 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTFDNet: Fusion-Decoupling for Robust RGB-T Segmentation
Mar 10, 2026RGB-Thermal (RGB-T) semantic segmentation is essential for robotic systems operating in low-light or dark environments. However, traditional approaches often overemphasize modality balance, resulting in limited robustness and severe performance degradation when sensor signals are partially missing. Recent advances such as cross-modal knowledge distillation and modality-adaptive fine-tuning attempt to enhance cross-modal interaction, but they typically decouple modality fusion and modality adaptation, requiring multi-stage training with frozen models or teacher-student frameworks. We present RTFDNet, a three-branch encoder-decoder that unifies fusion and decoupling for robust RGB-T segmentation. Synergistic Feature Fusion (SFF) performs channel-wise gated exchange and lightweight spatial attention to inject complementary cues. Cross-Modal Decouple Regularization (CMDR) isolates modality-specific components from the fused representation and supervises unimodal decoders via stop-gradient targets. Region Decouple Regularization (RDR) enforces class-selective prediction consistency in confident regions while blocking gradients to the fusion branch. This feedback loop strengthens unimodal paths without degrading the fused stream, enabling efficient standalone inference at test time. Extensive experiments demonstrate the effectiveness of RTFDNet, showing consistent performance across varying modality conditions. Our implementation will be released to facilitate further research. Our source code are publicly available at https://github.com/curapima/RTFDNet.
DisCo-Layout: Disentangling and Coordinating Semantic and Physical Refinement in a Multi-Agent Framework for 3D Indoor Layout Synthesis
Oct 02, 2025



3D indoor layout synthesis is crucial for creating virtual environments. Traditional methods struggle with generalization due to fixed datasets. While recent LLM and VLM-based approaches offer improved semantic richness, they often lack robust and flexible refinement, resulting in suboptimal layouts. We develop DisCo-Layout, a novel framework that disentangles and coordinates physical and semantic refinement. For independent refinement, our Semantic Refinement Tool (SRT) corrects abstract object relationships, while the Physical Refinement Tool (PRT) resolves concrete spatial issues via a grid-matching algorithm. For collaborative refinement, a multi-agent framework intelligently orchestrates these tools, featuring a planner for placement rules, a designer for initial layouts, and an evaluator for assessment. Experiments demonstrate DisCo-Layout's state-of-the-art performance, generating realistic, coherent, and generalizable 3D indoor layouts. Our code will be publicly available.
Explicit Attention-Enhanced Fusion for RGB-Thermal Perception Tasks
Mar 28, 2023



Recently, RGB-Thermal based perception has shown significant advances. Thermal information provides useful clues when visual cameras suffer from poor lighting conditions, such as low light and fog. However, how to effectively fuse RGB images and thermal data remains an open challenge. Previous works involve naive fusion strategies such as merging them at the input, concatenating multi-modality features inside models, or applying attention to each data modality. These fusion strategies are straightforward yet insufficient. In this paper, we propose a novel fusion method named Explicit Attention-Enhanced Fusion (EAEF) that fully takes advantage of each type of data. Specifically, we consider the following cases: i) both RGB data and thermal data, ii) only one of the types of data, and iii) none of them generate discriminative features. EAEF uses one branch to enhance feature extraction for i) and iii) and the other branch to remedy insufficient representations for ii). The outputs of two branches are fused to form complementary features. As a result, the proposed fusion method outperforms state-of-the-art by 1.6\% in mIoU on semantic segmentation, 3.1\% in MAE on salient object detection, 2.3\% in mAP on object detection, and 8.1\% in MAE on crowd counting. The code is available at https://github.com/FreeformRobotics/EAEFNet.
Abnormal Occupancy Grid Map Recognition using Attention Network
Oct 18, 2021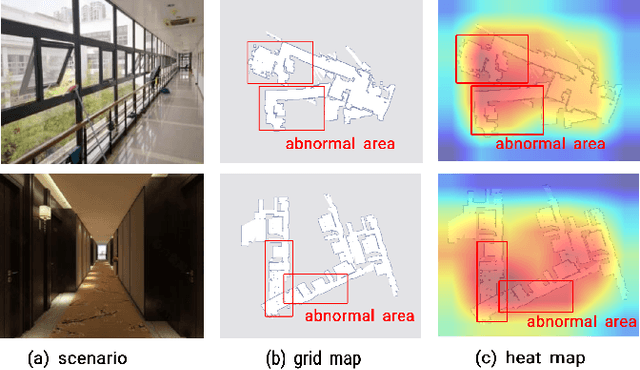
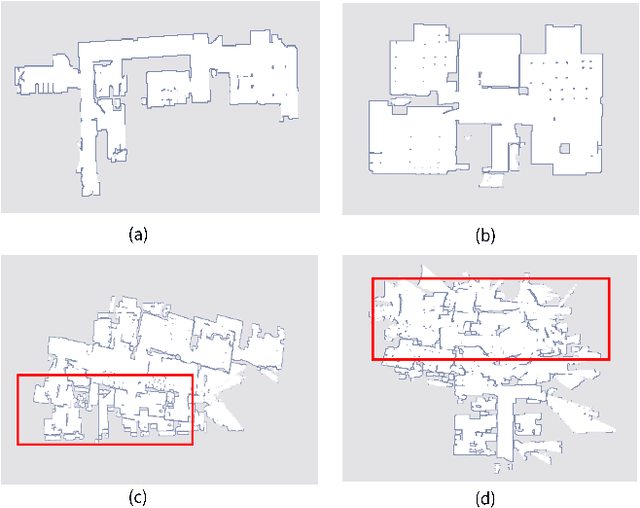
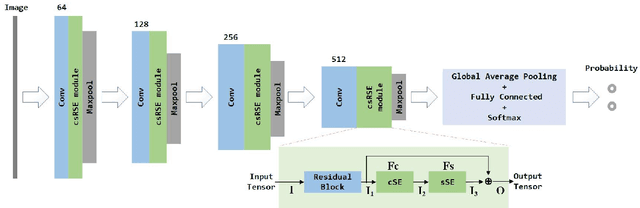

The occupancy grid map is a critical component of autonomous positioning and navigation in the mobile robotic system, as many other systems' performance depends heavily on it. To guarantee the quality of the occupancy grid maps, researchers previously had to perform tedious manual recognition for a long time. This work focuses on automatic abnormal occupancy grid map recognition using the residual neural networks and a novel attention mechanism module. We propose an effective channel and spatial Residual SE(csRSE) attention module, which contains a residual block for producing hierarchical features, followed by both channel SE (cSE) block and spatial SE (sSE) block for the sufficient information extraction along the channel and spatial pathways. To further summarize the occupancy grid map characteristics and experiment with our csRSE attention modules, we constructed a dataset called occupancy grid map dataset (OGMD) for our experiments. On this OGMD test dataset, we tested few variants of our proposed structure and compared them with other attention mechanisms. Our experimental results show that the proposed attention network can infer the abnormal map with state-of-the-art (SOTA) accuracy of 96.23% for abnormal occupancy grid map recognition.
FEANet: Feature-Enhanced Attention Network for RGB-Thermal Real-time Semantic Segmentation
Oct 18, 2021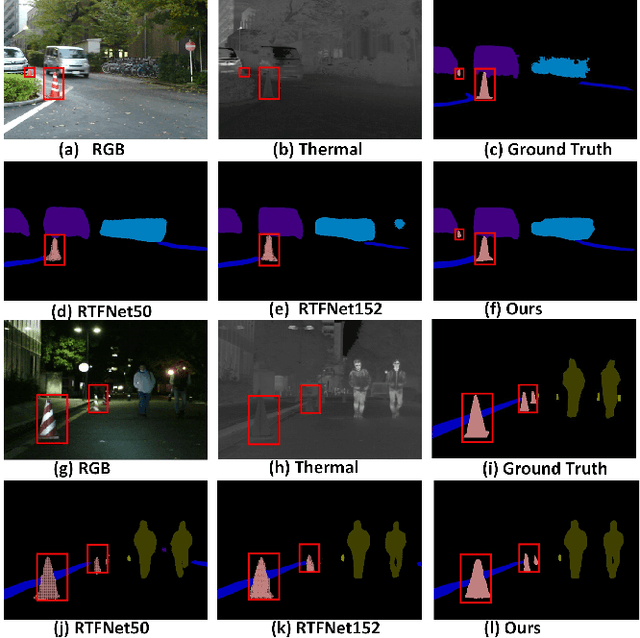
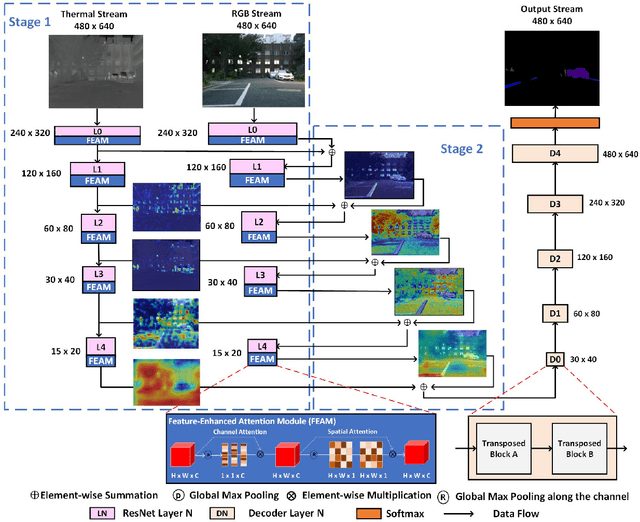
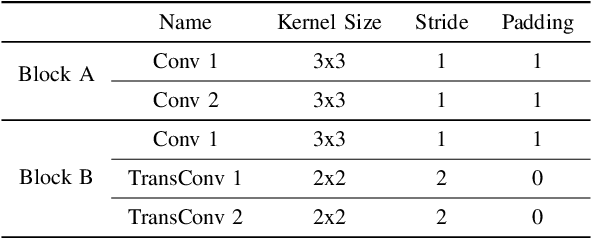
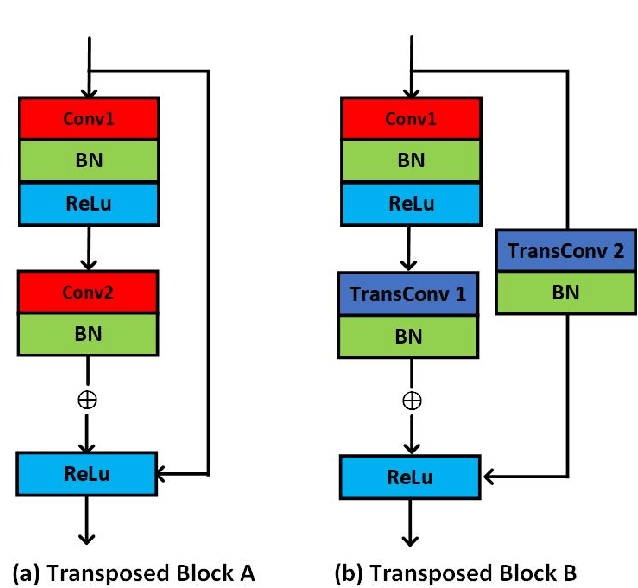
The RGB-Thermal (RGB-T) information for semantic segmentation has been extensively explored in recent years. However, most existing RGB-T semantic segmentation usually compromises spatial resolution to achieve real-time inference speed, which leads to poor performance. To better extract detail spatial information, we propose a two-stage Feature-Enhanced Attention Network (FEANet) for the RGB-T semantic segmentation task. Specifically, we introduce a Feature-Enhanced Attention Module (FEAM) to excavate and enhance multi-level features from both the channel and spatial views. Benefited from the proposed FEAM module, our FEANet can preserve the spatial information and shift more attention to high-resolution features from the fused RGB-T images. Extensive experiments on the urban scene dataset demonstrate that our FEANet outperforms other state-of-the-art (SOTA) RGB-T methods in terms of objective metrics and subjective visual comparison (+2.6% in global mAcc and +0.8% in global mIoU). For the 480 x 640 RGB-T test images, our FEANet can run with a real-time speed on an NVIDIA GeForce RTX 2080 Ti card.