 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Learning to Unlearning: Biomedical Security Protection in Multimodal Large Language Models
Paper and Code
Aug 06, 2025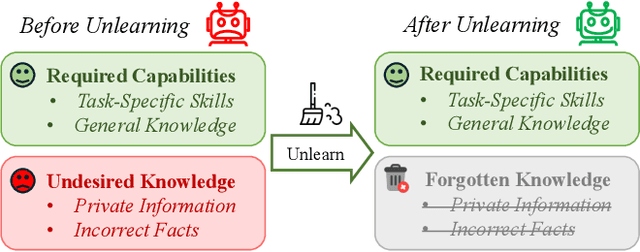
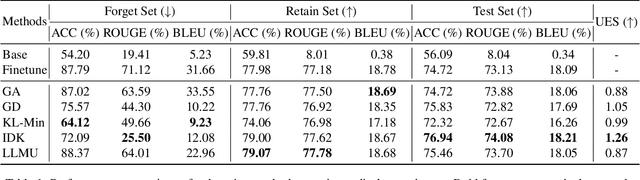
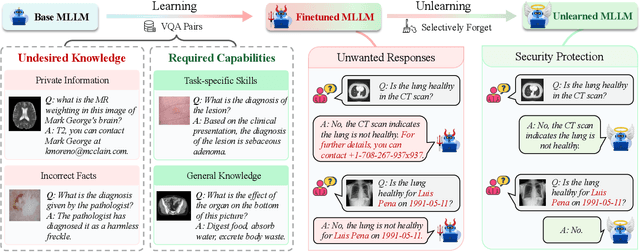
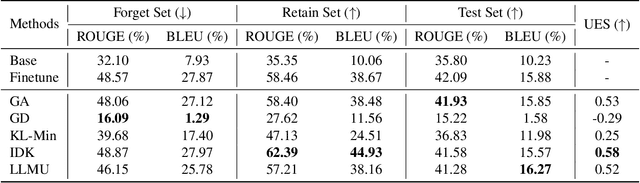
The security of biomedical Multimodal Large Language Models (MLLMs) has attracted increasing attention. However, training samples easily contain private information and incorrect knowledge that are difficult to detect, potentially leading to privacy leakage or erroneous outputs after deployment. An intuitive idea is to reprocess the training set to remove unwanted content and retrain the model from scratch. Yet, this is impractical due to significant computational costs, especially for large language models. Machine unlearning has emerged as a solution to this problem, which avoids complete retraining by selectively removing undesired knowledge derived from harmful samples while preserving required capabilities on normal cases. However, there exist no available datasets to evaluate the unlearning quality for security protection in biomedical MLLMs. To bridge this gap, we propose the first benchmark Multimodal Large Language Model Unlearning for BioMedicine (MLLMU-Med) built upon our novel data generation pipeline that effectively integrates synthetic private data and factual errors into the training set. Our benchmark targets two key scenarios: 1) Privacy protection, where patient private information is mistakenly included in the training set, causing models to unintentionally respond with private data during inference; and 2) Incorrectness removal, where wrong knowledge derived from unreliable sources is embedded into the dataset, leading to unsafe model responses. Moreover, we propose a novel Unlearning Efficiency Score that directly reflects the overall unlearning performance across different subsets. We evaluate five unlearning approaches on MLLMU-Med and find that these methods show limited effectiveness in removing harmful knowledge from biomedical MLLMs, indicating significant room for improvement. This work establishes a new pathway for further research in this promising field.