 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified 2D and 3D Pre-Training of Molecular Representations
Jul 14, 2022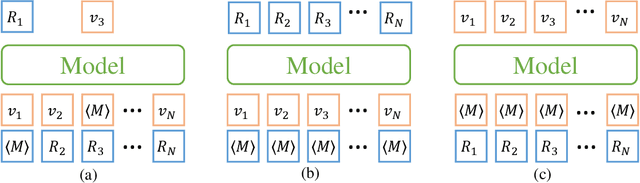
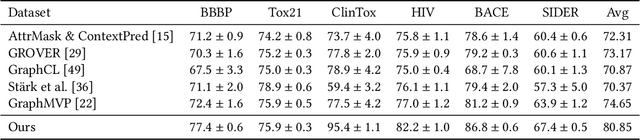
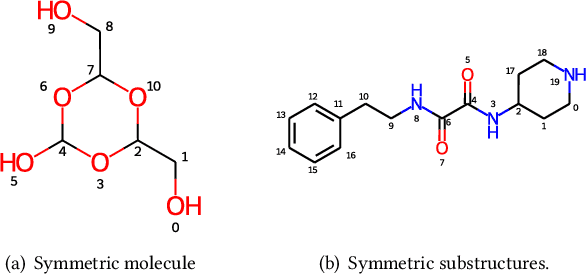
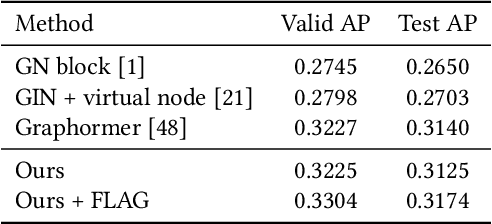
Molecular representation learning has attracted much attention recently. A molecule can be viewed as a 2D graph with nodes/atoms connected by edges/bonds, and can also be represented by a 3D conformation with 3-dimensional coordinates of all atoms. We note that most previous work handles 2D and 3D information separately, while jointly leveraging these two sources may foster a more informative representation. In this work, we explore this appealing idea and propose a new representation learning method based on a unified 2D and 3D pre-training. Atom coordinates and interatomic distances are encoded and then fused with atomic representations through graph neural networks. The model is pre-trained on three tasks: reconstruction of masked atoms and coordinates, 3D conformation generation conditioned on 2D graph, and 2D graph generation conditioned on 3D conformation. We evaluate our method on 11 downstream molecular property prediction tasks: 7 with 2D information only and 4 with both 2D and 3D information. Our method achieves state-of-the-art results on 10 tasks, and the average improvement on 2D-only tasks is 8.3%. Our method also achieves significant improvement on two 3D conformation generation tasks.
ReLyMe: Improving Lyric-to-Melody Generation by Incorporating Lyric-Melody Relationships
Jul 12, 2022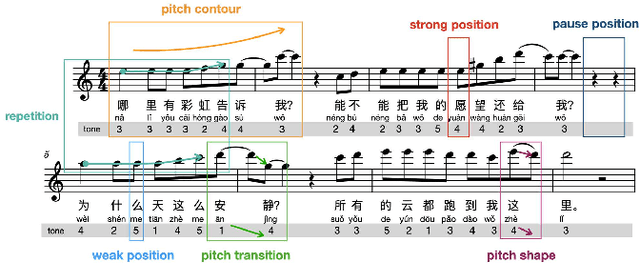
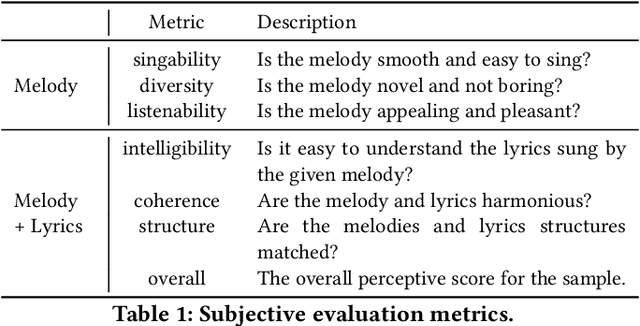
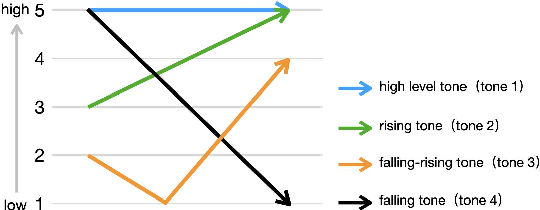
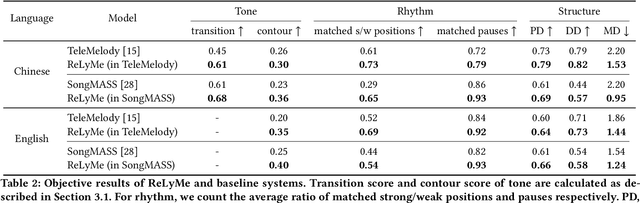
Lyric-to-melody generation, which generates melody according to given lyrics, is one of the most important automatic music composition tasks. With the rapid development of deep learning, previous works address this task with end-to-end neural network models. However, deep learning models cannot well capture the strict but subtle relationships between lyrics and melodies, which compromises the harmony between lyrics and generated melodies. In this paper, we propose ReLyMe, a method that incorporates Relationships between Lyrics and Melodies from music theory to ensure the harmony between lyrics and melodies. Specifically, we first introduce several principles that lyrics and melodies should follow in terms of tone, rhythm, and structure relationships. These principles are then integrated into neural network lyric-to-melody models by adding corresponding constraints during the decoding process to improve the harmony between lyrics and melodies. We use a series of objective and subjective metrics to evaluate the generated melodies. Experiments on both English and Chinese song datasets show the effectiveness of ReLyMe, demonstrating the superiority of incorporating lyric-melody relationships from the music domain into neural lyric-to-melody generation.
A Study of Syntactic Multi-Modality in Non-Autoregressive Machine Translation
Jul 09, 2022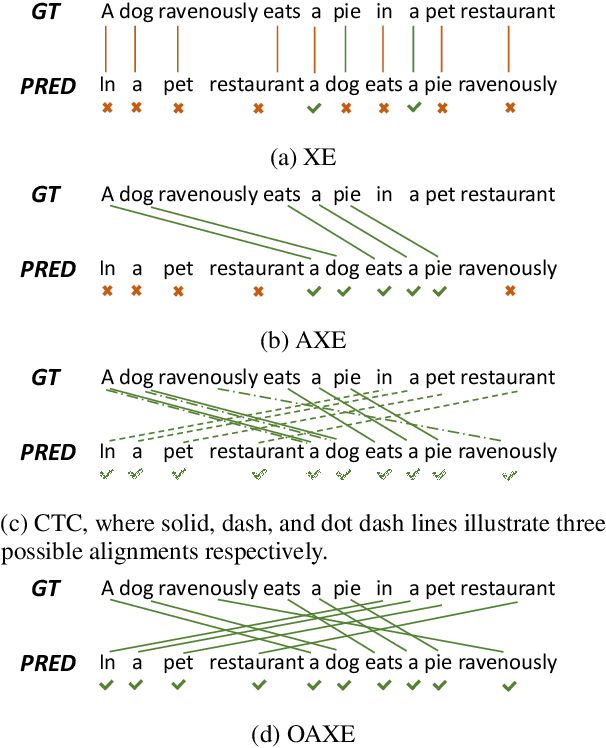
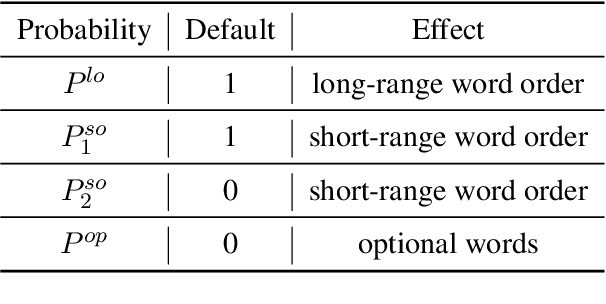
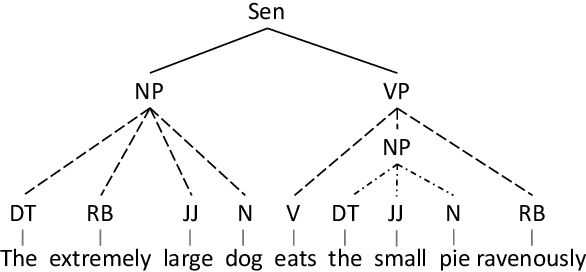
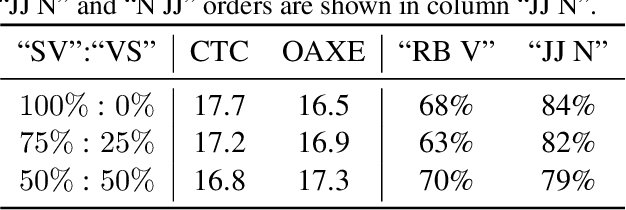
It is difficult for non-autoregressive translation (NAT) models to capture the multi-modal distribution of target translations due to their conditional independence assumption, which is known as the "multi-modality problem", including the lexical multi-modality and the syntactic multi-modality. While the first one has been well studied, the syntactic multi-modality brings severe challenge to the standard cross entropy (XE) loss in NAT and is under studied. In this paper, we conduct a systematic study on the syntactic multi-modality problem. Specifically, we decompose it into short- and long-range syntactic multi-modalities and evaluate several recent NAT algorithms with advanced loss functions on both carefully designed synthesized datasets and real datasets. We find that the Connectionist Temporal Classification (CTC) loss and the Order-Agnostic Cross Entropy (OAXE) loss can better handle short- and long-range syntactic multi-modalities respectively. Furthermore, we take the best of both and design a new loss function to better handle the complicated syntactic multi-modality in real-world datasets. To facilitate practical usage, we provide a guide to use different loss functions for different kinds of syntactic multi-modality.
Building Multilingual Machine Translation Systems That Serve Arbitrary X-Y Translations
Jun 30, 2022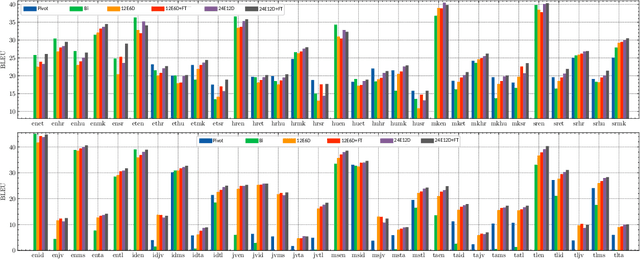
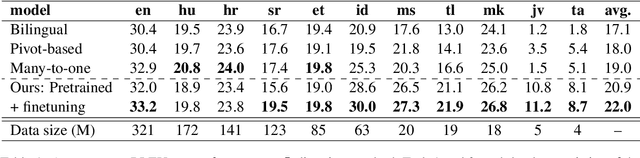
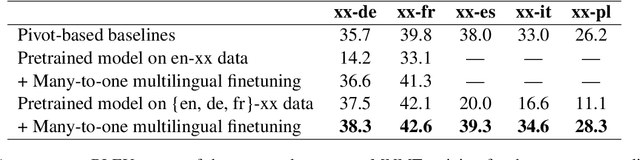
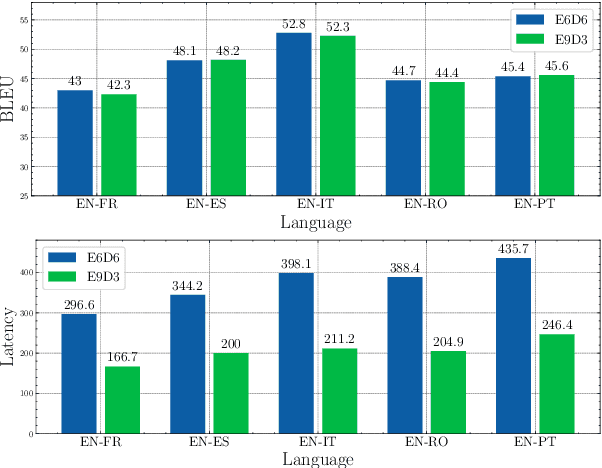
Multilingual Neural Machine Translation (MNMT) enables one system to translate sentences from multiple source languages to multiple target languages, greatly reducing deployment costs compared with conventional bilingual systems. The MNMT training benefit, however, is often limited to many-to-one directions. The model suffers from poor performance in one-to-many and many-to-many with zero-shot setup. To address this issue, this paper discusses how to practically build MNMT systems that serve arbitrary X-Y translation directions while leveraging multilinguality with a two-stage training strategy of pretraining and finetuning. Experimenting with the WMT'21 multilingual translation task, we demonstrate that our systems outperform the conventional baselines of direct bilingual models and pivot translation models for most directions, averagely giving +6.0 and +4.1 BLEU, without the need for architecture change or extra data collection. Moreover, we also examine our proposed approach in an extremely large-scale data setting to accommodate practical deployment scenarios.
RetroGraph: Retrosynthetic Planning with Graph Search
Jun 23, 2022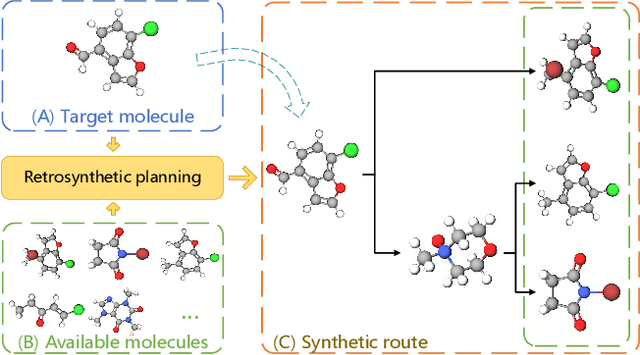
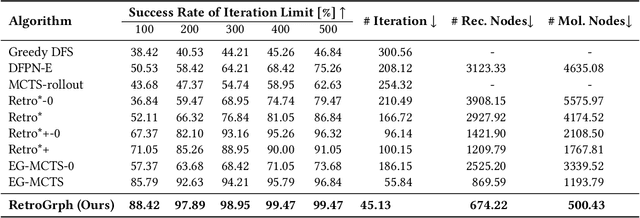
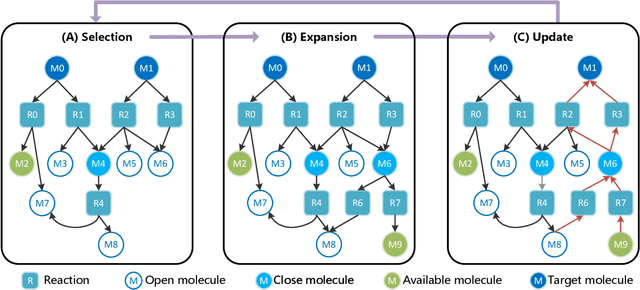

Retrosynthetic planning, which aims to find a reaction pathway to synthesize a target molecule, plays an important role in chemistry and drug discovery. This task is usually modeled as a search problem. Recently, data-driven methods have attracted many research interests and shown promising results for retrosynthetic planning. We observe that the same intermediate molecules are visited many times in the searching process, and they are usually independently treated in previous tree-based methods (e.g., AND-OR tree search, Monte Carlo tree search). Such redundancies make the search process inefficient. We propose a graph-based search policy that eliminates the redundant explorations of any intermediate molecules. As searching over a graph is more complicated than over a tree, we further adopt a graph neural network to guide the search over graphs. Meanwhile, our method can search a batch of targets together in the graph and remove the inter-target duplication in the tree-based search methods. Experimental results on two datasets demonstrate the effectiveness of our method. Especially on the widely used USPTO benchmark, we improve the search success rate to 99.47%, advancing previous state-of-the-art performance for 2.6 points.
SMT-DTA: Improving Drug-Target Affinity Prediction with Semi-supervised Multi-task Training
Jun 22, 2022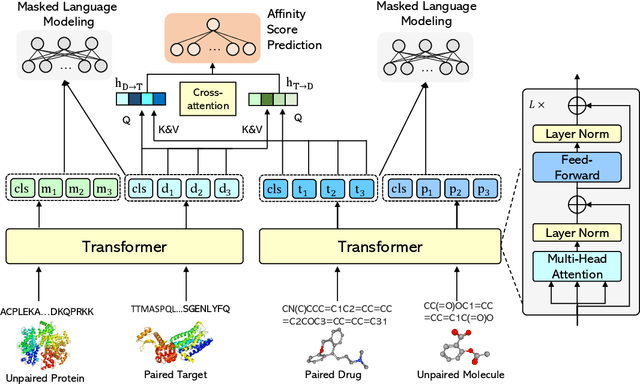
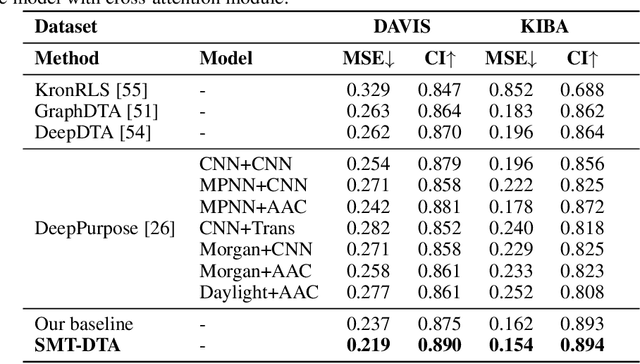
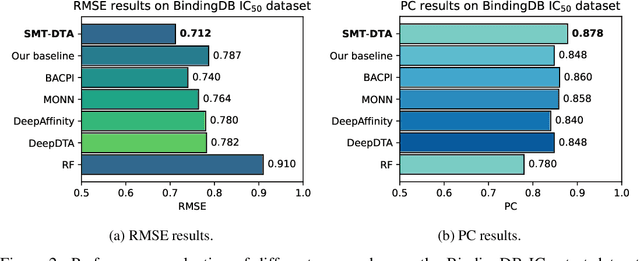

Drug-Target Affinity (DTA) prediction is an essential task for drug discovery and pharmaceutical research. Accurate predictions of DTA can greatly benefit the design of new drug. As wet experiments are costly and time consuming, the supervised data for DTA prediction is extremely limited. This seriously hinders the application of deep learning based methods, which require a large scale of supervised data. To address this challenge and improve the DTA prediction accuracy, we propose a framework with several simple yet effective strategies in this work: (1) a multi-task training strategy, which takes the DTA prediction and the masked language modeling (MLM) task on the paired drug-target dataset; (2) a semi-supervised training method to empower the drug and target representation learning by leveraging large-scale unpaired molecules and proteins in training, which differs from previous pre-training and fine-tuning methods that only utilize molecules or proteins in pre-training; and (3) a cross-attention module to enhance the interaction between drug and target representation. Extensive experiments are conducted on three real-world benchmark datasets: BindingDB, DAVIS and KIBA. The results show that our framework significantly outperforms existing methods and achieves state-of-the-art performances, e.g., $0.712$ RMSE on BindingDB IC$_{50}$ measurement with more than $5\%$ improvement than previous best work. In addition, case studies on specific drug-target binding activities, drug feature visualizations, and real-world applications demonstrate the great potential of our work. The code and data are released at https://github.com/QizhiPei/SMT-DTA
Transcormer: Transformer for Sentence Scoring with Sliding Language Modeling
Jun 05, 2022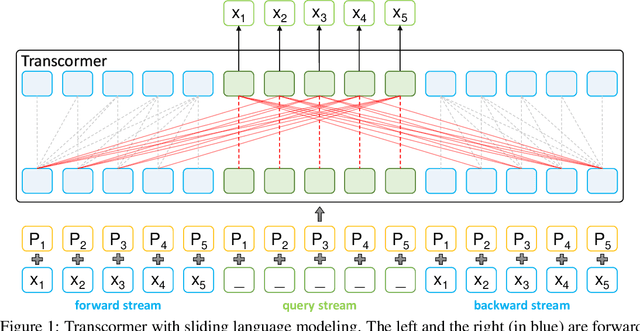

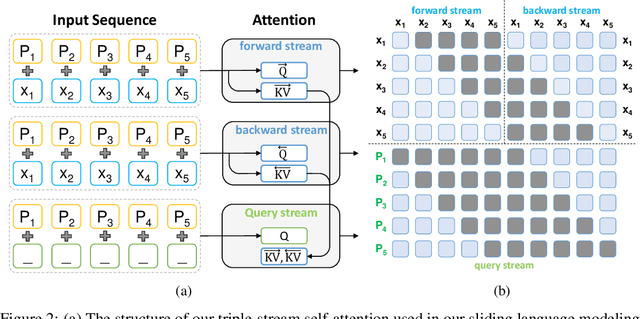
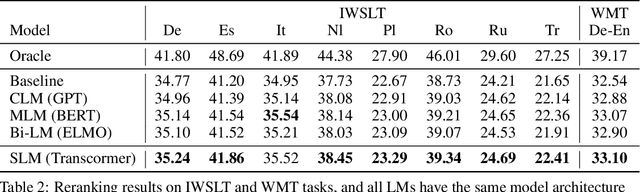
Sentence scoring aims at measuring the likelihood score of a sentence and is widely used in many natural language processing scenarios, like reranking, which is to select the best sentence from multiple candidates. Previous works on sentence scoring mainly adopted either causal language modeling (CLM) like GPT or masked language modeling (MLM) like BERT, which have some limitations: 1) CLM only utilizes unidirectional information for the probability estimation of a sentence without considering bidirectional context, which affects the scoring quality; 2) MLM can only estimate the probability of partial tokens at a time and thus requires multiple forward passes to estimate the probability of the whole sentence, which incurs large computation and time cost. In this paper, we propose \textit{Transcormer} -- a Transformer model with a novel \textit{sliding language modeling} (SLM) for sentence scoring. Specifically, our SLM adopts a triple-stream self-attention mechanism to estimate the probability of all tokens in a sentence with bidirectional context and only requires a single forward pass. SLM can avoid the limitations of CLM (only unidirectional context) and MLM (multiple forward passes) and inherit their advantages, and thus achieve high effectiveness and efficiency in scoring. Experimental results on multiple tasks demonstrate that our method achieves better performance than other language modelings.
BinauralGrad: A Two-Stage Conditional Diffusion Probabilistic Model for Binaural Audio Synthesis
May 30, 2022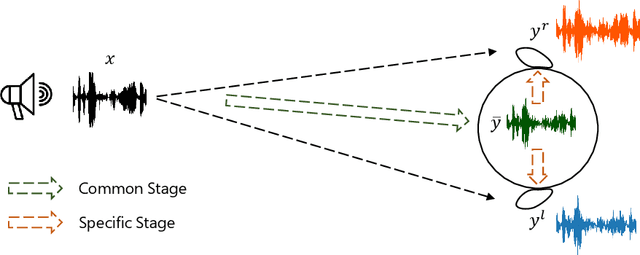

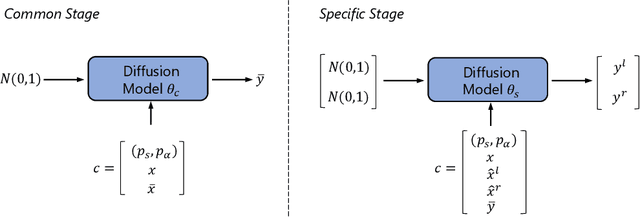

Binaural audio plays a significant role in constructing immersive augmented and virtual realities. As it is expensive to record binaural audio from the real world, synthesizing them from mono audio has attracted increasing attention. This synthesis process involves not only the basic physical warping of the mono audio, but also room reverberations and head/ear related filtrations, which, however, are difficult to accurately simulate in traditional digital signal processing. In this paper, we formulate the synthesis process from a different perspective by decomposing the binaural audio into a common part that shared by the left and right channels as well as a specific part that differs in each channel. Accordingly, we propose BinauralGrad, a novel two-stage framework equipped with diffusion models to synthesize them respectively. Specifically, in the first stage, the common information of the binaural audio is generated with a single-channel diffusion model conditioned on the mono audio, based on which the binaural audio is generated by a two-channel diffusion model in the second stage. Combining this novel perspective of two-stage synthesis with advanced generative models (i.e., the diffusion models),the proposed BinauralGrad is able to generate accurate and high-fidelity binaural audio samples. Experiment results show that on a benchmark dataset, BinauralGrad outperforms the existing baselines by a large margin in terms of both object and subject evaluation metrics (Wave L2: 0.128 vs. 0.157, MOS: 3.80 vs. 3.61). The generated audio samples are available online.
Tiered Reinforcement Learning: Pessimism in the Face of Uncertainty and Constant Regret
May 25, 2022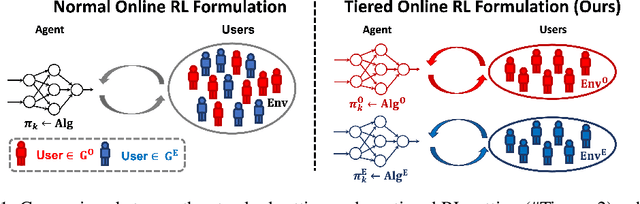
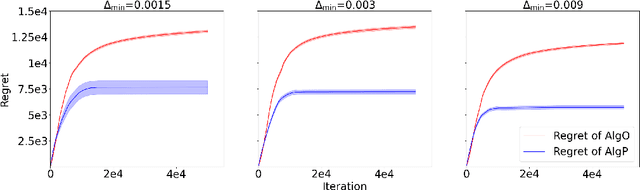
We propose a new learning framework that captures the tiered structure of many real-world user-interaction applications, where the users can be divided into two groups based on their different tolerance on exploration risks and should be treated separately. In this setting, we simultaneously maintain two policies $\pi^{\text{O}}$ and $\pi^{\text{E}}$: $\pi^{\text{O}}$ ("O" for "online") interacts with more risk-tolerant users from the first tier and minimizes regret by balancing exploration and exploitation as usual, while $\pi^{\text{E}}$ ("E" for "exploit") exclusively focuses on exploitation for risk-averse users from the second tier utilizing the data collected so far. An important question is whether such a separation yields advantages over the standard online setting (i.e., $\pi^{\text{E}}=\pi^{\text{O}}$) for the risk-averse users. We individually consider the gap-independent vs.~gap-dependent settings. For the former, we prove that the separation is indeed not beneficial from a minimax perspective. For the latter, we show that if choosing Pessimistic Value Iteration as the exploitation algorithm to produce $\pi^{\text{E}}$, we can achieve a constant regret for risk-averse users independent of the number of episodes $K$, which is in sharp contrast to the $\Omega(\log K)$ regret for any online RL algorithms in the same setting, while the regret of $\pi^{\text{O}}$ (almost) maintains its online regret optimality and does not need to compromise for the success of $\pi^{\text{E}}$.
NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
May 10, 2022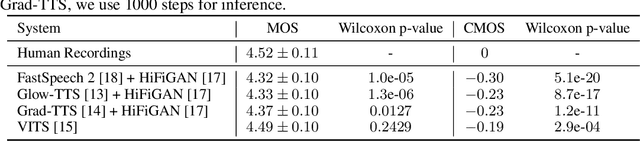
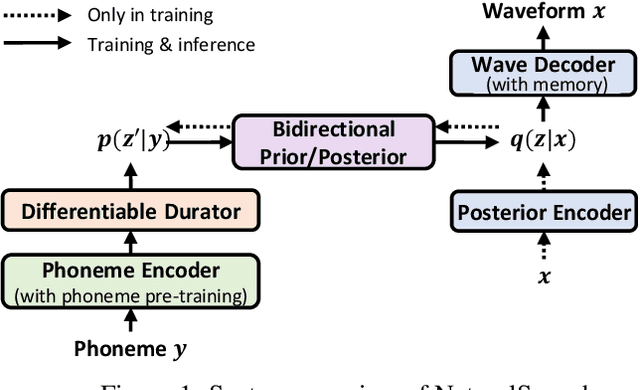
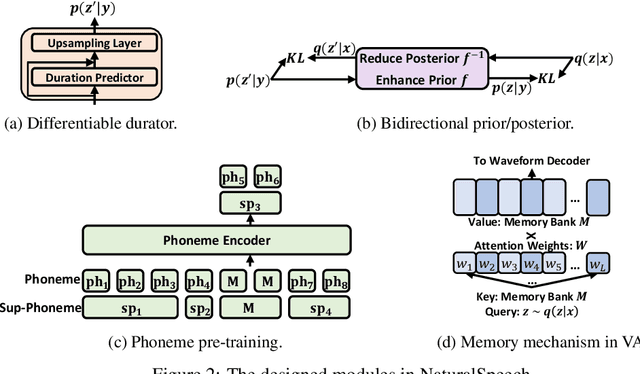
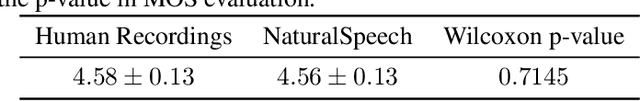
Text to speech (TTS) has made rapid progress in both academia and industry in recent years. Some questions naturally arise that whether a TTS system can achieve human-level quality, how to define/judge that quality and how to achieve it. In this paper, we answer these questions by first defining the human-level quality based on the statistical significance of subjective measure and introducing appropriate guidelines to judge it, and then developing a TTS system called NaturalSpeech that achieves human-level quality on a benchmark dataset. Specifically, we leverage a variational autoencoder (VAE) for end-to-end text to waveform generation, with several key modules to enhance the capacity of the prior from text and reduce the complexity of the posterior from speech, including phoneme pre-training, differentiable duration modeling, bidirectional prior/posterior modeling, and a memory mechanism in VAE. Experiment evaluations on popular LJSpeech dataset show that our proposed NaturalSpeech achieves -0.01 CMOS (comparative mean opinion score) to human recordings at the sentence level, with Wilcoxon signed rank test at p-level p >> 0.05, which demonstrates no statistically significant difference from human recordings for the first time on this dataset.