 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Attention Closes: How LLMs Lose the Thread in Multi-Turn Interaction
May 13, 2026Large language models can follow complex instructions in a single turn, yet over long multi-turn interactions they often lose the thread of instructions, persona, and rules. This degradation has been measured behaviorally but not mechanistically explained. We propose a channel-transition account: goal-defining tokens become less accessible through attention, while goal-related information may persist in residual representations. We introduce the Goal Accessibility Ratio (GAR), measuring attention from generated tokens to task-defining goal tokens, and combine it with sliding-window ablations and residual-stream probes. When attention to instructions closes, what survives reveals architecture. Across architectures, the transition yields qualitatively distinct failure modes: some models preserve goal-conditioned behavior at vanishing attention, others fail despite decodable residual goal information, and the layer at which this encoding emerges varies from 2 to 27. A within-model causal ablation that force-closes the attention channel in Mistral collapses recall from near-perfect to 11% on a 20-fact retention task and raises persona-constraint violations above an adversarial-pressure baseline without user pressure, with both effects emerging at the predictable crossover turn. Linear probes recover per-episode recall outcomes from residual representations with AUC up to 0.99 across all four primary architectures, while input embeddings remain at chance. Across architectures and model scales, the gap between attention loss and residual decodability predicts whether goal-conditioned behavior survives channel closure. We contribute GAR as a diagnostic, the channel-transition framework as a controlled mechanistic account, and a parametric prediction of failure timing under windowed attention closure.
A Survey on LLM-based Conversational User Simulation
Apr 27, 2026User simulation has long played a vital role in computer science due to its potential to support a wide range of applications. Language, as the primary medium of human communication, forms the foundation of social interaction and behavior. Consequently, simulating conversational behavior has become a key area of study. Recent advancements in large language models (LLMs) have significantly catalyzed progress in this domain by enabling high-fidelity generation of synthetic user conversation. In this paper, we survey recent advancements in LLM-based conversational user simulation. We introduce a novel taxonomy covering user granularity and simulation objectives. Additionally, we systematically analyze core techniques and evaluation methodologies. We aim to keep the research community informed of the latest advancements in conversational user simulation and to further facilitate future research by identifying open challenges and organizing existing work under a unified framework.
ViT-AdaLA: Adapting Vision Transformers with Linear Attention
Mar 17, 2026Vision Transformers (ViTs) based vision foundation models (VFMs) have achieved remarkable performance across diverse vision tasks, but suffer from quadratic complexity that limits scalability to long sequences. Existing linear attention approaches for ViTs are typically trained from scratch, requiring substantial computational resources, while linearization-based methods developed for large language model decoders do not transfer well to ViTs. To address these challenges, we propose ViT-AdaLA, a novel framework for effectively adapting and transferring prior knowledge from VFMs to linear attention ViTs. ViT-AdaLA consists of three stages: attention alignment, feature alignment, and supervised fine-tuning. In the attention alignment stage, we align vanilla linear attention with the original softmax-based attention in each block to approximate the behavior of softmax attention. However, residual approximation errors inevitably accumulate across layers. We mitigate this by fine-tuning the linearized ViT to align its final-layer features with a frozen softmax VFM teacher. Finally, the adapted prior knowledge is transferred to downstream tasks through supervised fine-tuning. Extensive experiments on classification and segmentation tasks demonstrate the effectiveness and generality of ViT-AdaLA over various state-of-the-art linear attention counterpart.
ImageEdit-R1: Boosting Multi-Agent Image Editing via Reinforcement Learning
Mar 09, 2026With the rapid advancement of commercial multi-modal models, image editing has garnered significant attention due to its widespread applicability in daily life. Despite impressive progress, existing image editing systems, particularly closed-source or proprietary models, often struggle with complex, indirect, or multi-step user instructions. These limitations hinder their ability to perform nuanced, context-aware edits that align with human intent. In this work, we propose ImageEdit-R1, a multi-agent framework for intelligent image editing that leverages reinforcement learning to coordinate high-level decision-making across a set of specialized, pretrained vision-language and generative agents. Each agent is responsible for distinct capabilities--such as understanding user intent, identifying regions of interest, selecting appropriate editing actions, and synthesizing visual content--while reinforcement learning governs their collaboration to ensure coherent and goal-directed behavior. Unlike existing approaches that rely on monolithic models or hand-crafted pipelines, our method treats image editing as a sequential decision-making problem, enabling dynamic and context-aware editing strategies. Experimental results demonstrate that ImageEdit-R1 consistently outperforms both individual closed-source diffusion models and alternative multi-agent framework baselines across multiple image editing datasets.
InfinityStory: Unlimited Video Generation with World Consistency and Character-Aware Shot Transitions
Mar 04, 2026Generating long-form storytelling videos with consistent visual narratives remains a significant challenge in video synthesis. We present a novel framework, dataset, and a model that address three critical limitations: background consistency across shots, seamless multi-subject shot-to-shot transitions, and scalability to hour-long narratives. Our approach introduces a background-consistent generation pipeline that maintains visual coherence across scenes while preserving character identity and spatial relationships. We further propose a transition-aware video synthesis module that generates smooth shot transitions for complex scenarios involving multiple subjects entering or exiting frames, going beyond the single-subject limitations of prior work. To support this, we contribute with a synthetic dataset of 10,000 multi-subject transition sequences covering underrepresented dynamic scene compositions. On VBench, InfinityStory achieves the highest Background Consistency (88.94), highest Subject Consistency (82.11), and the best overall average rank (2.80), showing improved stability, smoother transitions, and better temporal coherence.
Drift No More? Context Equilibria in Multi-Turn LLM Interactions
Oct 09, 2025Large Language Models (LLMs) excel at single-turn tasks such as instruction following and summarization, yet real-world deployments require sustained multi-turn interactions where user goals and conversational context persist and evolve. A recurring challenge in this setting is context drift: the gradual divergence of a model's outputs from goal-consistent behavior across turns. Unlike single-turn errors, drift unfolds temporally and is poorly captured by static evaluation metrics. In this work, we present a study of context drift in multi-turn interactions and propose a simple dynamical framework to interpret its behavior. We formalize drift as the turn-wise KL divergence between the token-level predictive distributions of the test model and a goal-consistent reference model, and propose a recurrence model that interprets its evolution as a bounded stochastic process with restoring forces and controllable interventions. We instantiate this framework in both synthetic long-horizon rewriting tasks and realistic user-agent simulations such as in $\tau$-Bench, measuring drift for several open-weight LLMs that are used as user simulators. Our experiments consistently reveal stable, noise-limited equilibria rather than runaway degradation, and demonstrate that simple reminder interventions reliably reduce divergence in line with theoretical predictions. Together, these results suggest that multi-turn drift can be understood as a controllable equilibrium phenomenon rather than as inevitable decay, providing a foundation for studying and mitigating context drift in extended interactions.
Steering MoE LLMs via Expert (De)Activation
Sep 11, 2025



Mixture-of-Experts (MoE) in Large Language Models (LLMs) routes each token through a subset of specialized Feed-Forward Networks (FFN), known as experts. We present SteerMoE, a framework for steering MoE models by detecting and controlling behavior-linked experts. Our detection method identifies experts with distinct activation patterns across paired inputs exhibiting contrasting behaviors. By selectively (de)activating such experts during inference, we control behaviors like faithfulness and safety without retraining or modifying weights. Across 11 benchmarks and 6 LLMs, our steering raises safety by up to +20% and faithfulness by +27%. In adversarial attack mode, it drops safety by -41% alone, and -100% when combined with existing jailbreak methods, bypassing all safety guardrails and exposing a new dimension of alignment faking hidden within experts.
FIFA: Unified Faithfulness Evaluation Framework for Text-to-Video and Video-to-Text Generation
Jul 09, 2025

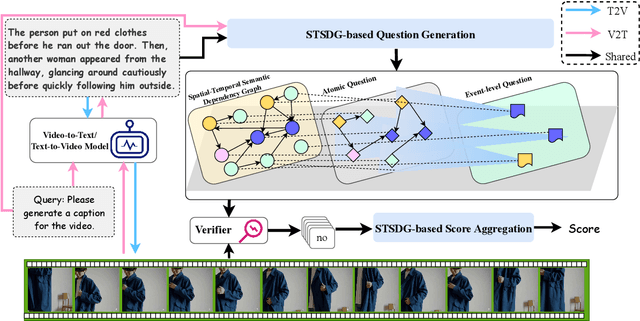
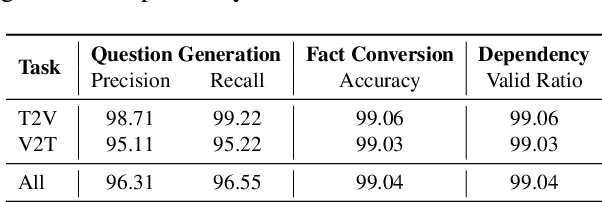
Video Multimodal Large Language Models (VideoMLLMs) have achieved remarkable progress in both Video-to-Text and Text-to-Video tasks. However, they often suffer fro hallucinations, generating content that contradicts the visual input. Existing evaluation methods are limited to one task (e.g., V2T) and also fail to assess hallucinations in open-ended, free-form responses. To address this gap, we propose FIFA, a unified FaIthFulness evAluation framework that extracts comprehensive descriptive facts, models their semantic dependencies via a Spatio-Temporal Semantic Dependency Graph, and verifies them using VideoQA models. We further introduce Post-Correction, a tool-based correction framework that revises hallucinated content. Extensive experiments demonstrate that FIFA aligns more closely with human judgment than existing evaluation methods, and that Post-Correction effectively improves factual consistency in both text and video generation.
Context-Informed Grounding Supervision
Jun 18, 2025Large language models (LLMs) are often supplemented with external knowledge to provide information not encoded in their parameters or to reduce hallucination. In such cases, we expect the model to generate responses by grounding its response in the provided external context. However, prior work has shown that simply appending context at inference time does not ensure grounded generation. To address this, we propose Context-INformed Grounding Supervision (CINGS), a post-training supervision in which the model is trained with relevant context prepended to the response, while computing the loss only over the response tokens and masking out the context. Our experiments demonstrate that models trained with CINGS exhibit stronger grounding in both textual and visual domains compared to standard instruction-tuned models. In the text domain, CINGS outperforms other training methods across 11 information-seeking datasets and is complementary to inference-time grounding techniques. In the vision-language domain, replacing a vision-language model's LLM backbone with a CINGS-trained model reduces hallucinations across four benchmarks and maintains factual consistency throughout the generated response. This improved grounding comes without degradation in general downstream performance. Finally, we analyze the mechanism underlying the enhanced grounding in CINGS and find that it induces a shift in the model's prior knowledge and behavior, implicitly encouraging greater reliance on the external context.
MS4UI: A Dataset for Multi-modal Summarization of User Interface Instructional Videos
Jun 14, 2025We study multi-modal summarization for instructional videos, whose goal is to provide users an efficient way to learn skills in the form of text instructions and key video frames. We observe that existing benchmarks focus on generic semantic-level video summarization, and are not suitable for providing step-by-step executable instructions and illustrations, both of which are crucial for instructional videos. We propose a novel benchmark for user interface (UI) instructional video summarization to fill the gap. We collect a dataset of 2,413 UI instructional videos, which spans over 167 hours. These videos are manually annotated for video segmentation, text summarization, and video summarization, which enable the comprehensive evaluations for concise and executable video summarization. We conduct extensive experiments on our collected MS4UI dataset, which suggest that state-of-the-art multi-modal summarization methods struggle on UI video summarization, and highlight the importance of new methods for UI instructional video summarization.