 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Segment Anything Model 2 All You Need for Surgery Video Segmentation? A Systematic Evaluation
Dec 31, 2024



Surgery video segmentation is an important topic in the surgical AI field. It allows the AI model to understand the spatial information of a surgical scene. Meanwhile, due to the lack of annotated surgical data, surgery segmentation models suffer from limited performance. With the emergence of SAM2 model, a large foundation model for video segmentation trained on natural videos, zero-shot surgical video segmentation became more realistic but meanwhile remains to be explored. In this paper, we systematically evaluate the performance of SAM2 model in zero-shot surgery video segmentation task. We conducted experiments under different configurations, including different prompting strategies, robustness, etc. Moreover, we conducted an empirical evaluation over the performance, including 9 datasets with 17 different types of surgeries.
M2I2: Learning Efficient Multi-Agent Communication via Masked State Modeling and Intention Inference
Dec 31, 2024Communication is essential in coordinating the behaviors of multiple agents. However, existing methods primarily emphasize content, timing, and partners for information sharing, often neglecting the critical aspect of integrating shared information. This gap can significantly impact agents' ability to understand and respond to complex, uncertain interactions, thus affecting overall communication efficiency. To address this issue, we introduce M2I2, a novel framework designed to enhance the agents' capabilities to assimilate and utilize received information effectively. M2I2 equips agents with advanced capabilities for masked state modeling and joint-action prediction, enriching their perception of environmental uncertainties and facilitating the anticipation of teammates' intentions. This approach ensures that agents are furnished with both comprehensive and relevant information, bolstering more informed and synergistic behaviors. Moreover, we propose a Dimensional Rational Network, innovatively trained via a meta-learning paradigm, to identify the importance of dimensional pieces of information, evaluating their contributions to decision-making and auxiliary tasks. Then, we implement an importance-based heuristic for selective information masking and sharing. This strategy optimizes the efficiency of masked state modeling and the rationale behind information sharing. We evaluate M2I2 across diverse multi-agent tasks, the results demonstrate its superior performance, efficiency, and generalization capabilities, over existing state-of-the-art methods in various complex scenarios.
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Dec 30, 2024The remarkable performance of models like the OpenAI o1 can be attributed to their ability to emulate human-like long-time thinking during inference. These models employ extended chain-of-thought (CoT) processes, exploring multiple strategies to enhance problem-solving capabilities. However, a critical question remains: How to intelligently and efficiently scale computational resources during testing. This paper presents the first comprehensive study on the prevalent issue of overthinking in these models, where excessive computational resources are allocated for simple problems with minimal benefit. We introduce novel efficiency metrics from both outcome and process perspectives to evaluate the rational use of computational resources by o1-like models. Using a self-training paradigm, we propose strategies to mitigate overthinking, streamlining reasoning processes without compromising accuracy. Experimental results show that our approach successfully reduces computational overhead while preserving model performance across a range of testsets with varying difficulty levels, such as GSM8K, MATH500, GPQA, and AIME.
An Experimental Study of Passive UAV Tracking with Digital Arrays and Cellular Downlink Signals
Dec 30, 2024Given the prospects of the low-altitude economy (LAE) and the popularity of unmanned aerial vehicles (UAVs), there are increasing demands on monitoring flying objects at low altitude in wide urban areas. In this work, the widely deployed long-term evolution (LTE) base station (BS) is exploited to illuminate UAVs in bistatic trajectory tracking. Specifically, a passive sensing receiver with two digital antenna arrays is proposed and developed to capture both the line-of-sight (LoS) signal and the scattered signal off a target UAV. From their cross ambiguity function, the bistatic range, Doppler shift and angle-of-arrival (AoA) of the target UAV can be detected in a sequence of time slots. In order to address missed detections and false alarms of passive sensing, a multi-target tracking framework is adopted to track the trajectory of the target UAV. It is demonstrated by experiments that the proposed UAV tracking system can achieve a meter-level accuracy.
RobotDiffuse: Motion Planning for Redundant Manipulator based on Diffusion Model
Dec 27, 2024



Redundant manipulators, with their higher Degrees of Freedom (DOFs), offer enhanced kinematic performance and versatility, making them suitable for applications like manufacturing, surgical robotics, and human-robot collaboration. However, motion planning for these manipulators is challenging due to increased DOFs and complex, dynamic environments. While traditional motion planning algorithms struggle with high-dimensional spaces, deep learning-based methods often face instability and inefficiency in complex tasks. This paper introduces RobotDiffuse, a diffusion model-based approach for motion planning in redundant manipulators. By integrating physical constraints with a point cloud encoder and replacing the U-Net structure with an encoder-only transformer, RobotDiffuse improves the model's ability to capture temporal dependencies and generate smoother, more coherent motion plans. We validate the approach using a complex simulator, and release a new dataset with 35M robot poses and 0.14M obstacle avoidance scenarios. Experimental results demonstrate the effectiveness of RobotDiffuse and the promise of diffusion models for motion planning tasks. The code can be accessed at https://github.com/ACRoboT-buaa/RobotDiffuse.
Modality-Projection Universal Model for Comprehensive Full-Body Medical Imaging Segmentation
Dec 26, 2024The integration of deep learning in medical imaging has shown great promise for enhancing diagnostic, therapeutic, and research outcomes. However, applying universal models across multiple modalities remains challenging due to the inherent variability in data characteristics. This study aims to introduce and evaluate a Modality Projection Universal Model (MPUM). MPUM employs a novel modality-projection strategy, which allows the model to dynamically adjust its parameters to optimize performance across different imaging modalities. The MPUM demonstrated superior accuracy in identifying anatomical structures, enabling precise quantification for improved clinical decision-making. It also identifies metabolic associations within the brain-body axis, advancing research on brain-body physiological correlations. Furthermore, MPUM's unique controller-based convolution layer enables visualization of saliency maps across all network layers, significantly enhancing the model's interpretability.
Low Time Complexity Near-Field Channel and Position Estimations
Dec 18, 2024With the application of high-frequency communication and extremely large MIMO (XL-MIMO), the near-field effect has become increasingly apparent. The near-field channel estimation and position estimation problems both rely on the Angle of Arrival (AoA) and the Curvature of Arrival (CoA) estimation. However, in the near-field channel model, the coupling of AoA and CoA information poses a challenge to the estimation of the near-field channel. This paper proposes a Joint Autocorrelation and Cross-correlation (JAC) scheme to decouple AoA and CoA estimation. Based on the JAC scheme, we propose two specific near-field estimation algorithms, namely Inverse Sinc Function (JAC-ISF) and Gradient Descent (JAC-GD) algorithms. Finally, we analyzed the time complexity of the JAC scheme and the cramer-rao lower bound (CRLB) for near-field position estimation. The simulation experiment results show that the algorithm designed based on JAC scheme can solve the problem of coupled CoA and AoA information in near-field estimation, thereby improving the algorithm performance. The JAC-GD algorithm shows significant performance in channel estimation and position estimation at different SNRs, snapshot points, and communication distances compared to other algorithms. This indicates that the JAC-GD algorithm can achieve more accurate channel and position estimation results while saving time overhead.
UAlign: Leveraging Uncertainty Estimations for Factuality Alignment on Large Language Models
Dec 16, 2024



Despite demonstrating impressive capabilities, Large Language Models (LLMs) still often struggle to accurately express the factual knowledge they possess, especially in cases where the LLMs' knowledge boundaries are ambiguous. To improve LLMs' factual expressions, we propose the UAlign framework, which leverages Uncertainty estimations to represent knowledge boundaries, and then explicitly incorporates these representations as input features into prompts for LLMs to Align with factual knowledge. First, we prepare the dataset on knowledge question-answering (QA) samples by calculating two uncertainty estimations, including confidence score and semantic entropy, to represent the knowledge boundaries for LLMs. Subsequently, using the prepared dataset, we train a reward model that incorporates uncertainty estimations and then employ the Proximal Policy Optimization (PPO) algorithm for factuality alignment on LLMs. Experimental results indicate that, by integrating uncertainty representations in LLM alignment, the proposed UAlign can significantly enhance the LLMs' capacities to confidently answer known questions and refuse unknown questions on both in-domain and out-of-domain tasks, showing reliability improvements and good generalizability over various prompt- and training-based baselines.
StarWhisper Telescope: Agent-Based Observation Assistant System to Approach AI Astrophysicist
Dec 09, 2024



With the rapid advancements in Large Language Models (LLMs), LLM-based agents have introduced convenient and user-friendly methods for leveraging tools across various domains. In the field of astronomical observation, the construction of new telescopes has significantly increased astronomers' workload. Deploying LLM-powered agents can effectively alleviate this burden and reduce the costs associated with training personnel. Within the Nearby Galaxy Supernovae Survey (NGSS) project, which encompasses eight telescopes across three observation sites, aiming to find the transients from the galaxies in 50 mpc, we have developed the \textbf{StarWhisper Telescope System} to manage the entire observation process. This system automates tasks such as generating observation lists, conducting observations, analyzing data, and providing feedback to the observer. Observation lists are customized for different sites and strategies to ensure comprehensive coverage of celestial objects. After manual verification, these lists are uploaded to the telescopes via the agents in the system, which initiates observations upon neutral language. The observed images are analyzed in real-time, and the transients are promptly communicated to the observer. The agent modifies them into a real-time follow-up observation proposal and send to the Xinglong observatory group chat, then add them to the next-day observation lists. Additionally, the integration of AI agents within the system provides online accessibility, saving astronomers' time and encouraging greater participation from amateur astronomers in the NGSS project.
Wavelet Diffusion Neural Operator
Dec 06, 2024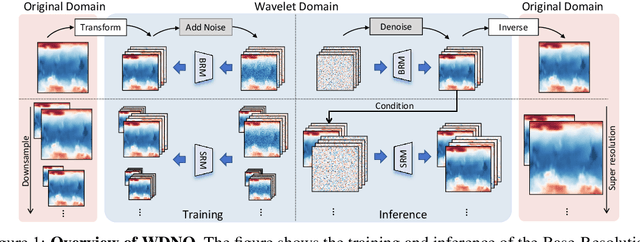
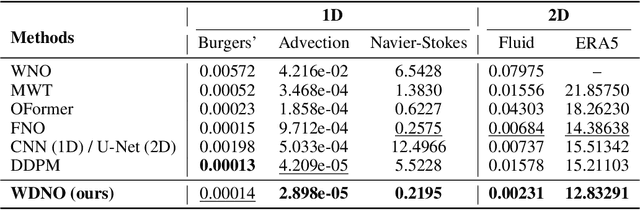
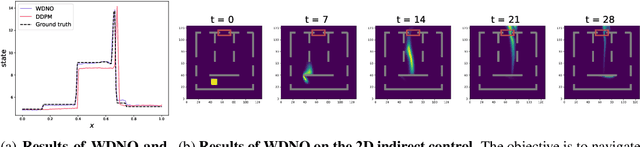
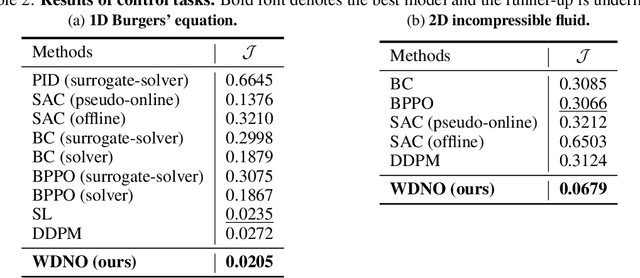
Simulating and controlling physical systems described by partial differential equations (PDEs) are crucial tasks across science and engineering. Recently, diffusion generative models have emerged as a competitive class of methods for these tasks due to their ability to capture long-term dependencies and model high-dimensional states. However, diffusion models typically struggle with handling system states with abrupt changes and generalizing to higher resolutions. In this work, we propose Wavelet Diffusion Neural Operator (WDNO), a novel PDE simulation and control framework that enhances the handling of these complexities. WDNO comprises two key innovations. Firstly, WDNO performs diffusion-based generative modeling in the wavelet domain for the entire trajectory to handle abrupt changes and long-term dependencies effectively. Secondly, to address the issue of poor generalization across different resolutions, which is one of the fundamental tasks in modeling physical systems, we introduce multi-resolution training. We validate WDNO on five physical systems, including 1D advection equation, three challenging physical systems with abrupt changes (1D Burgers' equation, 1D compressible Navier-Stokes equation and 2D incompressible fluid), and a real-world dataset ERA5, which demonstrates superior performance on both simulation and control tasks over state-of-the-art methods, with significant improvements in long-term and detail prediction accuracy. Remarkably, in the challenging context of the 2D high-dimensional and indirect control task aimed at reducing smoke leakage, WDNO reduces the leakage by 33.2% compared to the second-best baseline.