 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextVidBench: A Benchmark for Long Video Scene Text Understanding
Jun 05, 2025Despite recent progress on the short-video Text-Visual Question Answering (ViteVQA) task - largely driven by benchmarks such as M4-ViteVQA - existing datasets still suffer from limited video duration and narrow evaluation scopes, making it difficult to adequately assess the growing capabilities of powerful multimodal large language models (MLLMs). To address these limitations, we introduce TextVidBench, the first benchmark specifically designed for long-video text question answering (>3 minutes). TextVidBench makes three key contributions: 1) Cross-domain long-video coverage: Spanning 9 categories (e.g., news, sports, gaming), with an average video length of 2306 seconds, enabling more realistic evaluation of long-video understanding. 2) A three-stage evaluation framework: "Text Needle-in-Haystack -> Temporal Grounding -> Text Dynamics Captioning". 3) High-quality fine-grained annotations: Containing over 5,000 question-answer pairs with detailed semantic labeling. Furthermore, we propose an efficient paradigm for improving large models through: (i) introducing the IT-Rope mechanism and temporal prompt engineering to enhance temporal perception, (ii) adopting non-uniform positional encoding to better handle long video sequences, and (iii) applying lightweight fine-tuning on video-text data. Extensive experiments on multiple public datasets as well as TextVidBench demonstrate that our new benchmark presents significant challenges to existing models, while our proposed method offers valuable insights into improving long-video scene text understanding capabilities.
Reinforcing Video Reasoning with Focused Thinking
May 30, 2025Recent advancements in reinforcement learning, particularly through Group Relative Policy Optimization (GRPO), have significantly improved multimodal large language models for complex reasoning tasks. However, two critical limitations persist: 1) they often produce unfocused, verbose reasoning chains that obscure salient spatiotemporal cues and 2) binary rewarding fails to account for partially correct answers, resulting in high reward variance and inefficient learning. In this paper, we propose TW-GRPO, a novel framework that enhances visual reasoning with focused thinking and dense reward granularity. Specifically, we employs a token weighting mechanism that prioritizes tokens with high informational density (estimated by intra-group variance), suppressing redundant tokens like generic reasoning prefixes. Furthermore, we reformulate RL training by shifting from single-choice to multi-choice QA tasks, where soft rewards enable finer-grained gradient estimation by distinguishing partial correctness. Additionally, we propose question-answer inversion, a data augmentation strategy to generate diverse multi-choice samples from existing benchmarks. Experiments demonstrate state-of-the-art performance on several video reasoning and general understanding benchmarks. Notably, TW-GRPO achieves 50.4\% accuracy on CLEVRER (18.8\% improvement over Video-R1) and 65.8\% on MMVU. Our codes are available at \href{https://github.com/longmalongma/TW-GRPO}{https://github.com/longmalongma/TW-GRPO}.
Are Reasoning Models More Prone to Hallucination?
May 29, 2025Recently evolved large reasoning models (LRMs) show powerful performance in solving complex tasks with long chain-of-thought (CoT) reasoning capability. As these LRMs are mostly developed by post-training on formal reasoning tasks, whether they generalize the reasoning capability to help reduce hallucination in fact-seeking tasks remains unclear and debated. For instance, DeepSeek-R1 reports increased performance on SimpleQA, a fact-seeking benchmark, while OpenAI-o3 observes even severer hallucination. This discrepancy naturally raises the following research question: Are reasoning models more prone to hallucination? This paper addresses the question from three perspectives. (1) We first conduct a holistic evaluation for the hallucination in LRMs. Our analysis reveals that LRMs undergo a full post-training pipeline with cold start supervised fine-tuning (SFT) and verifiable reward RL generally alleviate their hallucination. In contrast, both distillation alone and RL training without cold start fine-tuning introduce more nuanced hallucinations. (2) To explore why different post-training pipelines alters the impact on hallucination in LRMs, we conduct behavior analysis. We characterize two critical cognitive behaviors that directly affect the factuality of a LRM: Flaw Repetition, where the surface-level reasoning attempts repeatedly follow the same underlying flawed logic, and Think-Answer Mismatch, where the final answer fails to faithfully match the previous CoT process. (3) Further, we investigate the mechanism behind the hallucination of LRMs from the perspective of model uncertainty. We find that increased hallucination of LRMs is usually associated with the misalignment between model uncertainty and factual accuracy. Our work provides an initial understanding of the hallucination in LRMs.
Reinforced Latent Reasoning for LLM-based Recommendation
May 25, 2025Large Language Models (LLMs) have demonstrated impressive reasoning capabilities in complex problem-solving tasks, sparking growing interest in their application to preference reasoning in recommendation systems. Existing methods typically rely on fine-tuning with explicit chain-of-thought (CoT) data. However, these methods face significant practical limitations due to (1) the difficulty of obtaining high-quality CoT data in recommendation and (2) the high inference latency caused by generating CoT reasoning. In this work, we explore an alternative approach that shifts from explicit CoT reasoning to compact, information-dense latent reasoning. This approach eliminates the need for explicit CoT generation and improves inference efficiency, as a small set of latent tokens can effectively capture the entire reasoning process. Building on this idea, we propose $\textit{\underline{R}einforced \underline{Latent} \underline{R}easoning for \underline{R}ecommendation}$ (LatentR$^3$), a novel end-to-end training framework that leverages reinforcement learning (RL) to optimize latent reasoning without relying on any CoT data.LatentR$^3$ adopts a two-stage training strategy: first, supervised fine-tuning to initialize the latent reasoning module, followed by pure RL training to encourage exploration through a rule-based reward design. Our RL implementation is based on a modified GRPO algorithm, which reduces computational overhead during training and introduces continuous reward signals for more efficient learning. Extensive experiments demonstrate that LatentR$^3$ enables effective latent reasoning without any direct supervision of the reasoning process, significantly improving performance when integrated with different LLM-based recommendation methods. Our codes are available at https://anonymous.4open.science/r/R3-A278/.
L-MTP: Leap Multi-Token Prediction Beyond Adjacent Context for Large Language Models
May 23, 2025Large language models (LLMs) have achieved notable progress. Despite their success, next-token prediction (NTP), the dominant method for LLM training and inference, is constrained in both contextual coverage and inference efficiency due to its inherently sequential process. To overcome these challenges, we propose leap multi-token prediction~(L-MTP), an innovative token prediction method that extends the capabilities of multi-token prediction (MTP) by introducing a leap-based mechanism. Unlike conventional MTP, which generates multiple tokens at adjacent positions, L-MTP strategically skips over intermediate tokens, predicting non-sequential ones in a single forward pass. This structured leap not only enhances the model's ability to capture long-range dependencies but also enables a decoding strategy specially optimized for non-sequential leap token generation, effectively accelerating inference. We theoretically demonstrate the benefit of L-MTP in improving inference efficiency. Experiments across diverse benchmarks validate its merit in boosting both LLM performance and inference speed. The source code will be publicly available.
MPO: Multilingual Safety Alignment via Reward Gap Optimization
May 22, 2025Large language models (LLMs) have become increasingly central to AI applications worldwide, necessitating robust multilingual safety alignment to ensure secure deployment across diverse linguistic contexts. Existing preference learning methods for safety alignment, such as RLHF and DPO, are primarily monolingual and struggle with noisy multilingual data. To address these limitations, we introduce Multilingual reward gaP Optimization (MPO), a novel approach that leverages the well-aligned safety capabilities of the dominant language (English) to improve safety alignment across multiple languages. MPO directly minimizes the reward gap difference between the dominant language and target languages, effectively transferring safety capabilities while preserving the original strengths of the dominant language. Extensive experiments on three LLMs, LLaMA-3.1, Gemma-2 and Qwen2.5, validate MPO's efficacy in multilingual safety alignment without degrading general multilingual utility.
When Less Language is More: Language-Reasoning Disentanglement Makes LLMs Better Multilingual Reasoners
May 21, 2025Multilingual reasoning remains a significant challenge for large language models (LLMs), with performance disproportionately favoring high-resource languages. Drawing inspiration from cognitive neuroscience, which suggests that human reasoning functions largely independently of language processing, we hypothesize that LLMs similarly encode reasoning and language as separable components that can be disentangled to enhance multilingual reasoning. To evaluate this, we perform a causal intervention by ablating language-specific representations at inference time. Experiments on 10 open-source LLMs spanning 11 typologically diverse languages show that this language-specific ablation consistently boosts multilingual reasoning performance. Layer-wise analyses further confirm that language and reasoning representations can be effectively decoupled throughout the model, yielding improved multilingual reasoning capabilities, while preserving top-layer language features remains essential for maintaining linguistic fidelity. Compared to post-training such as supervised fine-tuning or reinforcement learning, our training-free ablation achieves comparable or superior results with minimal computational overhead. These findings shed light on the internal mechanisms underlying multilingual reasoning in LLMs and suggest a lightweight and interpretable strategy for improving cross-lingual generalization.
NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search
May 20, 2025Generative AI search is reshaping information retrieval by offering end-to-end answers to complex queries, reducing users' reliance on manually browsing and summarizing multiple web pages. However, while this paradigm enhances convenience, it disrupts the feedback-driven improvement loop that has historically powered the evolution of traditional Web search. Web search can continuously improve their ranking models by collecting large-scale, fine-grained user feedback (e.g., clicks, dwell time) at the document level. In contrast, generative AI search operates through a much longer search pipeline, spanning query decomposition, document retrieval, and answer generation, yet typically receives only coarse-grained feedback on the final answer. This introduces a feedback loop disconnect, where user feedback for the final output cannot be effectively mapped back to specific system components, making it difficult to improve each intermediate stage and sustain the feedback loop. In this paper, we envision NExT-Search, a next-generation paradigm designed to reintroduce fine-grained, process-level feedback into generative AI search. NExT-Search integrates two complementary modes: User Debug Mode, which allows engaged users to intervene at key stages; and Shadow User Mode, where a personalized user agent simulates user preferences and provides AI-assisted feedback for less interactive users. Furthermore, we envision how these feedback signals can be leveraged through online adaptation, which refines current search outputs in real-time, and offline update, which aggregates interaction logs to periodically fine-tune query decomposition, retrieval, and generation models. By restoring human control over key stages of the generative AI search pipeline, we believe NExT-Search offers a promising direction for building feedback-rich AI search systems that can evolve continuously alongside human feedback.
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025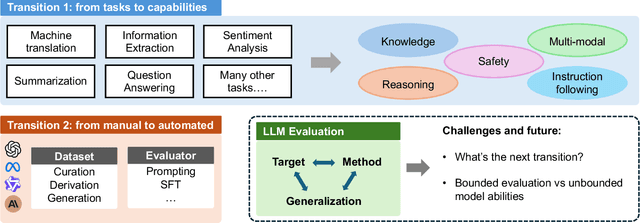
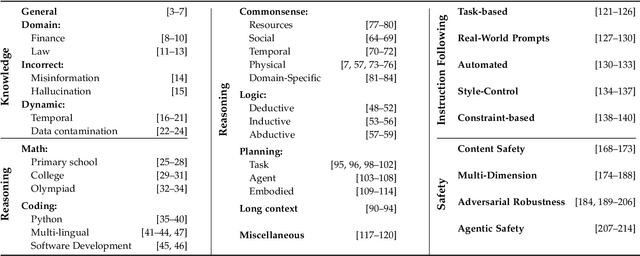
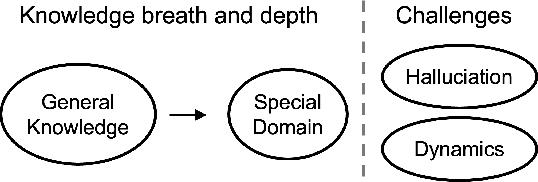
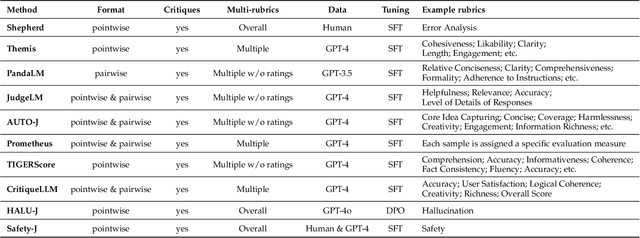
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.