 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCTS-Judge: Test-Time Scaling in LLM-as-a-Judge for Code Correctness Evaluation
Feb 18, 2025The LLM-as-a-Judge paradigm shows promise for evaluating generative content but lacks reliability in reasoning-intensive scenarios, such as programming. Inspired by recent advances in reasoning models and shifts in scaling laws, we pioneer bringing test-time computation into LLM-as-a-Judge, proposing MCTS-Judge, a resource-efficient, System-2 thinking framework for code correctness evaluation. MCTS-Judge leverages Monte Carlo Tree Search (MCTS) to decompose problems into simpler, multi-perspective evaluations. Through a node-selection strategy that combines self-assessment based on historical actions in the current trajectory and the Upper Confidence Bound for Trees based on prior rollouts, MCTS-Judge balances global optimization and refinement of the current trajectory. We further designed a high-precision, unit-test-level reward mechanism to encourage the Large Language Model (LLM) to perform line-by-line analysis. Extensive experiments on three benchmarks and five LLMs demonstrate the effectiveness of MCTS-Judge, which improves the base model's accuracy from 41% to 80%, surpassing the o1-series models with 3x fewer tokens. Further evaluations validate the superiority of its reasoning trajectory in logic, analytics, thoroughness, and overall quality, while revealing the test-time scaling law of the LLM-as-a-Judge paradigm.
LLMCBench: Benchmarking Large Language Model Compression for Efficient Deployment
Oct 28, 2024



Although large language models (LLMs) have demonstrated their strong intelligence ability, the high demand for computation and storage hinders their practical application. To this end, many model compression techniques are proposed to increase the efficiency of LLMs. However, current researches only validate their methods on limited models, datasets, metrics, etc, and still lack a comprehensive evaluation under more general scenarios. So it is still a question of which model compression approach we should use under a specific case. To mitigate this gap, we present the Large Language Model Compression Benchmark (LLMCBench), a rigorously designed benchmark with an in-depth analysis for LLM compression algorithms. We first analyze the actual model production requirements and carefully design evaluation tracks and metrics. Then, we conduct extensive experiments and comparison using multiple mainstream LLM compression approaches. Finally, we perform an in-depth analysis based on the evaluation and provide useful insight for LLM compression design. We hope our LLMCBench can contribute insightful suggestions for LLM compression algorithm design and serve as a foundation for future research. Our code is available at https://github.com/AboveParadise/LLMCBench.
Beyond Uncertainty: Evidential Deep Learning for Robust Video Temporal Grounding
Aug 29, 2024Existing Video Temporal Grounding (VTG) models excel in accuracy but often overlook open-world challenges posed by open-vocabulary queries and untrimmed videos. This leads to unreliable predictions for noisy, corrupted, and out-of-distribution data. Adapting VTG models to dynamically estimate uncertainties based on user input can address this issue. To this end, we introduce SRAM, a robust network module that benefits from a two-stage cross-modal alignment task. More importantly, it integrates Deep Evidential Regression (DER) to explicitly and thoroughly quantify uncertainty during training, thus allowing the model to say "I do not know" in scenarios beyond its handling capacity. However, the direct application of traditional DER theory and its regularizer reveals structural flaws, leading to unintended constraints in VTG tasks. In response, we develop a simple yet effective Geom-regularizer that enhances the uncertainty learning framework from the ground up. To the best of our knowledge, this marks the first successful attempt of DER in VTG. Our extensive quantitative and qualitative results affirm the effectiveness, robustness, and interpretability of our modules and the uncertainty learning paradigm in VTG tasks. The code will be made available.
NeuroBind: Towards Unified Multimodal Representations for Neural Signals
Jul 19, 2024



Understanding neural activity and information representation is crucial for advancing knowledge of brain function and cognition. Neural activity, measured through techniques like electrophysiology and neuroimaging, reflects various aspects of information processing. Recent advances in deep neural networks offer new approaches to analyzing these signals using pre-trained models. However, challenges arise due to discrepancies between different neural signal modalities and the limited scale of high-quality neural data. To address these challenges, we present NeuroBind, a general representation that unifies multiple brain signal types, including EEG, fMRI, calcium imaging, and spiking data. To achieve this, we align neural signals in these image-paired neural datasets to pre-trained vision-language embeddings. Neurobind is the first model that studies different neural modalities interconnectedly and is able to leverage high-resource modality models for various neuroscience tasks. We also showed that by combining information from different neural signal modalities, NeuroBind enhances downstream performance, demonstrating the effectiveness of the complementary strengths of different neural modalities. As a result, we can leverage multiple types of neural signals mapped to the same space to improve downstream tasks, and demonstrate the complementary strengths of different neural modalities. This approach holds significant potential for advancing neuroscience research, improving AI systems, and developing neuroprosthetics and brain-computer interfaces.
Sparse Diffusion Policy: A Sparse, Reusable, and Flexible Policy for Robot Learning
Jul 01, 2024



The increasing complexity of tasks in robotics demands efficient strategies for multitask and continual learning. Traditional models typically rely on a universal policy for all tasks, facing challenges such as high computational costs and catastrophic forgetting when learning new tasks. To address these issues, we introduce a sparse, reusable, and flexible policy, Sparse Diffusion Policy (SDP). By adopting Mixture of Experts (MoE) within a transformer-based diffusion policy, SDP selectively activates experts and skills, enabling efficient and task-specific learning without retraining the entire model. SDP not only reduces the burden of active parameters but also facilitates the seamless integration and reuse of experts across various tasks. Extensive experiments on diverse tasks in both simulations and real world show that SDP 1) excels in multitask scenarios with negligible increases in active parameters, 2) prevents forgetting in continual learning of new tasks, and 3) enables efficient task transfer, offering a promising solution for advanced robotic applications. Demos and codes can be found in https://forrest-110.github.io/sparse_diffusion_policy/.
Decoding by Contrasting Knowledge: Enhancing LLMs' Confidence on Edited Facts
May 21, 2024



The knowledge within large language models (LLMs) may become outdated quickly. While in-context editing (ICE) is currently the most effective method for knowledge editing (KE), it is constrained by the black-box modeling of LLMs and thus lacks interpretability. Our work aims to elucidate the superior performance of ICE on the KE by analyzing the impacts of in-context new knowledge on token-wise distributions. We observe that despite a significant boost in logits of the new knowledge, the performance of is still hindered by stubborn knowledge. Stubborn knowledge refers to as facts that have gained excessive confidence during pretraining, making it hard to edit effectively. To address this issue and further enhance the performance of ICE, we propose a novel approach termed $\textbf{De}$coding by $\textbf{C}$ontrasting $\textbf{K}$nowledge (DeCK). DeCK derives the distribution of the next token by contrasting the logits obtained from the newly edited knowledge guided by ICE with those from the unedited parametric knowledge. Our experiments consistently demonstrate that DeCK enhances the confidence of LLMs in edited facts. For instance, it improves the performance of LLaMA3-8B-instruct on MQuAKE by up to 219%, demonstrating its capability to strengthen ICE in the editing of stubborn knowledge. Our work paves the way to develop the both effective and accountable KE methods for LLMs. (The source code is available at: https://deck-llm.meirtz.com)
Animal3D: A Comprehensive Dataset of 3D Animal Pose and Shape
Aug 22, 2023



Accurately estimating the 3D pose and shape is an essential step towards understanding animal behavior, and can potentially benefit many downstream applications, such as wildlife conservation. However, research in this area is held back by the lack of a comprehensive and diverse dataset with high-quality 3D pose and shape annotations. In this paper, we propose Animal3D, the first comprehensive dataset for mammal animal 3D pose and shape estimation. Animal3D consists of 3379 images collected from 40 mammal species, high-quality annotations of 26 keypoints, and importantly the pose and shape parameters of the SMAL model. All annotations were labeled and checked manually in a multi-stage process to ensure highest quality results. Based on the Animal3D dataset, we benchmark representative shape and pose estimation models at: (1) supervised learning from only the Animal3D data, (2) synthetic to real transfer from synthetically generated images, and (3) fine-tuning human pose and shape estimation models. Our experimental results demonstrate that predicting the 3D shape and pose of animals across species remains a very challenging task, despite significant advances in human pose estimation. Our results further demonstrate that synthetic pre-training is a viable strategy to boost the model performance. Overall, Animal3D opens new directions for facilitating future research in animal 3D pose and shape estimation, and is publicly available.
3D-Aware Neural Body Fitting for Occlusion Robust 3D Human Pose Estimation
Aug 19, 2023Regression-based methods for 3D human pose estimation directly predict the 3D pose parameters from a 2D image using deep networks. While achieving state-of-the-art performance on standard benchmarks, their performance degrades under occlusion. In contrast, optimization-based methods fit a parametric body model to 2D features in an iterative manner. The localized reconstruction loss can potentially make them robust to occlusion, but they suffer from the 2D-3D ambiguity. Motivated by the recent success of generative models in rigid object pose estimation, we propose 3D-aware Neural Body Fitting (3DNBF) - an approximate analysis-by-synthesis approach to 3D human pose estimation with SOTA performance and occlusion robustness. In particular, we propose a generative model of deep features based on a volumetric human representation with Gaussian ellipsoidal kernels emitting 3D pose-dependent feature vectors. The neural features are trained with contrastive learning to become 3D-aware and hence to overcome the 2D-3D ambiguity. Experiments show that 3DNBF outperforms other approaches on both occluded and standard benchmarks. Code is available at https://github.com/edz-o/3DNBF
Dynamics-aware Adversarial Attack of 3D Sparse Convolution Network
Dec 17, 2021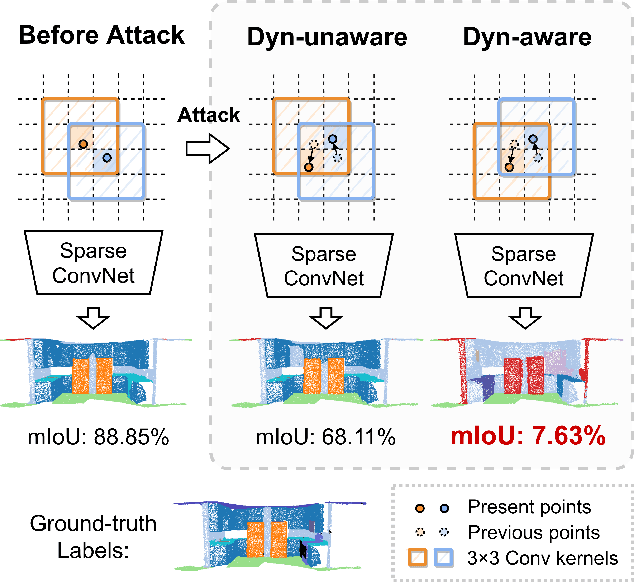

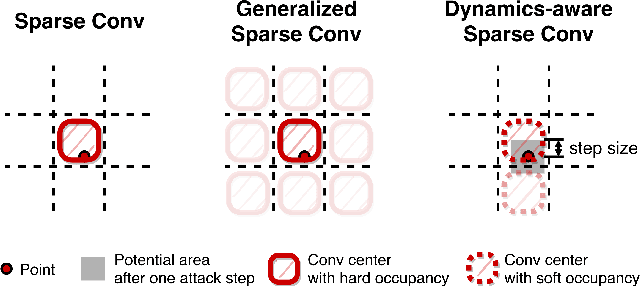
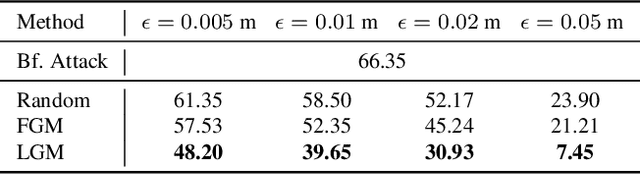
In this paper, we investigate the dynamics-aware adversarial attack problem in deep neural networks. Most existing adversarial attack algorithms are designed under a basic assumption -- the network architecture is fixed throughout the attack process. However, this assumption does not hold for many recently proposed networks, e.g. 3D sparse convolution network, which contains input-dependent execution to improve computational efficiency. It results in a serious issue of lagged gradient, making the learned attack at the current step ineffective due to the architecture changes afterward. To address this issue, we propose a Leaded Gradient Method (LGM) and show the significant effects of the lagged gradient. More specifically, we re-formulate the gradients to be aware of the potential dynamic changes of network architectures, so that the learned attack better "leads" the next step than the dynamics-unaware methods when network architecture changes dynamically. Extensive experiments on various datasets show that our LGM achieves impressive performance on semantic segmentation and classification. Compared with the dynamic-unaware methods, LGM achieves about 20% lower mIoU averagely on the ScanNet and S3DIS datasets. LGM also outperforms the recent point cloud attacks.
PREMA: Part-based REcurrent Multi-view Aggregation Network for 3D Shape Retrieval
Nov 09, 2021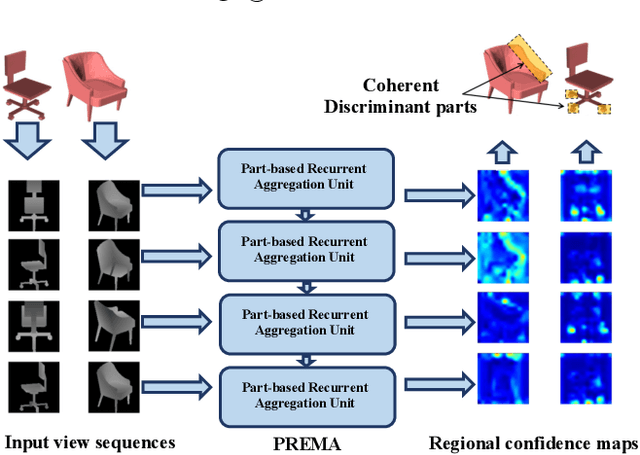
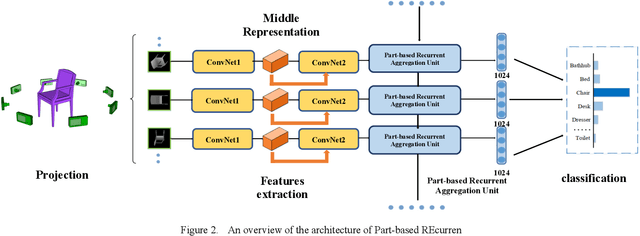
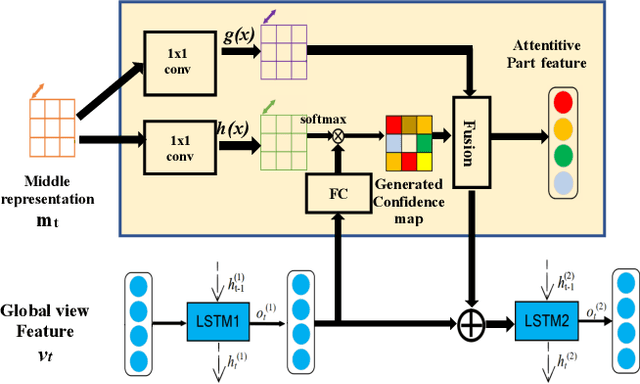

We propose the Part-based Recurrent Multi-view Aggregation network(PREMA) to eliminate the detrimental effects of the practical view defects, such as insufficient view numbers, occlusions or background clutters, and also enhance the discriminative ability of shape representations. Inspired by the fact that human recognize an object mainly by its discriminant parts, we define the multi-view coherent part(MCP), a discriminant part reoccurring in different views. Our PREMA can reliably locate and effectively utilize MCPs to build robust shape representations. Comprehensively, we design a novel Regional Attention Unit(RAU) in PREMA to compute the confidence map for each view, and extract MCPs by applying those maps to view features. PREMA accentuates MCPs via correlating features of different views, and aggregates the part-aware features for shape representation.