 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Regression Based Watch Time Prediction for Video Recommendation: Model and Performance
Dec 28, 2024



Watch time prediction (WTP) has emerged as a pivotal task in short video recommendation systems, designed to encapsulate user interests. Predicting users' watch times on videos often encounters challenges, including wide value ranges and imbalanced data distributions, which can lead to significant bias when directly regressing watch time. Recent studies have tried to tackle these issues by converting the continuous watch time estimation into an ordinal classification task. While these methods are somewhat effective, they exhibit notable limitations. Inspired by language modeling, we propose a novel Generative Regression (GR) paradigm for WTP based on sequence generation. This approach employs structural discretization to enable the lossless reconstruction of original values while maintaining prediction fidelity. By formulating the prediction problem as a numerical-to-sequence mapping, and with meticulously designed vocabulary and label encodings, each watch time is transformed into a sequence of tokens. To expedite model training, we introduce the curriculum learning with an embedding mixup strategy which can mitigate training-and-inference inconsistency associated with teacher forcing. We evaluate our method against state-of-the-art approaches on four public datasets and one industrial dataset. We also perform online A/B testing on Kuaishou, a leading video app with about 400 million DAUs, to demonstrate the real-world efficacy of our method. The results conclusively show that GR outperforms existing techniques significantly. Furthermore, we successfully apply GR to another regression task in recommendation systems, i.e., Lifetime Value (LTV) prediction, which highlights its potential as a novel and effective solution to general regression challenges.
RAG-Star: Enhancing Deliberative Reasoning with Retrieval Augmented Verification and Refinement
Dec 17, 2024



Existing large language models (LLMs) show exceptional problem-solving capabilities but might struggle with complex reasoning tasks. Despite the successes of chain-of-thought and tree-based search methods, they mainly depend on the internal knowledge of LLMs to search over intermediate reasoning steps, limited to dealing with simple tasks involving fewer reasoning steps. In this paper, we propose \textbf{RAG-Star}, a novel RAG approach that integrates the retrieved information to guide the tree-based deliberative reasoning process that relies on the inherent knowledge of LLMs. By leveraging Monte Carlo Tree Search, RAG-Star iteratively plans intermediate sub-queries and answers for reasoning based on the LLM itself. To consolidate internal and external knowledge, we propose an retrieval-augmented verification that utilizes query- and answer-aware reward modeling to provide feedback for the inherent reasoning of LLMs. Our experiments involving Llama-3.1-8B-Instruct and GPT-4o demonstrate that RAG-Star significantly outperforms previous RAG and reasoning methods.
THESAURUS: Contrastive Graph Clustering by Swapping Fused Gromov-Wasserstein Couplings
Dec 16, 2024



Graph node clustering is a fundamental unsupervised task. Existing methods typically train an encoder through selfsupervised learning and then apply K-means to the encoder output. Some methods use this clustering result directly as the final assignment, while others initialize centroids based on this initial clustering and then finetune both the encoder and these learnable centroids. However, due to their reliance on K-means, these methods inherit its drawbacks when the cluster separability of encoder output is low, facing challenges from the Uniform Effect and Cluster Assimilation. We summarize three reasons for the low cluster separability in existing methods: (1) lack of contextual information prevents discrimination between similar nodes from different clusters; (2) training tasks are not sufficiently aligned with the downstream clustering task; (3) the cluster information in the graph structure is not appropriately exploited. To address these issues, we propose conTrastive grapH clustEring by SwApping fUsed gRomov-wasserstein coUplingS (THESAURUS). Our method introduces semantic prototypes to provide contextual information, and employs a cross-view assignment prediction pretext task that aligns well with the downstream clustering task. Additionally, it utilizes Gromov-Wasserstein Optimal Transport (GW-OT) along with the proposed prototype graph to thoroughly exploit cluster information in the graph structure. To adapt to diverse real-world data, THESAURUS updates the prototype graph and the prototype marginal distribution in OT by using momentum. Extensive experiments demonstrate that THESAURUS achieves higher cluster separability than the prior art, effectively mitigating the Uniform Effect and Cluster Assimilation issues
Wavelet Diffusion Neural Operator
Dec 06, 2024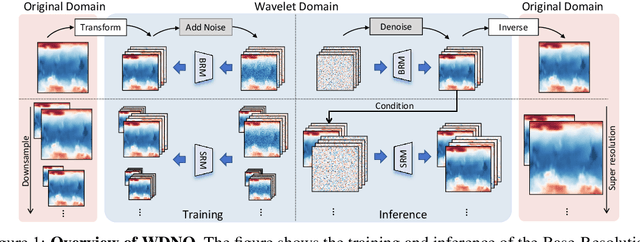
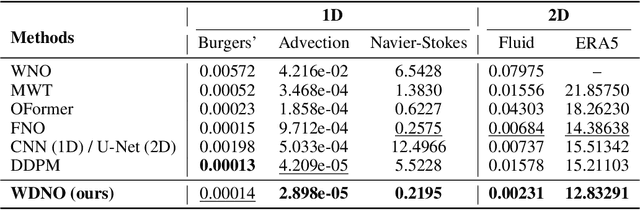
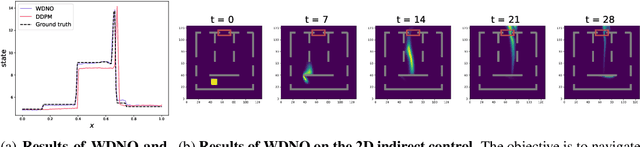
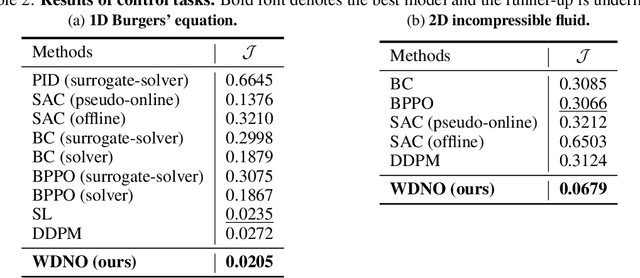
Simulating and controlling physical systems described by partial differential equations (PDEs) are crucial tasks across science and engineering. Recently, diffusion generative models have emerged as a competitive class of methods for these tasks due to their ability to capture long-term dependencies and model high-dimensional states. However, diffusion models typically struggle with handling system states with abrupt changes and generalizing to higher resolutions. In this work, we propose Wavelet Diffusion Neural Operator (WDNO), a novel PDE simulation and control framework that enhances the handling of these complexities. WDNO comprises two key innovations. Firstly, WDNO performs diffusion-based generative modeling in the wavelet domain for the entire trajectory to handle abrupt changes and long-term dependencies effectively. Secondly, to address the issue of poor generalization across different resolutions, which is one of the fundamental tasks in modeling physical systems, we introduce multi-resolution training. We validate WDNO on five physical systems, including 1D advection equation, three challenging physical systems with abrupt changes (1D Burgers' equation, 1D compressible Navier-Stokes equation and 2D incompressible fluid), and a real-world dataset ERA5, which demonstrates superior performance on both simulation and control tasks over state-of-the-art methods, with significant improvements in long-term and detail prediction accuracy. Remarkably, in the challenging context of the 2D high-dimensional and indirect control task aimed at reducing smoke leakage, WDNO reduces the leakage by 33.2% compared to the second-best baseline.
Compositional Generative Multiphysics and Multi-component Simulation
Dec 05, 2024



Multiphysics simulation, which models the interactions between multiple physical processes, and multi-component simulation of complex structures are critical in fields like nuclear and aerospace engineering. Previous studies often rely on numerical solvers or machine learning-based surrogate models to solve or accelerate these simulations. However, multiphysics simulations typically require integrating multiple specialized solvers-each responsible for evolving a specific physical process-into a coupled program, which introduces significant development challenges. Furthermore, no universal algorithm exists for multi-component simulations, which adds to the complexity. Here we propose compositional Multiphysics and Multi-component Simulation with Diffusion models (MultiSimDiff) to overcome these challenges. During diffusion-based training, MultiSimDiff learns energy functions modeling the conditional probability of one physical process/component conditioned on other processes/components. In inference, MultiSimDiff generates coupled multiphysics solutions and multi-component structures by sampling from the joint probability distribution, achieved by composing the learned energy functions in a structured way. We test our method in three tasks. In the reaction-diffusion and nuclear thermal coupling problems, MultiSimDiff successfully predicts the coupling solution using decoupled data, while the surrogate model fails in the more complex second problem. For the thermal and mechanical analysis of the prismatic fuel element, MultiSimDiff trained for single component prediction accurately predicts a larger structure with 64 components, reducing the relative error by 40.3% compared to the surrogate model.
Detection of Performance Interference Among Network Slices in 5G/6G Systems
Dec 02, 2024



Recent studies showed that network slices (NSs), which are logical networks supported by shared physical networks, can experience service interference due to sharing of physical and virtual resources. Thus, from the perspective of providing end-to-end (E2E) service quality assurance in 5G/6G systems, it is crucial to discover possible service interference among the NSs in a timely manner and isolate the potential issues before they can lead to violations of service quality agreements. We study the problem of detecting service interference among NSs in 5G/6G systems, only using E2E key performance indicator measurements, and propose a new algorithm. Our numerical studies demonstrate that, even when the service interference among NSs is weak to moderate, provided that a reasonable number of measurements are available, the proposed algorithm can correctly identify most of shared resources that can cause service interference among the NSs that utilize the shared resources.
Self-supervised Video Instance Segmentation Can Boost Geographic Entity Alignment in Historical Maps
Nov 26, 2024



Tracking geographic entities from historical maps, such as buildings, offers valuable insights into cultural heritage, urbanization patterns, environmental changes, and various historical research endeavors. However, linking these entities across diverse maps remains a persistent challenge for researchers. Traditionally, this has been addressed through a two-step process: detecting entities within individual maps and then associating them via a heuristic-based post-processing step. In this paper, we propose a novel approach that combines segmentation and association of geographic entities in historical maps using video instance segmentation (VIS). This method significantly streamlines geographic entity alignment and enhances automation. However, acquiring high-quality, video-format training data for VIS models is prohibitively expensive, especially for historical maps that often contain hundreds or thousands of geographic entities. To mitigate this challenge, we explore self-supervised learning (SSL) techniques to enhance VIS performance on historical maps. We evaluate the performance of VIS models under different pretraining configurations and introduce a novel method for generating synthetic videos from unlabeled historical map images for pretraining. Our proposed self-supervised VIS method substantially reduces the need for manual annotation. Experimental results demonstrate the superiority of the proposed self-supervised VIS approach, achieving a 24.9\% improvement in AP and a 0.23 increase in F1 score compared to the model trained from scratch.
mR$^2$AG: Multimodal Retrieval-Reflection-Augmented Generation for Knowledge-Based VQA
Nov 22, 2024



Advanced Multimodal Large Language Models (MLLMs) struggle with recent Knowledge-based VQA tasks, such as INFOSEEK and Encyclopedic-VQA, due to their limited and frozen knowledge scope, often leading to ambiguous and inaccurate responses. Thus, multimodal Retrieval-Augmented Generation (mRAG) is naturally introduced to provide MLLMs with comprehensive and up-to-date knowledge, effectively expanding the knowledge scope. However, current mRAG methods have inherent drawbacks, including: 1) Performing retrieval even when external knowledge is not needed. 2) Lacking of identification of evidence that supports the query. 3) Increasing model complexity due to additional information filtering modules or rules. To address these shortcomings, we propose a novel generalized framework called \textbf{m}ultimodal \textbf{R}etrieval-\textbf{R}eflection-\textbf{A}ugmented \textbf{G}eneration (mR$^2$AG), which achieves adaptive retrieval and useful information localization to enable answers through two easy-to-implement reflection operations, preventing high model complexity. In mR$^2$AG, Retrieval-Reflection is designed to distinguish different user queries and avoids redundant retrieval calls, and Relevance-Reflection is introduced to guide the MLLM in locating beneficial evidence of the retrieved content and generating answers accordingly. In addition, mR$^2$AG can be integrated into any well-trained MLLM with efficient fine-tuning on the proposed mR$^2$AG Instruction-Tuning dataset (mR$^2$AG-IT). mR$^2$AG significantly outperforms state-of-the-art MLLMs (e.g., GPT-4v/o) and RAG-based MLLMs on INFOSEEK and Encyclopedic-VQA, while maintaining the exceptional capabilities of base MLLMs across a wide range of Visual-dependent tasks.
Robust State Estimation for Legged Robots with Dual Beta Kalman Filter
Nov 18, 2024



Existing state estimation algorithms for legged robots that rely on proprioceptive sensors often overlook foot slippage and leg deformation in the physical world, leading to large estimation errors. To address this limitation, we propose a comprehensive measurement model that accounts for both foot slippage and variable leg length by analyzing the relative motion between foot contact points and the robot's body center. We show that leg length is an observable quantity, meaning that its value can be explicitly inferred by designing an auxiliary filter. To this end, we introduce a dual estimation framework that iteratively employs a parameter filter to estimate the leg length parameters and a state filter to estimate the robot's state. To prevent error accumulation in this iterative framework, we construct a partial measurement model for the parameter filter using the leg static equation. This approach ensures that leg length estimation relies solely on joint torques and foot contact forces, avoiding the influence of state estimation errors on the parameter estimation. Unlike leg length which can be directly estimated, foot slippage cannot be measured directly with the current sensor configuration. However, since foot slippage occurs at a low frequency, it can be treated as outliers in the measurement data. To mitigate the impact of these outliers, we propose the beta Kalman filter (beta KF), which redefines the estimation loss in canonical Kalman filtering using beta divergence. This divergence can assign low weights to outliers in an adaptive manner, thereby enhancing the robustness of the estimation algorithm. These techniques together form the dual beta-Kalman filter (Dual beta KF), a novel algorithm for robust state estimation in legged robots. Experimental results on the Unitree GO2 robot demonstrate that the Dual beta KF significantly outperforms state-of-the-art methods.
Evolutionary Algorithm with Detection Region Method for Constrained Multi-Objective Problems with Binary Constraints
Nov 13, 2024



Solving constrained multi-objective optimization problems (CMOPs) is a challenging task. While many practical algorithms have been developed to tackle CMOPs, real-world scenarios often present cases where the constraint functions are unknown or unquantifiable, resulting in only binary outcomes (feasible or infeasible). This limitation reduces the effectiveness of constraint violation guidance, which can negatively impact the performance of existing algorithms that rely on this approach. Such challenges are particularly detrimental for algorithms employing the epsilon-based method, as they hinder effective relaxation of the feasible region. To address these challenges, this paper proposes a novel algorithm called DRMCMO based on the detection region method. In DRMCMO, detection regions dynamic monitor feasible solutions to enhance convergence, helping the population escape local optima. Additionally, these regions collaborate with the neighbor pairing strategy to improve population diversity within narrow feasible areas. We have modified three existing test suites to serve as benchmark test problems for CMOPs with binary constraints(CMOP/BC) and conducted comprehensive comparative experiments with state-of-the-art algorithms on these test suites and real-world problems. The results demonstrate the strong competitiveness of DRMCMO against state-of-the-art algorithms. Given the limited research on CMOP/BC, our study offers a new perspective for advancing this field.