 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Switching Reveals Language Anchoring in Multilingual LLMs
Jun 18, 2026Multilingual Large Language Models (MLLMs) are increasingly expected to handle Code-Switched (CS) inputs, yet mixing languages frequently degrades performance relative to source- or target-language monolingual counterparts. To understand this degradation, we use grammar-forced CS as a controlled diagnostic setting for locating CS representations relative to their source and target counterparts. We introduce Anchor Bias, a geometric measure that quantifies language anchoring, whether a CS hidden state aligns closer to its source or target language counterpart. Across diverse MLLMs, Anchor Bias reveals a consistent grammar-frame effect: source-framed CS stays source-anchored, whereas target-framed CS shifts target-ward and shows larger Question Answering (QA) degradation. Motivated by this representational pattern, we propose CANVAS (Contextual Anchor-based Neural Vector Alignment Steering), an inference-time intervention that extracts a source-side canvas from the input and softly steers target-language hidden states toward the source anchor during prefill. CANVAS consistently recovers QA F1 across MLLMs and CS conditions, showing that internal anchoring signals provide an actionable target for mitigating CS inference failures.
When Attention Closes: How LLMs Lose the Thread in Multi-Turn Interaction
May 13, 2026Large language models can follow complex instructions in a single turn, yet over long multi-turn interactions they often lose the thread of instructions, persona, and rules. This degradation has been measured behaviorally but not mechanistically explained. We propose a channel-transition account: goal-defining tokens become less accessible through attention, while goal-related information may persist in residual representations. We introduce the Goal Accessibility Ratio (GAR), measuring attention from generated tokens to task-defining goal tokens, and combine it with sliding-window ablations and residual-stream probes. When attention to instructions closes, what survives reveals architecture. Across architectures, the transition yields qualitatively distinct failure modes: some models preserve goal-conditioned behavior at vanishing attention, others fail despite decodable residual goal information, and the layer at which this encoding emerges varies from 2 to 27. A within-model causal ablation that force-closes the attention channel in Mistral collapses recall from near-perfect to 11% on a 20-fact retention task and raises persona-constraint violations above an adversarial-pressure baseline without user pressure, with both effects emerging at the predictable crossover turn. Linear probes recover per-episode recall outcomes from residual representations with AUC up to 0.99 across all four primary architectures, while input embeddings remain at chance. Across architectures and model scales, the gap between attention loss and residual decodability predicts whether goal-conditioned behavior survives channel closure. We contribute GAR as a diagnostic, the channel-transition framework as a controlled mechanistic account, and a parametric prediction of failure timing under windowed attention closure.
Sparse Personalized Text Generation with Multi-Trajectory Reasoning
Apr 27, 2026As Large Language Models (LLMs) advance, personalization has become a key mechanism for tailoring outputs to individual user needs. However, most existing methods rely heavily on dense interaction histories, making them ineffective in cold-start scenarios where such data is sparse or unavailable. While external signals (e.g., content of similar users) can offer a potential remedy, leveraging them effectively remains challenging: raw context is often noisy, and existing methods struggle to reason over heterogeneous data sources. To address these issues, we introduce PAT (Personalization with Aligned Trajectories), a reasoning framework for cold-start LLM personalization. PAT first retrieves information along two complementary trajectories: writing-style cues from stylistically similar users and topic-specific context from preference-aligned users. It then employs a reinforcement learning-based, iterative dual-reasoning mechanism that enables the LLM to jointly refine and integrate these signals. Experimental results across real-world personalization benchmarks show that PAT consistently improves generation quality and alignment under sparse-data conditions, establishing a strong solution to the cold-start personalization problem.
ReflectCAP: Detailed Image Captioning with Reflective Memory
Apr 14, 2026Detailed image captioning demands both factual grounding and fine-grained coverage, yet existing methods have struggled to achieve them simultaneously. We address this tension with Reflective Note-Guided Captioning (ReflectCAP), where a multi-agent pipeline analyzes what the target large vision-language model (LVLM) consistently hallucinates and what it systematically overlooks, distilling these patterns into reusable guidelines called Structured Reflection Notes. At inference time, these notes steer the captioning model along both axes -- what to avoid and what to attend to -- yielding detailed captions that jointly improve factuality and coverage. Applying this method to 8 LVLMs spanning the GPT-4.1 family, Qwen series, and InternVL variants, ReflectCAP reaches the Pareto frontier of the trade-off between factuality and coverage, and delivers substantial gains on CapArena-Auto, where generated captions are judged head-to-head against strong reference models. Moreover, ReflectCAP offers a more favorable trade-off between caption quality and compute cost than model scaling or existing multi-agent pipelines, which incur 21--36\% greater overhead. This makes high-quality detailed captioning viable under real-world cost and latency constraints.
ViT-AdaLA: Adapting Vision Transformers with Linear Attention
Mar 17, 2026Vision Transformers (ViTs) based vision foundation models (VFMs) have achieved remarkable performance across diverse vision tasks, but suffer from quadratic complexity that limits scalability to long sequences. Existing linear attention approaches for ViTs are typically trained from scratch, requiring substantial computational resources, while linearization-based methods developed for large language model decoders do not transfer well to ViTs. To address these challenges, we propose ViT-AdaLA, a novel framework for effectively adapting and transferring prior knowledge from VFMs to linear attention ViTs. ViT-AdaLA consists of three stages: attention alignment, feature alignment, and supervised fine-tuning. In the attention alignment stage, we align vanilla linear attention with the original softmax-based attention in each block to approximate the behavior of softmax attention. However, residual approximation errors inevitably accumulate across layers. We mitigate this by fine-tuning the linearized ViT to align its final-layer features with a frozen softmax VFM teacher. Finally, the adapted prior knowledge is transferred to downstream tasks through supervised fine-tuning. Extensive experiments on classification and segmentation tasks demonstrate the effectiveness and generality of ViT-AdaLA over various state-of-the-art linear attention counterpart.
InfinityStory: Unlimited Video Generation with World Consistency and Character-Aware Shot Transitions
Mar 04, 2026Generating long-form storytelling videos with consistent visual narratives remains a significant challenge in video synthesis. We present a novel framework, dataset, and a model that address three critical limitations: background consistency across shots, seamless multi-subject shot-to-shot transitions, and scalability to hour-long narratives. Our approach introduces a background-consistent generation pipeline that maintains visual coherence across scenes while preserving character identity and spatial relationships. We further propose a transition-aware video synthesis module that generates smooth shot transitions for complex scenarios involving multiple subjects entering or exiting frames, going beyond the single-subject limitations of prior work. To support this, we contribute with a synthetic dataset of 10,000 multi-subject transition sequences covering underrepresented dynamic scene compositions. On VBench, InfinityStory achieves the highest Background Consistency (88.94), highest Subject Consistency (82.11), and the best overall average rank (2.80), showing improved stability, smoother transitions, and better temporal coherence.
VILLAIN at AVerImaTeC: Verifying Image-Text Claims via Multi-Agent Collaboration
Feb 04, 2026This paper describes VILLAIN, a multimodal fact-checking system that verifies image-text claims through prompt-based multi-agent collaboration. For the AVerImaTeC shared task, VILLAIN employs vision-language model agents across multiple stages of fact-checking. Textual and visual evidence is retrieved from the knowledge store enriched through additional web collection. To identify key information and address inconsistencies among evidence items, modality-specific and cross-modal agents generate analysis reports. In the subsequent stage, question-answer pairs are produced based on these reports. Finally, the Verdict Prediction agent produces the verification outcome based on the image-text claim and the generated question-answer pairs. Our system ranked first on the leaderboard across all evaluation metrics. The source code is publicly available at https://github.com/ssu-humane/VILLAIN.
Risk-Aware Human-in-the-Loop Framework with Adaptive Intrusion Response for Autonomous Vehicles
Jan 16, 2026Autonomous vehicles must remain safe and effective when encountering rare long-tailed scenarios or cyber-physical intrusions during driving. We present RAIL, a risk-aware human-in-the-loop framework that turns heterogeneous runtime signals into calibrated control adaptations and focused learning. RAIL fuses three cues (curvature actuation integrity, time-to-collision proximity, and observation-shift consistency) into an Intrusion Risk Score (IRS) via a weighted Noisy-OR. When IRS exceeds a threshold, actions are blended with a cue-specific shield using a learned authority, while human override remains available; when risk is low, the nominal policy executes. A contextual bandit arbitrates among shields based on the cue vector, improving mitigation choices online. RAIL couples Soft Actor-Critic (SAC) with risk-prioritized replay and dual rewards so that takeovers and near misses steer learning while nominal behavior remains covered. On MetaDrive, RAIL achieves a Test Return (TR) of 360.65, a Test Success Rate (TSR) of 0.85, a Test Safety Violation (TSV) of 0.75, and a Disturbance Rate (DR) of 0.0027, while logging only 29.07 training safety violations, outperforming RL, safe RL, offline/imitation learning, and prior HITL baselines. Under Controller Area Network (CAN) injection and LiDAR spoofing attacks, it improves Success Rate (SR) to 0.68 and 0.80, lowers the Disengagement Rate under Attack (DRA) to 0.37 and 0.03, and reduces the Attack Success Rate (ASR) to 0.34 and 0.11. In CARLA, RAIL attains a TR of 1609.70 and TSR of 0.41 with only 8000 steps.
DASH: Deception-Augmented Shared Mental Model for a Human-Machine Teaming System
Dec 21, 2025We present DASH (Deception-Augmented Shared mental model for Human-machine teaming), a novel framework that enhances mission resilience by embedding proactive deception into Shared Mental Models (SMM). Designed for mission-critical applications such as surveillance and rescue, DASH introduces "bait tasks" to detect insider threats, e.g., compromised Unmanned Ground Vehicles (UGVs), AI agents, or human analysts, before they degrade team performance. Upon detection, tailored recovery mechanisms are activated, including UGV system reinstallation, AI model retraining, or human analyst replacement. In contrast to existing SMM approaches that neglect insider risks, DASH improves both coordination and security. Empirical evaluations across four schemes (DASH, SMM-only, no-SMM, and baseline) show that DASH sustains approximately 80% mission success under high attack rates, eight times higher than the baseline. This work contributes a practical human-AI teaming framework grounded in shared mental models, a deception-based strategy for insider threat detection, and empirical evidence of enhanced robustness under adversarial conditions. DASH establishes a foundation for secure, adaptive human-machine teaming in contested environments.
FIFA: Unified Faithfulness Evaluation Framework for Text-to-Video and Video-to-Text Generation
Jul 09, 2025

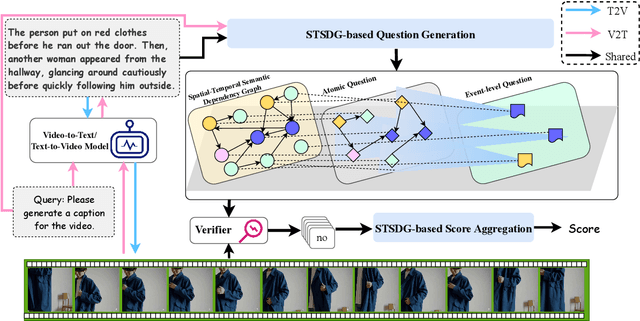
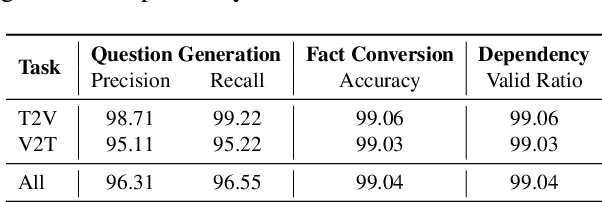
Video Multimodal Large Language Models (VideoMLLMs) have achieved remarkable progress in both Video-to-Text and Text-to-Video tasks. However, they often suffer fro hallucinations, generating content that contradicts the visual input. Existing evaluation methods are limited to one task (e.g., V2T) and also fail to assess hallucinations in open-ended, free-form responses. To address this gap, we propose FIFA, a unified FaIthFulness evAluation framework that extracts comprehensive descriptive facts, models their semantic dependencies via a Spatio-Temporal Semantic Dependency Graph, and verifies them using VideoQA models. We further introduce Post-Correction, a tool-based correction framework that revises hallucinated content. Extensive experiments demonstrate that FIFA aligns more closely with human judgment than existing evaluation methods, and that Post-Correction effectively improves factual consistency in both text and video generation.