop a system that can learn to articulate novel objects with no prior interaction, after training on other articulated objects. Previous approaches for articulated object manipulation rely on either modular methods which are brittle or end-to-end methods, which lack generalizability. This paper presents FlowBot++, a deep 3D vision-based robotic system that predicts dense per-point motion and dense articulation parameters of articulated objects to assist in downstream manipulation tasks. FlowBot++ introduces a novel per-point representation of the articulated motion and articulation parameters that are combined to produce a more accurate estimate than either method on their own. Simulated experiments on the PartNet-Mobility dataset validate the performance of our system in articulating a wide range of objects, while real-world experiments on real objects' point clouds and a Sawyer robot demonstrate the generalizability and feasibility of our system in real-world scenarios.
TAX-Pose: Task-Specific Cross-Pose Estimation for Robot Manipulation
Nov 17, 2022



How do we imbue robots with the ability to efficiently manipulate unseen objects and transfer relevant skills based on demonstrations? End-to-end learning methods often fail to generalize to novel objects or unseen configurations. Instead, we focus on the task-specific pose relationship between relevant parts of interacting objects. We conjecture that this relationship is a generalizable notion of a manipulation task that can transfer to new objects in the same category; examples include the relationship between the pose of a pan relative to an oven or the pose of a mug relative to a mug rack. We call this task-specific pose relationship ``cross-pose" and provide a mathematical definition of this concept. We propose a vision-based system that learns to estimate the cross-pose between two objects for a given manipulation task using learned cross-object correspondences. The estimated cross-pose is then used to guide a downstream motion planner to manipulate the objects into the desired pose relationship (placing a pan into the oven or the mug onto the mug rack). We demonstrate our method's capability to generalize to unseen objects, in some cases after training on only 10 demonstrations in the real world. Results show that our system achieves state-of-the-art performance in both simulated and real-world experiments across a number of tasks. Supplementary information and videos can be found at https://sites.google.com/view/tax-pose/home.
FlowBot3D: Learning 3D Articulation Flow to Manipulate Articulated Objects
May 09, 2022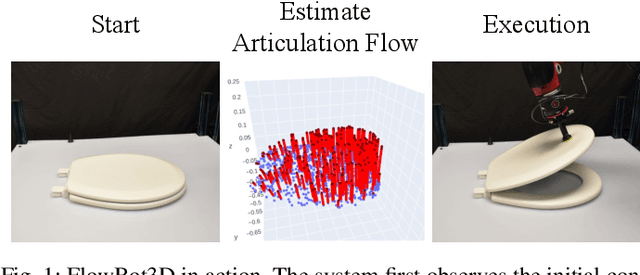

We explore a novel method to perceive and manipulate 3D articulated objects that generalizes to enable a robot to articulate unseen classes of objects. We propose a vision-based system that learns to predict the potential motions of the parts of a variety of articulated objects to guide downstream motion planning of the system to articulate the objects. To predict the object motions, we train a neural network to output a dense vector field representing the point-wise motion direction of the points in the point cloud under articulation. We then deploy an analytical motion planner based on this vector field to achieve a policy that yields maximum articulation. We train the vision system entirely in simulation, and we demonstrate the capability of our system to generalize to unseen object instances and novel categories in both simulation and the real world, deploying our policy on a Sawyer robot with no finetuning. Results show that our system achieves state-of-the-art performance in both simulated and real-world experiments.
Self-supervised Transparent Liquid Segmentation for Robotic Pouring
Mar 03, 2022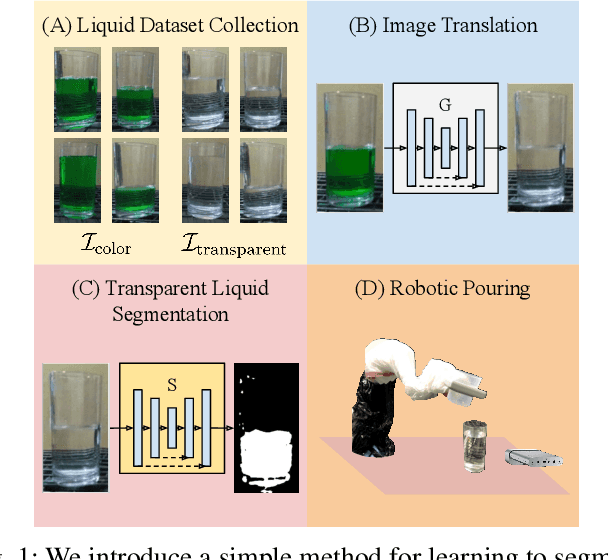
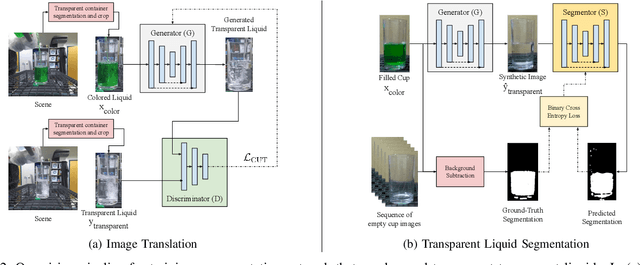
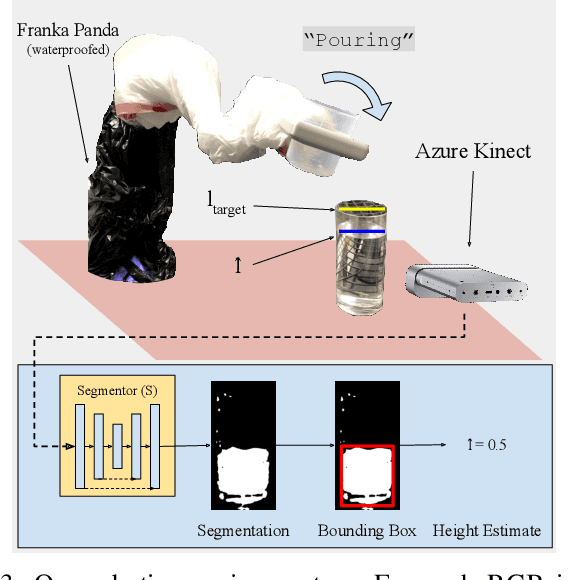

Liquid state estimation is important for robotics tasks such as pouring; however, estimating the state of transparent liquids is a challenging problem. We propose a novel segmentation pipeline that can segment transparent liquids such as water from a static, RGB image without requiring any manual annotations or heating of the liquid for training. Instead, we use a generative model that is capable of translating images of colored liquids into synthetically generated transparent liquid images, trained only on an unpaired dataset of colored and transparent liquid images. Segmentation labels of colored liquids are obtained automatically using background subtraction. Our experiments show that we are able to accurately predict a segmentation mask for transparent liquids without requiring any manual annotations. We demonstrate the utility of transparent liquid segmentation in a robotic pouring task that controls pouring by perceiving the liquid height in a transparent cup. Accompanying video and supplementary materials can be found
* Accepted at ICRA 2022