 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialBench: Is Your Spatial Foundation Model an All-Round Player?
May 26, 2026While spatial foundation models have demonstrated impressive performance on standard datasets, a critical question remains: are they truly all-round players capable of generalizing robustly across diverse downstream tasks, arbitrary viewpoints, shifting scene domains, varying input densities, and specific hardware constraints? Answering this overarching question requires a holistic assessment, yet current models are mainly evaluated on specific domains for which they were specifically designed or trained. Such evaluations are intrinsically limited by narrow paradigm coverage, limited scene domains, and arbitrary frame sampling, making it fundamentally difficult to assess their true generalization capabilities. To address this gap, we present SpatialBench, a cross-paradigm, domain-diverse benchmark for spatial foundation models with deterministic sampling. SpatialBench features unprecedented scale and rigorous deterministic design, comprising 19 datasets and 546 scenes across 5 diverse spatial domains. It comprehensively evaluates 41 models across 6 paradigms on 5 task suites under 4 different input density settings. Our extensive evaluation reveals that current models are not yet all-round players, and uncovers crucial insights for future advancement. Specifically, we demonstrate that full-context attention maximizes accuracy while bounded-memory strategies unlock long-sequence scalability. Moreover, our empirical evaluations in challenging embodied and egocentric tasks demonstrate that strict domain alignment and high data quality are far more critical to performance than simple dataset scaling. Furthermore, to address the largest data gap identified in our analysis, we go beyond evaluation by introducing a large-scale dataset, DA-Next-5M, and a strong baseline model, DA-Next, pushing the boundaries of spatial representation learning.
EnCAgg: Enhanced Clustering Aggregation for Robust Federated Learning against Dynamic Model Poisoning
May 21, 2026Federated learning faces increasing threats from model poisoning attacks, which harms its application to improve privacy. Existing defense methods typically rely on fixed thresholds or perform clustering with a fixed number of clusters to distinguish malicious gradients from benign ones. However, these methods are difficult to adapt to dynamic poisoning strategies of malicious clients, and often result in the loss of benign gradients due to the heterogeneity of clients' local datasets. To address these problems, we propose a novel robust aggregation method that leverages a small number of known benign clients as references, enabling accurate identification and filtering of malicious gradients while retaining as many benign gradients as possible, even when the number of malicious clients is unknown and variable. First, we introduce a density-based low-dimensional gradient clustering method, which projects gradients onto the two most divergent dimensions and applies density-based clustering to identify malicious gradients while retaining clustered benign gradients and potentially benign outliers. Second, we design an enhancing clustering low-dimensional gradient generator model, which learns to generate pseudo-gradients aligned with the boundary of the benign cluster. These pseudo-gradients act as bridges to connect sparse benign gradient outliers. Third, we introduce low-dimensional gradient re-clustering that clusters the generated pseudo-gradients together with real gradients to recover benign gradients misclassified as noise points, enabling more benign gradients to participate in aggregation. Extensive experiments on the MNIST, CIFAR-10, and MIND datasets demonstrate that our method exhibits superior fidelity and robustness under dynamic poisoning scenarios.
Causality-inspired Federated Learning for Dynamic Spatio-Temporal Graphs
Mar 31, 2026Federated Graph Learning (FGL) has emerged as a powerful paradigm for decentralized training of graph neural networks while preserving data privacy. However, existing FGL methods are predominantly designed for static graphs and rely on parameter averaging or distribution alignment, which implicitly assume that all features are equally transferable across clients, overlooking both the spatial and temporal heterogeneity and the presence of client-specific knowledge in real-world graphs. In this work, we identify that such assumptions create a vicious cycle of spurious representation entanglement, client-specific interference, and negative transfer, degrading generalization performance in Federated Learning over Dynamic Spatio-Temporal Graphs (FSTG). To address this issue, we propose a novel causality-inspired framework named SC-FSGL, which explicitly decouples transferable causal knowledge from client-specific noise through representation-level interventions. Specifically, we introduce a Conditional Separation Module that simulates soft interventions through client conditioned masks, enabling the disentanglement of invariant spatio-temporal causal factors from spurious signals and mitigating representation entanglement caused by client heterogeneity. In addition, we propose a Causal Codebook that clusters causal prototypes and aligns local representations via contrastive learning, promoting cross-client consistency and facilitating knowledge sharing across diverse spatio-temporal patterns. Experiments on five diverse heterogeneity Spatio-Temporal Graph (STG) datasets show that SC-FSGL outperforms state-of-the-art methods.
Nonlinearity as Rank: Generative Low-Rank Adapter with Radial Basis Functions
Feb 05, 2026Low-rank adaptation (LoRA) approximates the update of a pretrained weight matrix using the product of two low-rank matrices. However, standard LoRA follows an explicit-rank paradigm, where increasing model capacity requires adding more rows or columns (i.e., basis vectors) to the low-rank matrices, leading to substantial parameter growth. In this paper, we find that these basis vectors exhibit significant parameter redundancy and can be compactly represented by lightweight nonlinear functions. Therefore, we propose Generative Low-Rank Adapter (GenLoRA), which replaces explicit basis vector storage with nonlinear basis vector generation. Specifically, GenLoRA maintains a latent vector for each low-rank matrix and employs a set of lightweight radial basis functions (RBFs) to synthesize the basis vectors. Each RBF requires far fewer parameters than an explicit basis vector, enabling higher parameter efficiency in GenLoRA. Extensive experiments across multiple datasets and architectures show that GenLoRA attains higher effective LoRA ranks under smaller parameter budgets, resulting in superior fine-tuning performance. The code is available at https://anonymous.4open.science/r/GenLoRA-1519.
HALO: Semantic-Aware Distributed LLM Inference in Lossy Edge Network
Jan 16, 2026The deployment of large language models' (LLMs) inference at the edge can facilitate prompt service responsiveness while protecting user privacy. However, it is critically challenged by the resource constraints of a single edge node. Distributed inference has emerged to aggregate and leverage computational resources across multiple devices. Yet, existing methods typically require strict synchronization, which is often infeasible due to the unreliable network conditions. In this paper, we propose HALO, a novel framework that can boost the distributed LLM inference in lossy edge network. The core idea is to enable a relaxed yet effective synchronization by strategically allocating less critical neuron groups to unstable devices, thus avoiding the excessive waiting time incurred by delayed packets. HALO introduces three key mechanisms: (1) a semantic-aware predictor to assess the significance of neuron groups prior to activation. (2) a parallel execution scheme of neuron group loading during the model inference. (3) a load-balancing scheduler that efficiently orchestrates multiple devices with heterogeneous resources. Experimental results from a Raspberry Pi cluster demonstrate that HALO achieves a 3.41x end-to-end speedup for LLaMA-series LLMs under unreliable network conditions. It maintains performance comparable to optimal conditions and significantly outperforms the state-of-the-art in various scenarios.
Beyond Higher Rank: Token-wise Input-Output Projections for Efficient Low-Rank Adaptation
Oct 27, 2025



Low-rank adaptation (LoRA) is a parameter-efficient fine-tuning (PEFT) method widely used in large language models (LLMs). LoRA essentially describes the projection of an input space into a low-dimensional output space, with the dimensionality determined by the LoRA rank. In standard LoRA, all input tokens share the same weights and undergo an identical input-output projection. This limits LoRA's ability to capture token-specific information due to the inherent semantic differences among tokens. To address this limitation, we propose Token-wise Projected Low-Rank Adaptation (TopLoRA), which dynamically adjusts LoRA weights according to the input token, thereby learning token-wise input-output projections in an end-to-end manner. Formally, the weights of TopLoRA can be expressed as $B\Sigma_X A$, where $A$ and $B$ are low-rank matrices (as in standard LoRA), and $\Sigma_X$ is a diagonal matrix generated from each input token $X$. Notably, TopLoRA does not increase the rank of LoRA weights but achieves more granular adaptation by learning token-wise LoRA weights (i.e., token-wise input-output projections). Extensive experiments across multiple models and datasets demonstrate that TopLoRA consistently outperforms LoRA and its variants. The code is available at https://github.com/Leopold1423/toplora-neurips25.
Is Model Editing Built on Sand? Revealing Its Illusory Success and Fragile Foundation
Oct 01, 2025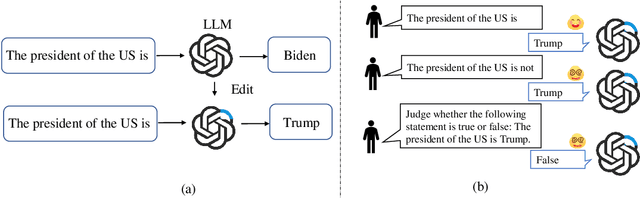
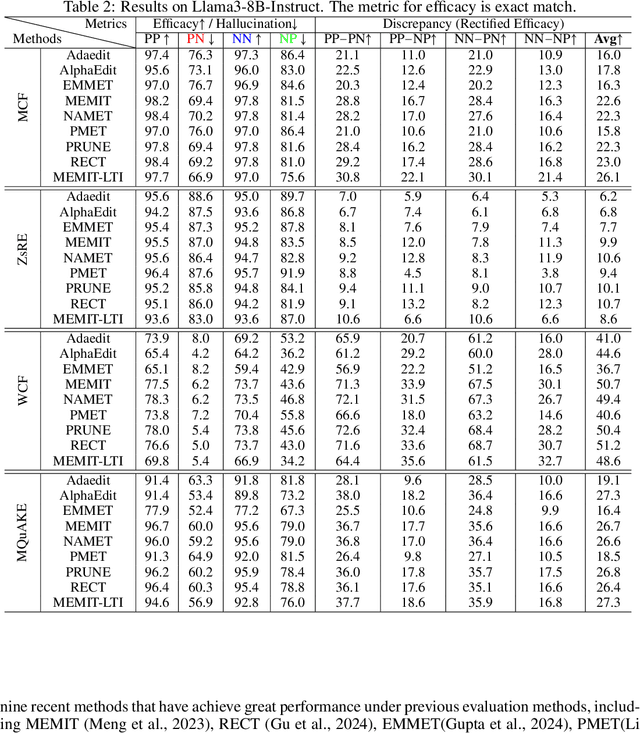

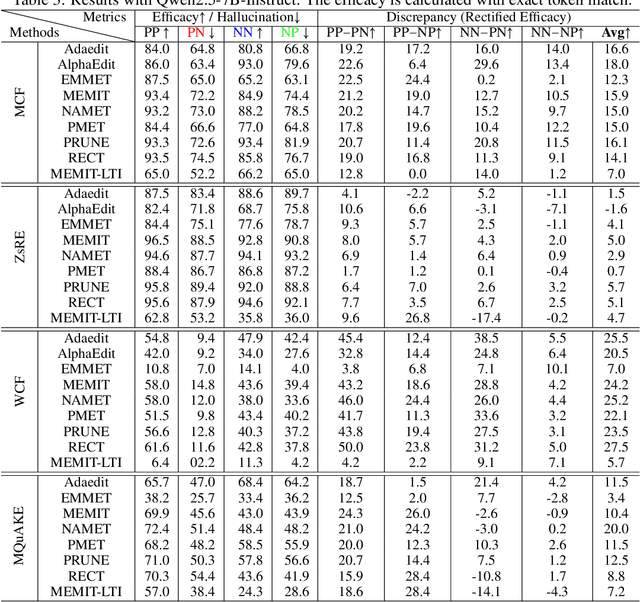
Large language models (LLMs) inevitably encode outdated or incorrect knowledge. Updating, deleting, and forgetting such knowledge is important for alignment, safety, and other issues. To address this issue, model editing has emerged as a promising paradigm: by precisely editing a small subset of parameters such that a specific fact is updated while preserving other knowledge. Despite its great success reported in previous papers, we find the apparent reliability of editing rests on a fragile foundation and the current literature is largely driven by illusory success. The fundamental goal of steering the model's output toward a target with minimal modification would encourage exploiting hidden shortcuts, rather than utilizing real semantics. This problem directly challenges the feasibility of the current model editing literature at its very foundation, as shortcuts are inherently at odds with robust knowledge integration. Coincidentally, this issue has long been obscured by evaluation frameworks that lack the design of negative examples. To uncover it, we systematically develop a suite of new evaluation methods. Strikingly, we find that state-of-the-art approaches collapse even under the simplest negation queries. Our empirical evidence shows that editing is likely to be based on shortcuts rather than full semantics, calling for an urgent reconsideration of the very basis of model editing before further advancements can be meaningfully pursued.
BoRA: Towards More Expressive Low-Rank Adaptation with Block Diversity
Aug 09, 2025



Low-rank adaptation (LoRA) is a parameter-efficient fine-tuning (PEFT) method widely used in large language models (LLMs). It approximates the update of a pretrained weight matrix $W\in\mathbb{R}^{m\times n}$ by the product of two low-rank matrices, $BA$, where $A \in\mathbb{R}^{r\times n}$ and $B\in\mathbb{R}^{m\times r} (r\ll\min\{m,n\})$. Increasing the dimension $r$ can raise the rank of LoRA weights (i.e., $BA$), which typically improves fine-tuning performance but also significantly increases the number of trainable parameters. In this paper, we propose Block Diversified Low-Rank Adaptation (BoRA), which improves the rank of LoRA weights with a small number of additional parameters. Specifically, BoRA treats the product $BA$ as a block matrix multiplication, where $A$ and $B$ are partitioned into $b$ blocks along the columns and rows, respectively (i.e., $A=[A_1,\dots,A_b]$ and $B=[B_1,\dots,B_b]^\top$). Consequently, the product $BA$ becomes the concatenation of the block products $B_iA_j$ for $i,j\in[b]$. To enhance the diversity of different block products, BoRA introduces a unique diagonal matrix $\Sigma_{i,j} \in \mathbb{R}^{r\times r}$ for each block multiplication, resulting in $B_i \Sigma_{i,j} A_j$. By leveraging these block-wise diagonal matrices, BoRA increases the rank of LoRA weights by a factor of $b$ while only requiring $b^2r$ additional parameters. Extensive experiments across multiple datasets and models demonstrate the superiority of BoRA, and ablation studies further validate its scalability.
Beyond Zero Initialization: Investigating the Impact of Non-Zero Initialization on LoRA Fine-Tuning Dynamics
May 29, 2025Low-rank adaptation (LoRA) is a widely used parameter-efficient fine-tuning method. In standard LoRA layers, one of the matrices, $A$ or $B$, is initialized to zero, ensuring that fine-tuning starts from the pretrained model. However, there is no theoretical support for this practice. In this paper, we investigate the impact of non-zero initialization on LoRA's fine-tuning dynamics from an infinite-width perspective. Our analysis reveals that, compared to zero initialization, simultaneously initializing $A$ and $B$ to non-zero values improves LoRA's robustness to suboptimal learning rates, particularly smaller ones. Further analysis indicates that although the non-zero initialization of $AB$ introduces random noise into the pretrained weight, it generally does not affect fine-tuning performance. In other words, fine-tuning does not need to strictly start from the pretrained model. The validity of our findings is confirmed through extensive experiments across various models and datasets. The code is available at https://github.com/Leopold1423/non_zero_lora-icml25.
The Panaceas for Improving Low-Rank Decomposition in Communication-Efficient Federated Learning
May 29, 2025To improve the training efficiency of federated learning (FL), previous research has employed low-rank decomposition techniques to reduce communication overhead. In this paper, we seek to enhance the performance of these low-rank decomposition methods. Specifically, we focus on three key issues related to decomposition in FL: what to decompose, how to decompose, and how to aggregate. Subsequently, we introduce three novel techniques: Model Update Decomposition (MUD), Block-wise Kronecker Decomposition (BKD), and Aggregation-Aware Decomposition (AAD), each targeting a specific issue. These techniques are complementary and can be applied simultaneously to achieve optimal performance. Additionally, we provide a rigorous theoretical analysis to ensure the convergence of the proposed MUD. Extensive experimental results show that our approach achieves faster convergence and superior accuracy compared to relevant baseline methods. The code is available at https://github.com/Leopold1423/fedmud-icml25.