 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Greedy Decoding for Visual Question Answering: A Calibration Perspective
Apr 25, 2026Stochastic sampling strategies are widely adopted in large language models (LLMs) to balance output coherence and diversity. These heuristics are often inherited in Multimodal LLMs (MLLMs) without task-specific justification. However, we contend that stochastic decoding can be suboptimal for Visual Question Answering (VQA). VQA is a closed-ended task with head-heavy answer distributions where uncertainty is usually epistemic, arising from missing or ambiguous visual evidence rather than plausible continuations. In this work, we provide a theoretical formalization of the relationship between model calibration and predictive accuracy, and derive the sufficient conditions for greedy decoding optimality. Extensive experiments provide empirical evidence for the superiority of greedy decoding over stochastic sampling across multiple benchmarks. Furthermore, we propose Greedy Decoding for Reasoning Models, which outperforms both stochastic sampling and standard greedy decoding in multimodal reasoning scenarios. Overall, our results caution against naively inheriting LLMs decoding heuristics in MLLMs and demonstrate that greedy decoding can be an efficient yet strong default for VQA.
MEDSYN: Benchmarking Multi-EviDence SYNthesis in Complex Clinical Cases for Multimodal Large Language Models
Feb 25, 2026Multimodal large language models (MLLMs) have shown great potential in medical applications, yet existing benchmarks inadequately capture real-world clinical complexity. We introduce MEDSYN, a multilingual, multimodal benchmark of highly complex clinical cases with up to 7 distinct visual clinical evidence (CE) types per case. Mirroring clinical workflow, we evaluate 18 MLLMs on differential diagnosis (DDx) generation and final diagnosis (FDx) selection. While top models often match or even outperform human experts on DDx generation, all MLLMs exhibit a much larger DDx--FDx performance gap compared to expert clinicians, indicating a failure mode in synthesis of heterogeneous CE types. Ablations attribute this failure to (i) overreliance on less discriminative textual CE ($\it{e.g.}$, medical history) and (ii) a cross-modal CE utilization gap. We introduce Evidence Sensitivity to quantify the latter and show that a smaller gap correlates with higher diagnostic accuracy. Finally, we demonstrate how it can be used to guide interventions to improve model performance. We will open-source our benchmark and code.
Mask What Matters: Mitigating Object Hallucinations in Multimodal Large Language Models with Object-Aligned Visual Contrastive Decoding
Feb 12, 2026We study object hallucination in Multimodal Large Language Models (MLLMs) and improve visual contrastive decoding (VCD) by constructing an object-aligned auxiliary view. We leverage object-centric attention in self-supervised Vision Transformers. In particular, we remove the most salient visual evidence to construct an auxiliary view that disrupts unsupported tokens and produces a stronger contrast signal. Our method is prompt-agnostic, model-agnostic, and can be seamlessly plugged into the existing VCD pipeline with little computation overhead, i.e., a single cacheable forward pass. Empirically, our method demonstrates consistent gains on two popular object hallucination benchmarks across two MLLMs.
WaveFormer: Frequency-Time Decoupled Vision Modeling with Wave Equation
Jan 13, 2026Vision modeling has advanced rapidly with Transformers, whose attention mechanisms capture visual dependencies but lack a principled account of how semantic information propagates spatially. We revisit this problem from a wave-based perspective: feature maps are treated as spatial signals whose evolution over an internal propagation time (aligned with network depth) is governed by an underdamped wave equation. In this formulation, spatial frequency-from low-frequency global layout to high-frequency edges and textures-is modeled explicitly, and its interaction with propagation time is controlled rather than implicitly fixed. We derive a closed-form, frequency-time decoupled solution and implement it as the Wave Propagation Operator (WPO), a lightweight module that models global interactions in O(N log N) time-far lower than attention. Building on WPO, we propose a family of WaveFormer models as drop-in replacements for standard ViTs and CNNs, achieving competitive accuracy across image classification, object detection, and semantic segmentation, while delivering up to 1.6x higher throughput and 30% fewer FLOPs than attention-based alternatives. Furthermore, our results demonstrate that wave propagation introduces a complementary modeling bias to heat-based methods, effectively capturing both global coherence and high-frequency details essential for rich visual semantics. Codes are available at: https://github.com/ZishanShu/WaveFormer.
AMUSE: Audio-Visual Benchmark and Alignment Framework for Agentic Multi-Speaker Understanding
Dec 18, 2025

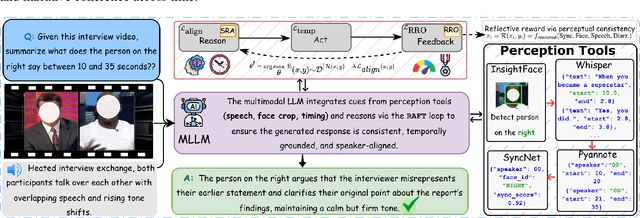
Recent multimodal large language models (MLLMs) such as GPT-4o and Qwen3-Omni show strong perception but struggle in multi-speaker, dialogue-centric settings that demand agentic reasoning tracking who speaks, maintaining roles, and grounding events across time. These scenarios are central to multimodal audio-video understanding, where models must jointly reason over audio and visual streams in applications such as conversational video assistants and meeting analytics. We introduce AMUSE, a benchmark designed around tasks that are inherently agentic, requiring models to decompose complex audio-visual interactions into planning, grounding, and reflection steps. It evaluates MLLMs across three modes zero-shot, guided, and agentic and six task families, including spatio-temporal speaker grounding and multimodal dialogue summarization. Across all modes, current models exhibit weak multi-speaker reasoning and inconsistent behavior under both non-agentic and agentic evaluation. Motivated by the inherently agentic nature of these tasks and recent advances in LLM agents, we propose RAFT, a data-efficient agentic alignment framework that integrates reward optimization with intrinsic multimodal self-evaluation as reward and selective parameter adaptation for data and parameter efficient updates. Using RAFT, we achieve up to 39.52\% relative improvement in accuracy on our benchmark. Together, AMUSE and RAFT provide a practical platform for examining agentic reasoning in multimodal models and improving their capabilities.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
Caesar: A Low-deviation Compression Approach for Efficient Federated Learning
Dec 28, 2024Compression is an efficient way to relieve the tremendous communication overhead of federated learning (FL) systems. However, for the existing works, the information loss under compression will lead to unexpected model/gradient deviation for the FL training, significantly degrading the training performance, especially under the challenges of data heterogeneity and model obsolescence. To strike a delicate trade-off between model accuracy and traffic cost, we propose Caesar, a novel FL framework with a low-deviation compression approach. For the global model download, we design a greedy method to optimize the compression ratio for each device based on the staleness of the local model, ensuring a precise initial model for local training. Regarding the local gradient upload, we utilize the device's local data properties (\ie, sample volume and label distribution) to quantify its local gradient's importance, which then guides the determination of the gradient compression ratio. Besides, with the fine-grained batch size optimization, Caesar can significantly diminish the devices' idle waiting time under the synchronized barrier. We have implemented Caesar on two physical platforms with 40 smartphones and 80 NVIDIA Jetson devices. Extensive results show that Caesar can reduce the traffic costs by about 25.54%$\thicksim$37.88% compared to the compression-based baselines with the same target accuracy, while incurring only a 0.68% degradation in final test accuracy relative to the full-precision communication.
RobotDiffuse: Motion Planning for Redundant Manipulator based on Diffusion Model
Dec 27, 2024



Redundant manipulators, with their higher Degrees of Freedom (DOFs), offer enhanced kinematic performance and versatility, making them suitable for applications like manufacturing, surgical robotics, and human-robot collaboration. However, motion planning for these manipulators is challenging due to increased DOFs and complex, dynamic environments. While traditional motion planning algorithms struggle with high-dimensional spaces, deep learning-based methods often face instability and inefficiency in complex tasks. This paper introduces RobotDiffuse, a diffusion model-based approach for motion planning in redundant manipulators. By integrating physical constraints with a point cloud encoder and replacing the U-Net structure with an encoder-only transformer, RobotDiffuse improves the model's ability to capture temporal dependencies and generate smoother, more coherent motion plans. We validate the approach using a complex simulator, and release a new dataset with 35M robot poses and 0.14M obstacle avoidance scenarios. Experimental results demonstrate the effectiveness of RobotDiffuse and the promise of diffusion models for motion planning tasks. The code can be accessed at https://github.com/ACRoboT-buaa/RobotDiffuse.
XRAG: eXamining the Core -- Benchmarking Foundational Components in Advanced Retrieval-Augmented Generation
Dec 24, 2024Retrieval-augmented generation (RAG) synergizes the retrieval of pertinent data with the generative capabilities of Large Language Models (LLMs), ensuring that the generated output is not only contextually relevant but also accurate and current. We introduce XRAG, an open-source, modular codebase that facilitates exhaustive evaluation of the performance of foundational components of advanced RAG modules. These components are systematically categorized into four core phases: pre-retrieval, retrieval, post-retrieval, and generation. We systematically analyse them across reconfigured datasets, providing a comprehensive benchmark for their effectiveness. As the complexity of RAG systems continues to escalate, we underscore the critical need to identify potential failure points in RAG systems. We formulate a suite of experimental methodologies and diagnostic testing protocols to dissect the failure points inherent in RAG engineering. Subsequently, we proffer bespoke solutions aimed at bolstering the overall performance of these modules. Our work thoroughly evaluates the performance of advanced core components in RAG systems, providing insights into optimizations for prevalent failure points.
Improving the Consistency in Cross-Lingual Cross-Modal Retrieval with 1-to-K Contrastive Learning
Jun 26, 2024Cross-lingual Cross-modal Retrieval (CCR) is an essential task in web search, which aims to break the barriers between modality and language simultaneously and achieves image-text retrieval in the multi-lingual scenario with a single model. In recent years, excellent progress has been made based on cross-lingual cross-modal pre-training; particularly, the methods based on contrastive learning on large-scale data have significantly improved retrieval tasks. However, these methods directly follow the existing pre-training methods in the cross-lingual or cross-modal domain, leading to two problems of inconsistency in CCR: The methods with cross-lingual style suffer from the intra-modal error propagation, resulting in inconsistent recall performance across languages in the whole dataset. The methods with cross-modal style suffer from the inter-modal optimization direction bias, resulting in inconsistent rank across languages within each instance, which cannot be reflected by Recall@K. To solve these problems, we propose a simple but effective 1-to-K contrastive learning method, which treats each language equally and eliminates error propagation and optimization bias. In addition, we propose a new evaluation metric, Mean Rank Variance (MRV), to reflect the rank inconsistency across languages within each instance. Extensive experiments on four CCR datasets show that our method improves both recall rates and MRV with smaller-scale pre-trained data, achieving the new state-of-art.