 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorizing Engram: Sharing Latents Across N-Gram Embeddings is Beneficial in LLMs
Jun 06, 2026Modern language models represent text using discrete token-level embeddings, which forces recurring multi-token patterns to be learned implicitly across Transformer layers. Both Over-tokenized Transformers and Engram attempt to address this limitation by explicitly incorporating multi-token (n-gram) memories. However, they rely on separate hash tables for each n-gram order, which introduces hash collisions and prevents nested n-grams from sharing the underlying latent structures. To address these issues, we propose Tensorized Engram (TN-gram), a compact memory module that represents tensorized n-gram embeddings through shared factors in the Canonical Polyadic (CP) form. TN-gram learns shared token-position factors together with order-absorption vectors to encode the embeddings of different n-gram order. Comprehensive experiments demonstrate that TN-gram matches or even outperforms Engram-style n-gram modules while requiring much fewer parameters.
Joint Training Scattering Matrix Learning and Channel Estimation for Beyond-Diagonal Reconfigurable Intelligent Surfaces
Mar 26, 2026Beyond-diagonal reconfigurable intelligent surface (BD-RIS) generalizes the conventional diagonal RIS (D-RIS) by introducing tunable inter-element connections, offering enhanced wave manipulation capabilities. However, realizing the advantages of BD-RIS requires accurate channel state information (CSI), whose acquisition becomes significantly more challenging due to the increased number of channel coefficients, leading to prohibitively large pilot training overhead in BD-RIS-aided multi-user multiple-input multiple-output (MU-MIMO) systems. Existing studies reduce pilot overhead by exploiting the channel correlations induced by the Kronecker-product or multi-linear structure of BD-RIS-aided channels, which neglect the spatial correlation among antennas and the statistical correlation across RIS-user channels. In this paper, we propose a learning-based channel estimation framework, namely the joint training scattering matrix learning and channel estimation framework (JTSMLCEF), which jointly optimizes the BD-RIS training scattering matrix and estimates the cascaded channels in an end-to-end manner to achieve accurate channel estimation and reduce the pilot overhead. The proposed JTSMLCEF follows a two-phase channel estimation protocol to enable adaptive training scattering matrix optimization with a training scattering matrix optimizer (TSMO) and cascaded channel estimation with a dual-attention channel estimator (DACE). Specifically, the DACE is designed with intra-user and inter-user attention modules to capture the multi-dimensional correlations in multi-user cascaded channels. Simulation results demonstrate the superiority of JTSMLCEF. Compared with the current state-of-the-art method, it reduces the pilot overhead by $80\%$ while further reducing the normalized mean squared error (NMSE) by $82.6\%$ and $92.5\%$ in indoor and urban micro-cell (UMi) scenarios, respectively.
KromHC: Manifold-Constrained Hyper-Connections with Kronecker-Product Residual Matrices
Jan 29, 2026The success of Hyper-Connections (HC) in neural networks (NN) has also highlighted issues related to its training instability and restricted scalability. The Manifold-Constrained Hyper-Connections (mHC) mitigate these challenges by projecting the residual connection space onto a Birkhoff polytope, however, it faces two issues: 1) its iterative Sinkhorn-Knopp (SK) algorithm does not always yield exact doubly stochastic residual matrices; 2) mHC incurs a prohibitive $\mathcal{O}(n^3C)$ parameter complexity with $n$ as the width of the residual stream and $C$ as the feature dimension. The recently proposed mHC-lite reparametrizes the residual matrix via the Birkhoff-von-Neumann theorem to guarantee double stochasticity, but also faces a factorial explosion in its parameter complexity, $\mathcal{O} \left( nC \cdot n! \right)$. To address both challenges, we propose \textbf{KromHC}, which uses the \underline{Kro}necker products of smaller doubly stochastic matrices to parametrize the residual matrix in \underline{mHC}. By enforcing manifold constraints across the factor residual matrices along each mode of the tensorized residual stream, KromHC guarantees exact double stochasticity of the residual matrices while reducing parameter complexity to $\mathcal{O}(n^2C)$. Comprehensive experiments demonstrate that KromHC matches or even outperforms state-of-the-art (SOTA) mHC variants, while requiring significantly fewer trainable parameters. The code is available at \texttt{https://github.com/wz1119/KromHC}.
RefineBridge: Generative Bridge Models Improve Financial Forecasting by Foundation Models
Dec 25, 2025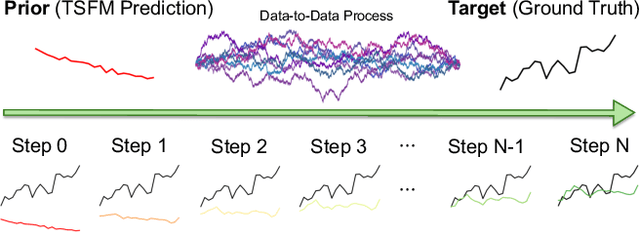
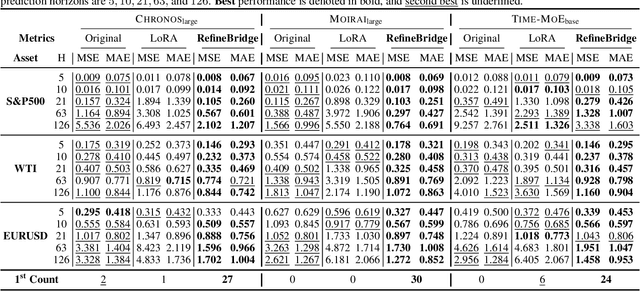
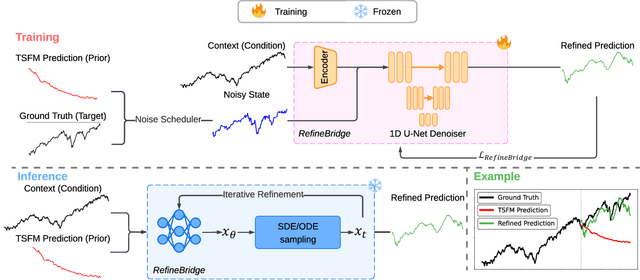
Financial time series forecasting is particularly challenging for transformer-based time series foundation models (TSFMs) due to non-stationarity, heavy-tailed distributions, and high-frequency noise present in data. Low-rank adaptation (LoRA) has become a popular parameter-efficient method for adapting pre-trained TSFMs to downstream data domains. However, it still underperforms in financial data, as it preserves the network architecture and training objective of TSFMs rather than complementing the foundation model. To further enhance TSFMs, we propose a novel refinement module, RefineBridge, built upon a tractable Schrödinger Bridge (SB) generative framework. Given the forecasts of TSFM as generative prior and the observed ground truths as targets, RefineBridge learns context-conditioned stochastic transport maps to improve TSFM predictions, iteratively approaching the ground-truth target from even a low-quality prior. Simulations on multiple financial benchmarks demonstrate that RefineBridge consistently improves the performance of state-of-the-art TSFMs across different prediction horizons.
Coarse-to-Fine Open-Set Graph Node Classification with Large Language Models
Dec 21, 2025



Developing open-set classification methods capable of classifying in-distribution (ID) data while detecting out-of-distribution (OOD) samples is essential for deploying graph neural networks (GNNs) in open-world scenarios. Existing methods typically treat all OOD samples as a single class, despite real-world applications, especially high-stake settings such as fraud detection and medical diagnosis, demanding deeper insights into OOD samples, including their probable labels. This raises a critical question: can OOD detection be extended to OOD classification without true label information? To address this question, we propose a Coarse-to-Fine open-set Classification (CFC) framework that leverages large language models (LLMs) for graph datasets. CFC consists of three key components: a coarse classifier that uses LLM prompts for OOD detection and outlier label generation, a GNN-based fine classifier trained with OOD samples identified by the coarse classifier for enhanced OOD detection and ID classification, and refined OOD classification achieved through LLM prompts and post-processed OOD labels. Unlike methods that rely on synthetic or auxiliary OOD samples, CFC employs semantic OOD instances that are genuinely out-of-distribution based on their inherent meaning, improving interpretability and practical utility. Experimental results show that CFC improves OOD detection by ten percent over state-of-the-art methods on graph and text domains and achieves up to seventy percent accuracy in OOD classification on graph datasets.
Machine Intelligence on the Edge: Interpretable Cardiac Pattern Localisation Using Reinforcement Learning
Aug 29, 2025Matched filters are widely used to localise signal patterns due to their high efficiency and interpretability. However, their effectiveness deteriorates for low signal-to-noise ratio (SNR) signals, such as those recorded on edge devices, where prominent noise patterns can closely resemble the target within the limited length of the filter. One example is the ear-electrocardiogram (ear-ECG), where the cardiac signal is attenuated and heavily corrupted by artefacts. To address this, we propose the Sequential Matched Filter (SMF), a paradigm that replaces the conventional single matched filter with a sequence of filters designed by a Reinforcement Learning agent. By formulating filter design as a sequential decision-making process, SMF adaptively design signal-specific filter sequences that remain fully interpretable by revealing key patterns driving the decision-making. The proposed SMF framework has strong potential for reliable and interpretable clinical decision support, as demonstrated by its state-of-the-art R-peak detection and physiological state classification performance on two challenging real-world ECG datasets. The proposed formulation can also be extended to a broad range of applications that require accurate pattern localisation from noise-corrupted signals.
Domain-Aware Tensor Network Structure Search
May 29, 2025Tensor networks (TNs) provide efficient representations of high-dimensional data, yet identification of the optimal TN structures, the so called tensor network structure search (TN-SS) problem, remains a challenge. Current state-of-the-art (SOTA) algorithms are computationally expensive as they require extensive function evaluations, which is prohibitive for real-world applications. In addition, existing methods ignore valuable domain information inherent in real-world tensor data and lack transparency in their identified TN structures. To this end, we propose a novel TN-SS framework, termed the tnLLM, which incorporates domain information about the data and harnesses the reasoning capabilities of large language models (LLMs) to directly predict suitable TN structures. The proposed framework involves a domain-aware prompting pipeline which instructs the LLM to infer suitable TN structures based on the real-world relationships between tensor modes. In this way, our approach is capable of not only iteratively optimizing the objective function, but also generating domain-aware explanations for the identified structures. Experimental results demonstrate that tnLLM achieves comparable TN-SS objective function values with much fewer function evaluations compared to SOTA algorithms. Furthermore, we demonstrate that the LLM-enabled domain information can be used to find good initializations in the search space for sampling-based SOTA methods to accelerate their convergence while preserving theoretical performance guarantees.
A Systematic Review of EEG-based Machine Intelligence Algorithms for Depression Diagnosis, and Monitoring
Mar 25, 2025Depression disorder is a serious health condition that has affected the lives of millions of people around the world. Diagnosis of depression is a challenging practice that relies heavily on subjective studies and, in most cases, suffers from late findings. Electroencephalography (EEG) biomarkers have been suggested and investigated in recent years as a potential transformative objective practice. In this article, for the first time, a detailed systematic review of EEG-based depression diagnosis approaches is conducted using advanced machine learning techniques and statistical analyses. For this, 938 potentially relevant articles (since 1985) were initially detected and filtered into 139 relevant articles based on the review scheme 'preferred reporting items for systematic reviews and meta-analyses (PRISMA).' This article compares and discusses the selected articles and categorizes them according to the type of machine learning techniques and statistical analyses. Algorithms, preprocessing techniques, extracted features, and data acquisition systems are discussed and summarized. This review paper explains the existing challenges of the current algorithms and sheds light on the future direction of the field. This systematic review outlines the issues and challenges in machine intelligence for the diagnosis of EEG depression that can be addressed in future studies and possibly in future wearable technologies.
Learning to Predict Global Atrial Fibrillation Dynamics from Sparse Measurements
Feb 13, 2025



Catheter ablation of Atrial Fibrillation (AF) consists of a one-size-fits-all treatment with limited success in persistent AF. This may be due to our inability to map the dynamics of AF with the limited resolution and coverage provided by sequential contact mapping catheters, preventing effective patient phenotyping for personalised, targeted ablation. Here we introduce FibMap, a graph recurrent neural network model that reconstructs global AF dynamics from sparse measurements. Trained and validated on 51 non-contact whole atria recordings, FibMap reconstructs whole atria dynamics from 10% surface coverage, achieving a 210% lower mean absolute error and an order of magnitude higher performance in tracking phase singularities compared to baseline methods. Clinical utility of FibMap is demonstrated on real-world contact mapping recordings, achieving reconstruction fidelity comparable to non-contact mapping. FibMap's state-spaces and patient-specific parameters offer insights for electrophenotyping AF. Integrating FibMap into clinical practice could enable personalised AF care and improve outcomes.
Relational Conformal Prediction for Correlated Time Series
Feb 13, 2025



We address the problem of uncertainty quantification in time series forecasting by exploiting observations at correlated sequences. Relational deep learning methods leveraging graph representations are among the most effective tools for obtaining point estimates from spatiotemporal data and correlated time series. However, the problem of exploiting relational structures to estimate the uncertainty of such predictions has been largely overlooked in the same context. To this end, we propose a novel distribution-free approach based on the conformal prediction framework and quantile regression. Despite the recent applications of conformal prediction to sequential data, existing methods operate independently on each target time series and do not account for relationships among them when constructing the prediction interval. We fill this void by introducing a novel conformal prediction method based on graph deep learning operators. Our method, named Conformal Relational Prediction (CoRel), does not require the relational structure (graph) to be known as a prior and can be applied on top of any pre-trained time series predictor. Additionally, CoRel includes an adaptive component to handle non-exchangeable data and changes in the input time series. Our approach provides accurate coverage and archives state-of-the-art uncertainty quantification in relevant benchmarks.