 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARM: Advantage Reward Modeling for Long-Horizon Manipulation
Apr 03, 2026Long-horizon robotic manipulation remains challenging for reinforcement learning (RL) because sparse rewards provide limited guidance for credit assignment. Practical policy improvement thus relies on richer intermediate supervision, such as dense progress rewards, which are costly to obtain and ill-suited to non-monotonic behaviors such as backtracking and recovery. To address this, we propose Advantage Reward Modeling (ARM), a framework that shifts from hard-to-quantify absolute progress to estimating relative advantage. We introduce a cost-effective tri-state labeling strategy -- Progressive, Regressive, and Stagnant -- that reduces human cognitive overhead while ensuring high cross-annotator consistency. By training on these intuitive signals, ARM enables automated progress annotation for both complete demonstrations and fragmented DAgger-style data. Integrating ARM into an offline RL pipeline allows for adaptive action-reward reweighting, effectively filtering suboptimal samples. Our approach achieves a 99.4% success rate on a challenging long-horizon towel-folding task, demonstrating improved stability and data efficiency over current VLA baselines with near-zero human intervention during policy training.
OpenPros: A Large-Scale Dataset for Limited View Prostate Ultrasound Computed Tomography
May 18, 2025Prostate cancer is one of the most common and lethal cancers among men, making its early detection critically important. Although ultrasound imaging offers greater accessibility and cost-effectiveness compared to MRI, traditional transrectal ultrasound methods suffer from low sensitivity, especially in detecting anteriorly located tumors. Ultrasound computed tomography provides quantitative tissue characterization, but its clinical implementation faces significant challenges, particularly under anatomically constrained limited-angle acquisition conditions specific to prostate imaging. To address these unmet needs, we introduce OpenPros, the first large-scale benchmark dataset explicitly developed for limited-view prostate USCT. Our dataset includes over 280,000 paired samples of realistic 2D speed-of-sound (SOS) phantoms and corresponding ultrasound full-waveform data, generated from anatomically accurate 3D digital prostate models derived from real clinical MRI/CT scans and ex vivo ultrasound measurements, annotated by medical experts. Simulations are conducted under clinically realistic configurations using advanced finite-difference time-domain and Runge-Kutta acoustic wave solvers, both provided as open-source components. Through comprehensive baseline experiments, we demonstrate that state-of-the-art deep learning methods surpass traditional physics-based approaches in both inference efficiency and reconstruction accuracy. Nevertheless, current deep learning models still fall short of delivering clinically acceptable high-resolution images with sufficient accuracy. By publicly releasing OpenPros, we aim to encourage the development of advanced machine learning algorithms capable of bridging this performance gap and producing clinically usable, high-resolution, and highly accurate prostate ultrasound images. The dataset is publicly accessible at https://open-pros.github.io/.
StarWhisper Telescope: Agent-Based Observation Assistant System to Approach AI Astrophysicist
Dec 09, 2024



With the rapid advancements in Large Language Models (LLMs), LLM-based agents have introduced convenient and user-friendly methods for leveraging tools across various domains. In the field of astronomical observation, the construction of new telescopes has significantly increased astronomers' workload. Deploying LLM-powered agents can effectively alleviate this burden and reduce the costs associated with training personnel. Within the Nearby Galaxy Supernovae Survey (NGSS) project, which encompasses eight telescopes across three observation sites, aiming to find the transients from the galaxies in 50 mpc, we have developed the \textbf{StarWhisper Telescope System} to manage the entire observation process. This system automates tasks such as generating observation lists, conducting observations, analyzing data, and providing feedback to the observer. Observation lists are customized for different sites and strategies to ensure comprehensive coverage of celestial objects. After manual verification, these lists are uploaded to the telescopes via the agents in the system, which initiates observations upon neutral language. The observed images are analyzed in real-time, and the transients are promptly communicated to the observer. The agent modifies them into a real-time follow-up observation proposal and send to the Xinglong observatory group chat, then add them to the next-day observation lists. Additionally, the integration of AI agents within the system provides online accessibility, saving astronomers' time and encouraging greater participation from amateur astronomers in the NGSS project.
Once Detected, Never Lost: Surpassing Human Performance in Offline LiDAR based 3D Object Detection
Apr 24, 2023



This paper aims for high-performance offline LiDAR-based 3D object detection. We first observe that experienced human annotators annotate objects from a track-centric perspective. They first label the objects with clear shapes in a track, and then leverage the temporal coherence to infer the annotations of obscure objects. Drawing inspiration from this, we propose a high-performance offline detector in a track-centric perspective instead of the conventional object-centric perspective. Our method features a bidirectional tracking module and a track-centric learning module. Such a design allows our detector to infer and refine a complete track once the object is detected at a certain moment. We refer to this characteristic as "onCe detecTed, neveR Lost" and name the proposed system CTRL. Extensive experiments demonstrate the remarkable performance of our method, surpassing the human-level annotating accuracy and the previous state-of-the-art methods in the highly competitive Waymo Open Dataset without model ensemble. The code will be made publicly available at https://github.com/tusen-ai/SST.
Controllable Person Image Synthesis with Attribute-Decomposed GAN
Apr 18, 2020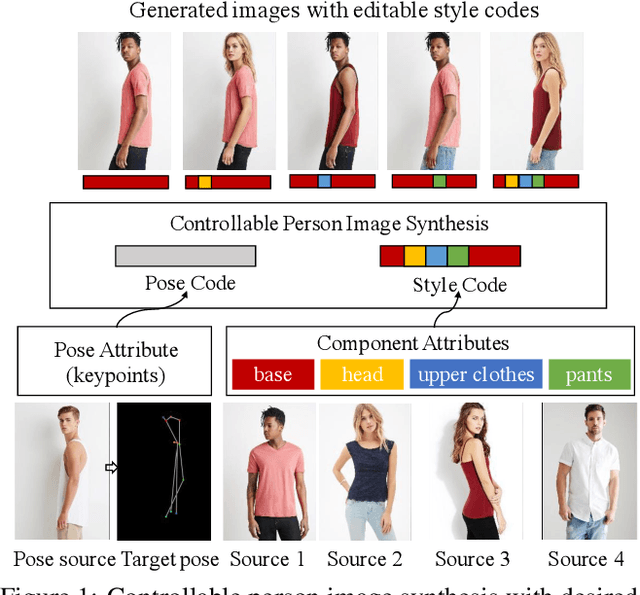
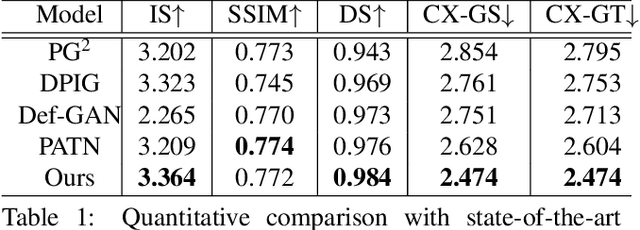
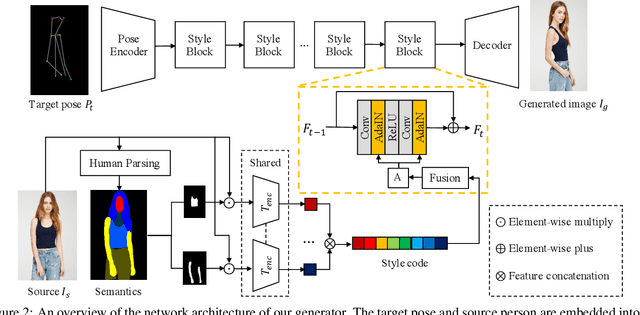
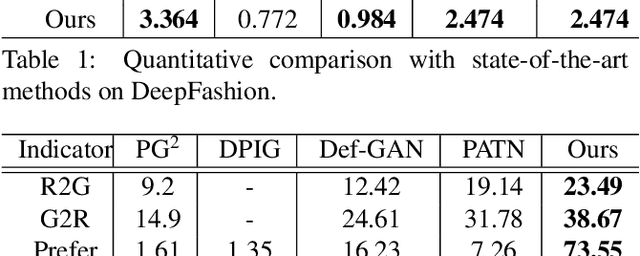
This paper introduces the Attribute-Decomposed GAN, a novel generative model for controllable person image synthesis, which can produce realistic person images with desired human attributes (e.g., pose, head, upper clothes and pants) provided in various source inputs. The core idea of the proposed model is to embed human attributes into the latent space as independent codes and thus achieve flexible and continuous control of attributes via mixing and interpolation operations in explicit style representations. Specifically, a new architecture consisting of two encoding pathways with style block connections is proposed to decompose the original hard mapping into multiple more accessible subtasks. In source pathway, we further extract component layouts with an off-the-shelf human parser and feed them into a shared global texture encoder for decomposed latent codes. This strategy allows for the synthesis of more realistic output images and automatic separation of un-annotated attributes. Experimental results demonstrate the proposed method's superiority over the state of the art in pose transfer and its effectiveness in the brand-new task of component attribute transfer.