 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataEvolver: Let Your Data Build and Improve Itself via Goal-Driven Loop Agents
May 03, 2026Constructing controllable visual data is a major bottleneck for image editing and multimodal understanding. Useful supervision is rarely produced by a single rendering pass; instead it emerges through iterative generation, inspection, correction, filtering, and export. We present DataEvolver, a closed-loop visual data engine that organizes this process around explicit goals, persistent artifacts, bounded corrective actions, and acceptance decisions. DataEvolver supports multiple artifact types, including RGB images, masks, depth maps, normal maps, meshes, poses, trajectories, and review traces. In the current release, the system operates through two coupled loops: generation-time self-correction within each sample and validation-time self-expansion across dataset rounds. We validate the framework on an image-level object-rotation setting. With a fixed Qwen-Edit LoRA probe, our final Ours+DualGate model outperforms both the unadapted base model and a public multi-angle LoRA on SpatialEdit and a held-out evaluation set. Ablations show a consistent improvement path from scene-aware generation to feedback-driven correction and dual-gated validation. Beyond the released rotation data, our main contribution is a reusable framework for building visual datasets through explicit goal tracking, review, correction, and acceptance loops.
Geometric Image Editing via Effects-Sensitive In-Context Inpainting with Diffusion Transformers
Feb 09, 2026Recent advances in diffusion models have significantly improved image editing. However, challenges persist in handling geometric transformations, such as translation, rotation, and scaling, particularly in complex scenes. Existing approaches suffer from two main limitations: (1) difficulty in achieving accurate geometric editing of object translation, rotation, and scaling; (2) inadequate modeling of intricate lighting and shadow effects, leading to unrealistic results. To address these issues, we propose GeoEdit, a framework that leverages in-context generation through a diffusion transformer module, which integrates geometric transformations for precise object edits. Moreover, we introduce Effects-Sensitive Attention, which enhances the modeling of intricate lighting and shadow effects for improved realism. To further support training, we construct RS-Objects, a large-scale geometric editing dataset containing over 120,000 high-quality image pairs, enabling the model to learn precise geometric editing while generating realistic lighting and shadows. Extensive experiments on public benchmarks demonstrate that GeoEdit consistently outperforms state-of-the-art methods in terms of visual quality, geometric accuracy, and realism.
Beyond Uncertainty: Evidential Deep Learning for Robust Video Temporal Grounding
Aug 29, 2024Existing Video Temporal Grounding (VTG) models excel in accuracy but often overlook open-world challenges posed by open-vocabulary queries and untrimmed videos. This leads to unreliable predictions for noisy, corrupted, and out-of-distribution data. Adapting VTG models to dynamically estimate uncertainties based on user input can address this issue. To this end, we introduce SRAM, a robust network module that benefits from a two-stage cross-modal alignment task. More importantly, it integrates Deep Evidential Regression (DER) to explicitly and thoroughly quantify uncertainty during training, thus allowing the model to say "I do not know" in scenarios beyond its handling capacity. However, the direct application of traditional DER theory and its regularizer reveals structural flaws, leading to unintended constraints in VTG tasks. In response, we develop a simple yet effective Geom-regularizer that enhances the uncertainty learning framework from the ground up. To the best of our knowledge, this marks the first successful attempt of DER in VTG. Our extensive quantitative and qualitative results affirm the effectiveness, robustness, and interpretability of our modules and the uncertainty learning paradigm in VTG tasks. The code will be made available.
Disentangle and denoise: Tackling context misalignment for video moment retrieval
Aug 14, 2024Video Moment Retrieval, which aims to locate in-context video moments according to a natural language query, is an essential task for cross-modal grounding. Existing methods focus on enhancing the cross-modal interactions between all moments and the textual description for video understanding. However, constantly interacting with all locations is unreasonable because of uneven semantic distribution across the timeline and noisy visual backgrounds. This paper proposes a cross-modal Context Denoising Network (CDNet) for accurate moment retrieval by disentangling complex correlations and denoising irrelevant dynamics.Specifically, we propose a query-guided semantic disentanglement (QSD) to decouple video moments by estimating alignment levels according to the global and fine-grained correlation. A Context-aware Dynamic Denoisement (CDD) is proposed to enhance understanding of aligned spatial-temporal details by learning a group of query-relevant offsets. Extensive experiments on public benchmarks demonstrate that the proposed CDNet achieves state-of-the-art performances.
ProTA: Probabilistic Token Aggregation for Text-Video Retrieval
Apr 18, 2024



Text-video retrieval aims to find the most relevant cross-modal samples for a given query. Recent methods focus on modeling the whole spatial-temporal relations. However, since video clips contain more diverse content than captions, the model aligning these asymmetric video-text pairs has a high risk of retrieving many false positive results. In this paper, we propose Probabilistic Token Aggregation (\textit{ProTA}) to handle cross-modal interaction with content asymmetry. Specifically, we propose dual partial-related aggregation to disentangle and re-aggregate token representations in both low-dimension and high-dimension spaces. We propose token-based probabilistic alignment to generate token-level probabilistic representation and maintain the feature representation diversity. In addition, an adaptive contrastive loss is proposed to learn compact cross-modal distribution space. Based on extensive experiments, \textit{ProTA} achieves significant improvements on MSR-VTT (50.9%), LSMDC (25.8%), and DiDeMo (47.2%).
Mask to reconstruct: Cooperative Semantics Completion for Video-text Retrieval
May 13, 2023Recently, masked video modeling has been widely explored and significantly improved the model's understanding ability of visual regions at a local level. However, existing methods usually adopt random masking and follow the same reconstruction paradigm to complete the masked regions, which do not leverage the correlations between cross-modal content. In this paper, we present Mask for Semantics Completion (MASCOT) based on semantic-based masked modeling. Specifically, after applying attention-based video masking to generate high-informed and low-informed masks, we propose Informed Semantics Completion to recover masked semantics information. The recovery mechanism is achieved by aligning the masked content with the unmasked visual regions and corresponding textual context, which makes the model capture more text-related details at a patch level. Additionally, we shift the emphasis of reconstruction from irrelevant backgrounds to discriminative parts to ignore regions with low-informed masks. Furthermore, we design dual-mask co-learning to incorporate video cues under different masks and learn more aligned video representation. Our MASCOT performs state-of-the-art performance on four major text-video retrieval benchmarks, including MSR-VTT, LSMDC, ActivityNet, and DiDeMo. Extensive ablation studies demonstrate the effectiveness of the proposed schemes.
Multi-direction and Multi-scale Pyramid in Transformer for Video-based Pedestrian Retrieval
Feb 12, 2022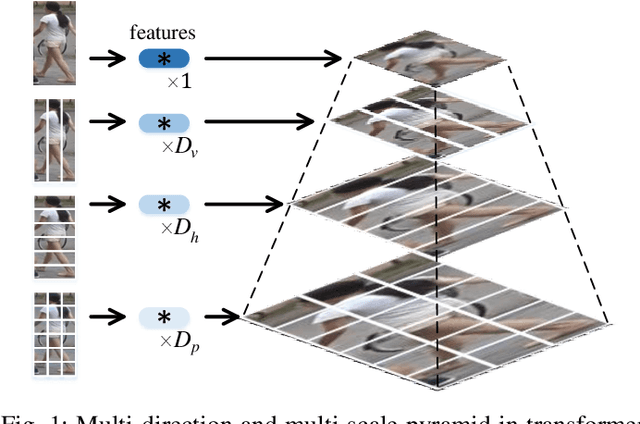
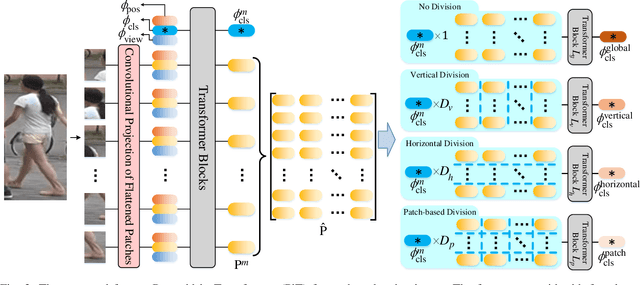
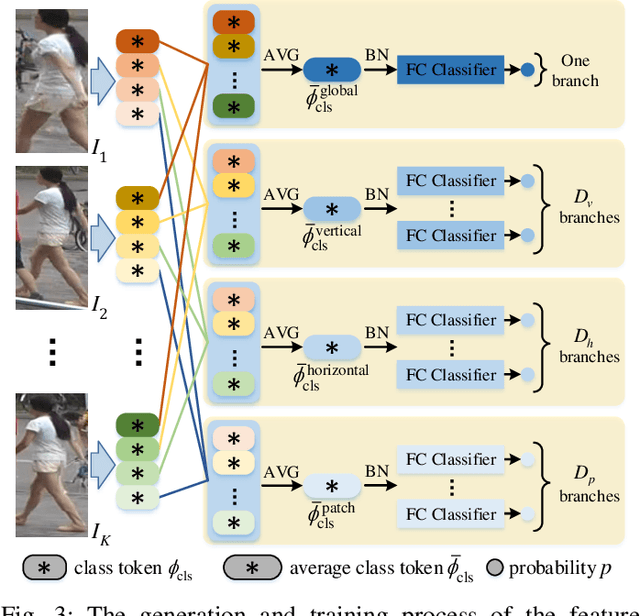
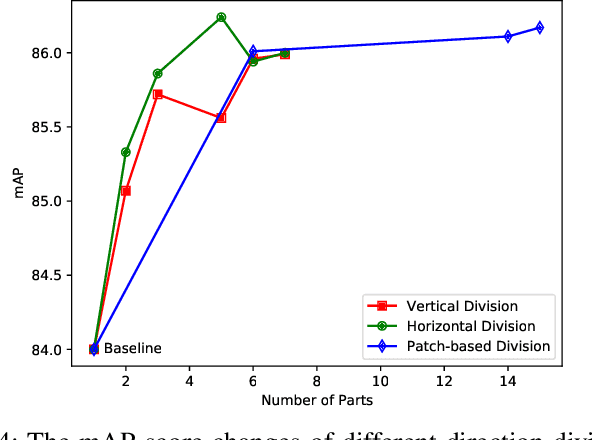
In video surveillance, pedestrian retrieval (also called person re-identification) is a critical task. This task aims to retrieve the pedestrian of interest from non-overlapping cameras. Recently, transformer-based models have achieved significant progress for this task. However, these models still suffer from ignoring fine-grained, part-informed information. This paper proposes a multi-direction and multi-scale Pyramid in Transformer (PiT) to solve this problem. In transformer-based architecture, each pedestrian image is split into many patches. Then, these patches are fed to transformer layers to obtain the feature representation of this image. To explore the fine-grained information, this paper proposes to apply vertical division and horizontal division on these patches to generate different-direction human parts. These parts provide more fine-grained information. To fuse multi-scale feature representation, this paper presents a pyramid structure containing global-level information and many pieces of local-level information from different scales. The feature pyramids of all the pedestrian images from the same video are fused to form the final multi-direction and multi-scale feature representation. Experimental results on two challenging video-based benchmarks, MARS and iLIDS-VID, show the proposed PiT achieves state-of-the-art performance. Extensive ablation studies demonstrate the superiority of the proposed pyramid structure. The code is available at https://git.openi.org.cn/zangxh/PiT.git.
Exploiting Robust Unsupervised Video Person Re-identification
Nov 18, 2021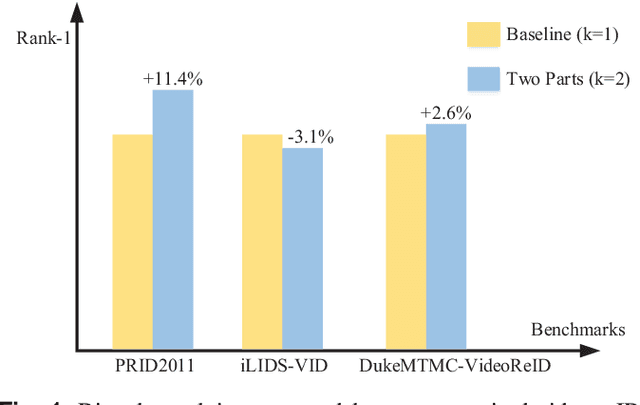
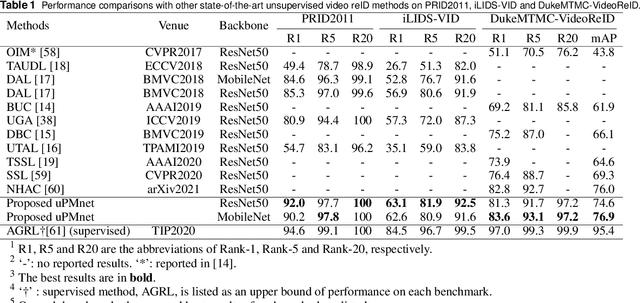


Unsupervised video person re-identification (reID) methods usually depend on global-level features. And many supervised reID methods employed local-level features and achieved significant performance improvements. However, applying local-level features to unsupervised methods may introduce an unstable performance. To improve the performance stability for unsupervised video reID, this paper introduces a general scheme fusing part models and unsupervised learning. In this scheme, the global-level feature is divided into equal local-level feature. A local-aware module is employed to explore the poentials of local-level feature for unsupervised learning. A global-aware module is proposed to overcome the disadvantages of local-level features. Features from these two modules are fused to form a robust feature representation for each input image. This feature representation has the advantages of local-level feature without suffering from its disadvantages. Comprehensive experiments are conducted on three benchmarks, including PRID2011, iLIDS-VID, and DukeMTMC-VideoReID, and the results demonstrate that the proposed approach achieves state-of-the-art performance. Extensive ablation studies demonstrate the effectiveness and robustness of proposed scheme, local-aware module and global-aware module.
Learning to Disentangle Scenes for Person Re-identification
Nov 10, 2021
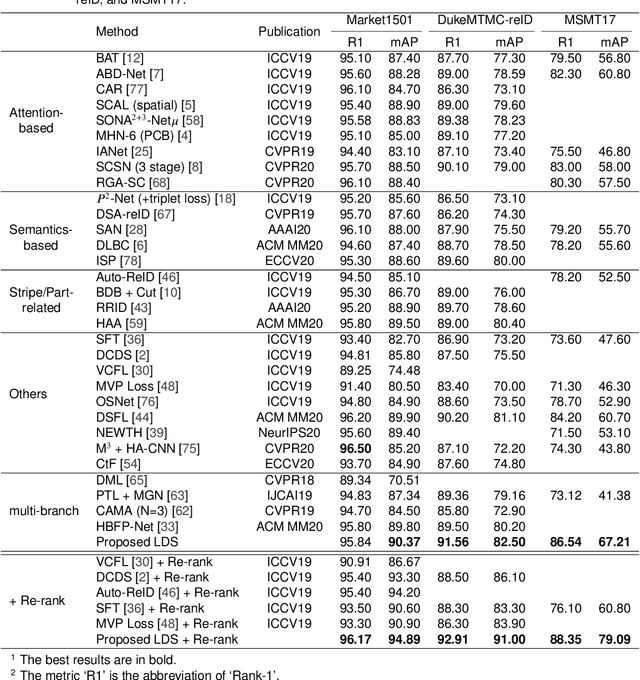
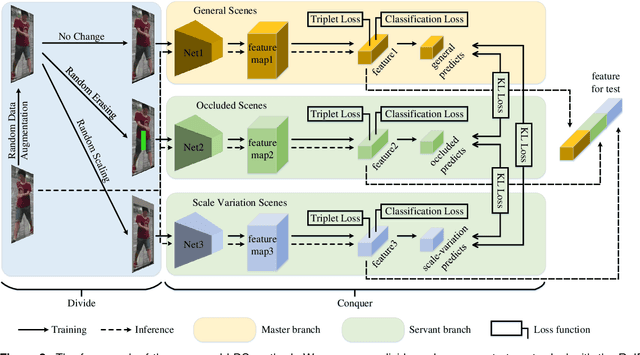
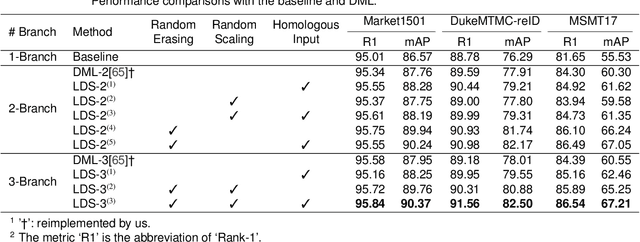
There are many challenging problems in the person re-identification (ReID) task, such as the occlusion and scale variation. Existing works usually tried to solve them by employing a one-branch network. This one-branch network needs to be robust to various challenging problems, which makes this network overburdened. This paper proposes to divide-and-conquer the ReID task. For this purpose, we employ several self-supervision operations to simulate different challenging problems and handle each challenging problem using different networks. Concretely, we use the random erasing operation and propose a novel random scaling operation to generate new images with controllable characteristics. A general multi-branch network, including one master branch and two servant branches, is introduced to handle different scenes. These branches learn collaboratively and achieve different perceptive abilities. In this way, the complex scenes in the ReID task are effectively disentangled, and the burden of each branch is relieved. The results from extensive experiments demonstrate that the proposed method achieves state-of-the-art performances on three ReID benchmarks and two occluded ReID benchmarks. Ablation study also shows that the proposed scheme and operations significantly improve the performance in various scenes.
Large-Scale Spatio-Temporal Person Re-identification: Algorithm and Benchmark
Jun 24, 2021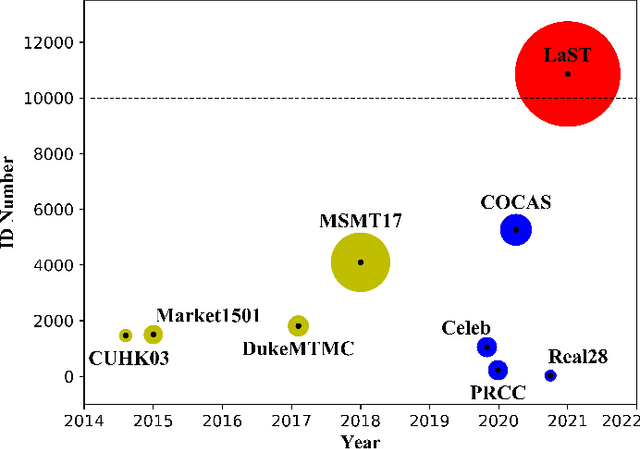
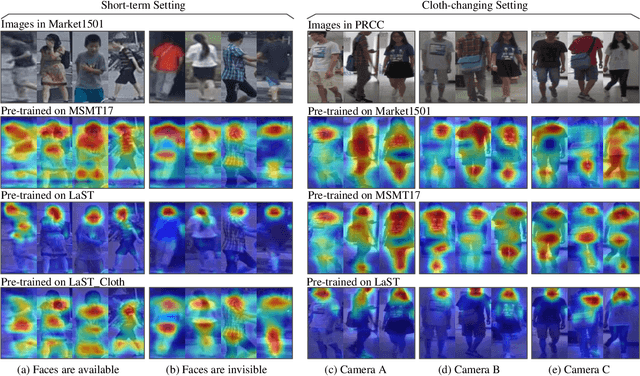
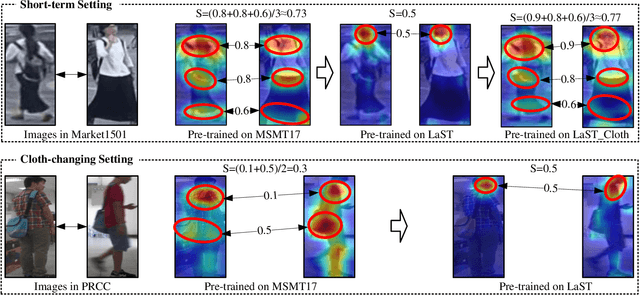

Person re-identification (re-ID) in the scenario with large spatial and temporal spans has not been fully explored. This is partially because that, existing benchmark datasets were mainly collected with limited spatial and temporal ranges, e.g., using videos recorded in a few days by cameras in a specific region of the campus. Such limited spatial and temporal ranges make it hard to simulate the difficulties of person re-ID in real scenarios. In this work, we contribute a novel Large-scale Spatio-Temporal LaST person re-ID dataset, including 10,862 identities with more than 228k images. Compared with existing datasets, LaST presents more challenging and high-diversity re-ID settings, and significantly larger spatial and temporal ranges. For instance, each person can appear in different cities or countries, and in various time slots from daytime to night, and in different seasons from spring to winter. To our best knowledge, LaST is a novel person re-ID dataset with the largest spatio-temporal ranges. Based on LaST, we verified its challenge by conducting a comprehensive performance evaluation of 14 re-ID algorithms. We further propose an easy-to-implement baseline that works well on such challenging re-ID setting. We also verified that models pre-trained on LaST can generalize well on existing datasets with short-term and cloth-changing scenarios. We expect LaST to inspire future works toward more realistic and challenging re-ID tasks. More information about the dataset is available at https://github.com/shuxjweb/last.git.