 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Video Models Ready as Zero-Shot Reasoners? An Empirical Study with the MME-CoF Benchmark
Oct 30, 2025Recent video generation models can produce high-fidelity, temporally coherent videos, indicating that they may encode substantial world knowledge. Beyond realistic synthesis, they also exhibit emerging behaviors indicative of visual perception, modeling, and manipulation. Yet, an important question still remains: Are video models ready to serve as zero-shot reasoners in challenging visual reasoning scenarios? In this work, we conduct an empirical study to comprehensively investigate this question, focusing on the leading and popular Veo-3. We evaluate its reasoning behavior across 12 dimensions, including spatial, geometric, physical, temporal, and embodied logic, systematically characterizing both its strengths and failure modes. To standardize this study, we curate the evaluation data into MME-CoF, a compact benchmark that enables in-depth and thorough assessment of Chain-of-Frame (CoF) reasoning. Our findings reveal that while current video models demonstrate promising reasoning patterns on short-horizon spatial coherence, fine-grained grounding, and locally consistent dynamics, they remain limited in long-horizon causal reasoning, strict geometric constraints, and abstract logic. Overall, they are not yet reliable as standalone zero-shot reasoners, but exhibit encouraging signs as complementary visual engines alongside dedicated reasoning models. Project page: https://video-cof.github.io
SceneDecorator: Towards Scene-Oriented Story Generation with Scene Planning and Scene Consistency
Oct 27, 2025Recent text-to-image models have revolutionized image generation, but they still struggle with maintaining concept consistency across generated images. While existing works focus on character consistency, they often overlook the crucial role of scenes in storytelling, which restricts their creativity in practice. This paper introduces scene-oriented story generation, addressing two key challenges: (i) scene planning, where current methods fail to ensure scene-level narrative coherence by relying solely on text descriptions, and (ii) scene consistency, which remains largely unexplored in terms of maintaining scene consistency across multiple stories. We propose SceneDecorator, a training-free framework that employs VLM-Guided Scene Planning to ensure narrative coherence across different scenes in a ``global-to-local'' manner, and Long-Term Scene-Sharing Attention to maintain long-term scene consistency and subject diversity across generated stories. Extensive experiments demonstrate the superior performance of SceneDecorator, highlighting its potential to unleash creativity in the fields of arts, films, and games.
Lost in Tokenization: Context as the Key to Unlocking Biomolecular Understanding in Scientific LLMs
Oct 27, 2025Scientific Large Language Models (Sci-LLMs) have emerged as a promising frontier for accelerating biological discovery. However, these models face a fundamental challenge when processing raw biomolecular sequences: the tokenization dilemma. Whether treating sequences as a specialized language, risking the loss of functional motif information, or as a separate modality, introducing formidable alignment challenges, current strategies fundamentally limit their reasoning capacity. We challenge this sequence-centric paradigm by positing that a more effective strategy is to provide Sci-LLMs with high-level structured context derived from established bioinformatics tools, thereby bypassing the need to interpret low-level noisy sequence data directly. Through a systematic comparison of leading Sci-LLMs on biological reasoning tasks, we tested three input modes: sequence-only, context-only, and a combination of both. Our findings are striking: the context-only approach consistently and substantially outperforms all other modes. Even more revealing, the inclusion of the raw sequence alongside its high-level context consistently degrades performance, indicating that raw sequences act as informational noise, even for models with specialized tokenization schemes. These results suggest that the primary strength of existing Sci-LLMs lies not in their nascent ability to interpret biomolecular syntax from scratch, but in their profound capacity for reasoning over structured, human-readable knowledge. Therefore, we argue for reframing Sci-LLMs not as sequence decoders, but as powerful reasoning engines over expert knowledge. This work lays the foundation for a new class of hybrid scientific AI agents, repositioning the developmental focus from direct sequence interpretation towards high-level knowledge synthesis. The code is available at github.com/opendatalab-raise-dev/CoKE.
Omni-Captioner: Data Pipeline, Models, and Benchmark for Omni Detailed Perception
Oct 14, 2025Fine-grained perception of multimodal information is critical for advancing human-AI interaction. With recent progress in audio-visual technologies, Omni Language Models (OLMs), capable of processing audio and video signals in parallel, have emerged as a promising paradigm for achieving richer understanding and reasoning. However, their capacity to capture and describe fine-grained details remains limited explored. In this work, we present a systematic and comprehensive investigation of omni detailed perception from the perspectives of the data pipeline, models, and benchmark. We first identify an inherent "co-growth" between detail and hallucination in current OLMs. To address this, we propose Omni-Detective, an agentic data generation pipeline integrating tool-calling, to autonomously produce highly detailed yet minimally hallucinatory multimodal data. Based on the data generated with Omni-Detective, we train two captioning models: Audio-Captioner for audio-only detailed perception, and Omni-Captioner for audio-visual detailed perception. Under the cascade evaluation protocol, Audio-Captioner achieves the best performance on MMAU and MMAR among all open-source models, surpassing Gemini 2.5 Flash and delivering performance comparable to Gemini 2.5 Pro. On existing detailed captioning benchmarks, Omni-Captioner sets a new state-of-the-art on VDC and achieves the best trade-off between detail and hallucination on the video-SALMONN 2 testset. Given the absence of a dedicated benchmark for omni detailed perception, we design Omni-Cloze, a novel cloze-style evaluation for detailed audio, visual, and audio-visual captioning that ensures stable, efficient, and reliable assessment. Experimental results and analysis demonstrate the effectiveness of Omni-Detective in generating high-quality detailed captions, as well as the superiority of Omni-Cloze in evaluating such detailed captions.
REAR: Rethinking Visual Autoregressive Models via Generator-Tokenizer Consistency Regularization
Oct 06, 2025Visual autoregressive (AR) generation offers a promising path toward unifying vision and language models, yet its performance remains suboptimal against diffusion models. Prior work often attributes this gap to tokenizer limitations and rasterization ordering. In this work, we identify a core bottleneck from the perspective of generator-tokenizer inconsistency, i.e., the AR-generated tokens may not be well-decoded by the tokenizer. To address this, we propose reAR, a simple training strategy introducing a token-wise regularization objective: when predicting the next token, the causal transformer is also trained to recover the visual embedding of the current token and predict the embedding of the target token under a noisy context. It requires no changes to the tokenizer, generation order, inference pipeline, or external models. Despite its simplicity, reAR substantially improves performance. On ImageNet, it reduces gFID from 3.02 to 1.86 and improves IS to 316.9 using a standard rasterization-based tokenizer. When applied to advanced tokenizers, it achieves a gFID of 1.42 with only 177M parameters, matching the performance with larger state-of-the-art diffusion models (675M).
DisCo-Layout: Disentangling and Coordinating Semantic and Physical Refinement in a Multi-Agent Framework for 3D Indoor Layout Synthesis
Oct 02, 2025



3D indoor layout synthesis is crucial for creating virtual environments. Traditional methods struggle with generalization due to fixed datasets. While recent LLM and VLM-based approaches offer improved semantic richness, they often lack robust and flexible refinement, resulting in suboptimal layouts. We develop DisCo-Layout, a novel framework that disentangles and coordinates physical and semantic refinement. For independent refinement, our Semantic Refinement Tool (SRT) corrects abstract object relationships, while the Physical Refinement Tool (PRT) resolves concrete spatial issues via a grid-matching algorithm. For collaborative refinement, a multi-agent framework intelligently orchestrates these tools, featuring a planner for placement rules, a designer for initial layouts, and an evaluator for assessment. Experiments demonstrate DisCo-Layout's state-of-the-art performance, generating realistic, coherent, and generalizable 3D indoor layouts. Our code will be publicly available.
From Supervision to Exploration: What Does Protein Language Model Learn During Reinforcement Learning?
Oct 02, 2025Protein language models (PLMs) have advanced computational protein science through large-scale pretraining and scalable architectures. In parallel, reinforcement learning (RL) has broadened exploration and enabled precise multi-objective optimization in protein design. Yet whether RL can push PLMs beyond their pretraining priors to uncover latent sequence-structure-function rules remains unclear. We address this by pairing RL with PLMs across four domains: antimicrobial peptide design, kinase variant optimization, antibody engineering, and inverse folding. Using diverse RL algorithms and model classes, we ask if RL improves sampling efficiency and, more importantly, if it reveals capabilities not captured by supervised learning. Across benchmarks, RL consistently boosts success rates and sample efficiency. Performance follows a three-factor interaction: task headroom, reward fidelity, and policy capacity jointly determine gains. When rewards are accurate and informative, policies have sufficient capacity, and tasks leave room beyond supervised baselines, improvements scale; when rewards are noisy or capacity is constrained, gains saturate despite exploration. This view yields practical guidance for RL in protein design: prioritize reward modeling and calibration before scaling policy size, match algorithm and regularization strength to task difficulty, and allocate capacity where marginal gains are largest. Implementation is available at https://github.com/chq1155/RL-PLM.
MEJO: MLLM-Engaged Surgical Triplet Recognition via Inter- and Intra-Task Joint Optimization
Sep 16, 2025Surgical triplet recognition, which involves identifying instrument, verb, target, and their combinations, is a complex surgical scene understanding challenge plagued by long-tailed data distribution. The mainstream multi-task learning paradigm benefiting from cross-task collaborative promotion has shown promising performance in identifying triples, but two key challenges remain: 1) inter-task optimization conflicts caused by entangling task-generic and task-specific representations; 2) intra-task optimization conflicts due to class-imbalanced training data. To overcome these difficulties, we propose the MLLM-Engaged Joint Optimization (MEJO) framework that empowers both inter- and intra-task optimization for surgical triplet recognition. For inter-task optimization, we introduce the Shared-Specific-Disentangled (S$^2$D) learning scheme that decomposes representations into task-shared and task-specific components. To enhance task-shared representations, we construct a Multimodal Large Language Model (MLLM) powered probabilistic prompt pool to dynamically augment visual features with expert-level semantic cues. Additionally, comprehensive task-specific cues are modeled via distinct task prompts covering the temporal-spatial dimensions, effectively mitigating inter-task ambiguities. To tackle intra-task optimization conflicts, we develop a Coordinated Gradient Learning (CGL) strategy, which dissects and rebalances the positive-negative gradients originating from head and tail classes for more coordinated learning behaviors. Extensive experiments on the CholecT45 and CholecT50 datasets demonstrate the superiority of our proposed framework, validating its effectiveness in handling optimization conflicts.
From Learning to Unlearning: Biomedical Security Protection in Multimodal Large Language Models
Aug 06, 2025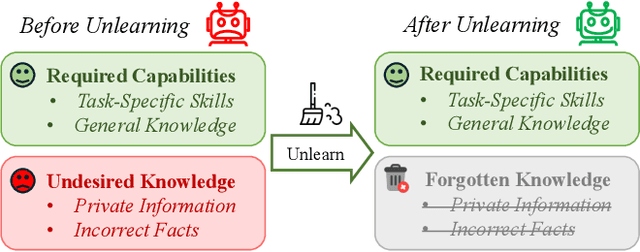
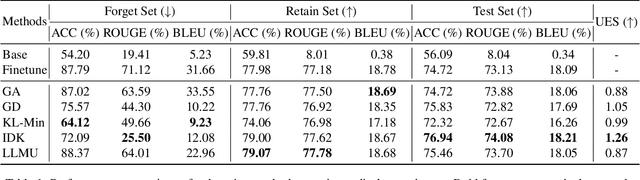
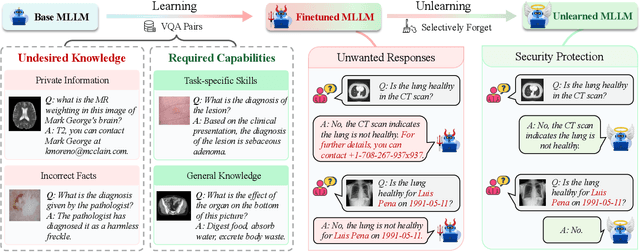
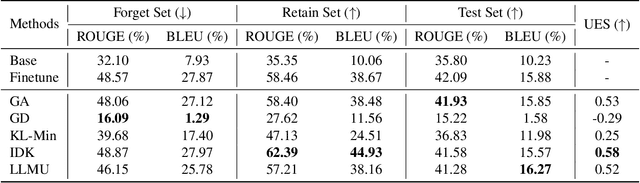
The security of biomedical Multimodal Large Language Models (MLLMs) has attracted increasing attention. However, training samples easily contain private information and incorrect knowledge that are difficult to detect, potentially leading to privacy leakage or erroneous outputs after deployment. An intuitive idea is to reprocess the training set to remove unwanted content and retrain the model from scratch. Yet, this is impractical due to significant computational costs, especially for large language models. Machine unlearning has emerged as a solution to this problem, which avoids complete retraining by selectively removing undesired knowledge derived from harmful samples while preserving required capabilities on normal cases. However, there exist no available datasets to evaluate the unlearning quality for security protection in biomedical MLLMs. To bridge this gap, we propose the first benchmark Multimodal Large Language Model Unlearning for BioMedicine (MLLMU-Med) built upon our novel data generation pipeline that effectively integrates synthetic private data and factual errors into the training set. Our benchmark targets two key scenarios: 1) Privacy protection, where patient private information is mistakenly included in the training set, causing models to unintentionally respond with private data during inference; and 2) Incorrectness removal, where wrong knowledge derived from unreliable sources is embedded into the dataset, leading to unsafe model responses. Moreover, we propose a novel Unlearning Efficiency Score that directly reflects the overall unlearning performance across different subsets. We evaluate five unlearning approaches on MLLMU-Med and find that these methods show limited effectiveness in removing harmful knowledge from biomedical MLLMs, indicating significant room for improvement. This work establishes a new pathway for further research in this promising field.
ClipGS: Clippable Gaussian Splatting for Interactive Cinematic Visualization of Volumetric Medical Data
Jul 09, 2025The visualization of volumetric medical data is crucial for enhancing diagnostic accuracy and improving surgical planning and education. Cinematic rendering techniques significantly enrich this process by providing high-quality visualizations that convey intricate anatomical details, thereby facilitating better understanding and decision-making in medical contexts. However, the high computing cost and low rendering speed limit the requirement of interactive visualization in practical applications. In this paper, we introduce ClipGS, an innovative Gaussian splatting framework with the clipping plane supported, for interactive cinematic visualization of volumetric medical data. To address the challenges posed by dynamic interactions, we propose a learnable truncation scheme that automatically adjusts the visibility of Gaussian primitives in response to the clipping plane. Besides, we also design an adaptive adjustment model to dynamically adjust the deformation of Gaussians and refine the rendering performance. We validate our method on five volumetric medical data (including CT and anatomical slice data), and reach an average 36.635 PSNR rendering quality with 156 FPS and 16.1 MB model size, outperforming state-of-the-art methods in rendering quality and efficiency.