 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink, Act, Build: An Agentic Framework with Vision Language Models for Zero-Shot 3D Visual Grounding
Apr 02, 20263D Visual Grounding (3D-VG) aims to localize objects in 3D scenes via natural language descriptions. While recent advancements leveraging Vision-Language Models (VLMs) have explored zero-shot possibilities, they typically suffer from a static workflow relying on preprocessed 3D point clouds, essentially degrading grounding into proposal matching. To bypass this reliance, our core motivation is to decouple the task: leveraging 2D VLMs to resolve complex spatial semantics, while relying on deterministic multi-view geometry to instantiate the 3D structure. Driven by this insight, we propose "Think, Act, Build (TAB)", a dynamic agentic framework that reformulates 3D-VG tasks as a generative 2D-to-3D reconstruction paradigm operating directly on raw RGB-D streams. Specifically, guided by a specialized 3D-VG skill, our VLM agent dynamically invokes visual tools to track and reconstruct the target across 2D frames. Crucially, to overcome the multi-view coverage deficit caused by strict VLM semantic tracking, we introduce the Semantic-Anchored Geometric Expansion, a mechanism that first anchors the target in a reference video clip and then leverages multi-view geometry to propagate its spatial location across unobserved frames. This enables the agent to "Build" the target's 3D representation by aggregating these multi-view features via camera parameters, directly mapping 2D visual cues to 3D coordinates. Furthermore, to ensure rigorous assessment, we identify flaws such as reference ambiguity and category errors in existing benchmarks and manually refine the incorrect queries. Extensive experiments on ScanRefer and Nr3D demonstrate that our framework, relying entirely on open-source models, significantly outperforms previous zero-shot methods and even surpasses fully supervised baselines.
Incentivizing Temporal-Awareness in Egocentric Video Understanding Models
Mar 28, 2026Multimodal large language models (MLLMs) have recently shown strong performance in visual understanding, yet they often lack temporal awareness, particularly in egocentric settings where reasoning depends on the correct ordering and evolution of events. This deficiency stems in part from training objectives that fail to explicitly reward temporal reasoning and instead rely on frame-level spatial shortcuts. To address this limitation, we propose Temporal Global Policy Optimization (TGPO), a reinforcement learning with verifiable rewards (RLVR) algorithm designed to incentivize temporal awareness in MLLMs. TGPO contrasts model outputs generated from temporally ordered versus shuffled video frames to derive calibrated, globally normalized reward signals that explicitly favor temporally coherent reasoning. Integrated with GRPO and GSPO, TGPO supports cold-start RL training and effectively suppresses spatial shortcut behaviors learned by existing MLLMs. Experiments across five egocentric video benchmarks demonstrate that TGPO consistently improves temporal grounding and causal coherence, outperforming prior RL-based video reasoning approaches. Our results suggest that TGPO offers a simple and scalable pathway toward temporally robust MLLMs for egocentric video understanding.
SuperFlow: Training Flow Matching Models with RL on the Fly
Dec 17, 2025Recent progress in flow-based generative models and reinforcement learning (RL) has improved text-image alignment and visual quality. However, current RL training for flow models still has two main problems: (i) GRPO-style fixed per-prompt group sizes ignore variation in sampling importance across prompts, which leads to inefficient sampling and slower training; and (ii) trajectory-level advantages are reused as per-step estimates, which biases credit assignment along the flow. We propose SuperFlow, an RL training framework for flow-based models that adjusts group sizes with variance-aware sampling and computes step-level advantages in a way that is consistent with continuous-time flow dynamics. Empirically, SuperFlow reaches promising performance while using only 5.4% to 56.3% of the original training steps and reduces training time by 5.2% to 16.7% without any architectural changes. On standard text-to-image (T2I) tasks, including text rendering, compositional image generation, and human preference alignment, SuperFlow improves over SD3.5-M by 4.6% to 47.2%, and over Flow-GRPO by 1.7% to 16.0%.
COMPASS: A Multi-Turn Benchmark for Tool-Mediated Planning & Preference Optimization
Oct 08, 2025



Real-world large language model (LLM) agents must master strategic tool use and user preference optimization through multi-turn interactions to assist users with complex planning tasks. We introduce COMPASS (Constrained Optimization through Multi-turn Planning and Strategic Solutions), a benchmark that evaluates agents on realistic travel-planning scenarios. We cast travel planning as a constrained preference optimization problem, where agents must satisfy hard constraints while simultaneously optimizing soft user preferences. To support this, we build a realistic travel database covering transportation, accommodation, and ticketing for 20 U.S. National Parks, along with a comprehensive tool ecosystem that mirrors commercial booking platforms. Evaluating state-of-the-art models, we uncover two critical gaps: (i) an acceptable-optimal gap, where agents reliably meet constraints but fail to optimize preferences, and (ii) a plan-coordination gap, where performance collapses on multi-service (flight and hotel) coordination tasks, especially for open-source models. By grounding reasoning and planning in a practical, user-facing domain, COMPASS provides a benchmark that directly measures an agent's ability to optimize user preferences in realistic tasks, bridging theoretical advances with real-world impact.
Pisces: An Auto-regressive Foundation Model for Image Understanding and Generation
Jun 12, 2025Recent advances in large language models (LLMs) have enabled multimodal foundation models to tackle both image understanding and generation within a unified framework. Despite these gains, unified models often underperform compared to specialized models in either task. A key challenge in developing unified models lies in the inherent differences between the visual features needed for image understanding versus generation, as well as the distinct training processes required for each modality. In this work, we introduce Pisces, an auto-regressive multimodal foundation model that addresses this challenge through a novel decoupled visual encoding architecture and tailored training techniques optimized for multimodal generation. Combined with meticulous data curation, pretraining, and finetuning, Pisces achieves competitive performance in both image understanding and image generation. We evaluate Pisces on over 20 public benchmarks for image understanding, where it demonstrates strong performance across a wide range of tasks. Additionally, on GenEval, a widely adopted benchmark for image generation, Pisces exhibits robust generative capabilities. Our extensive analysis reveals the synergistic relationship between image understanding and generation, and the benefits of using separate visual encoders, advancing the field of unified multimodal models.
AR-RAG: Autoregressive Retrieval Augmentation for Image Generation
Jun 08, 2025We introduce Autoregressive Retrieval Augmentation (AR-RAG), a novel paradigm that enhances image generation by autoregressively incorporating knearest neighbor retrievals at the patch level. Unlike prior methods that perform a single, static retrieval before generation and condition the entire generation on fixed reference images, AR-RAG performs context-aware retrievals at each generation step, using prior-generated patches as queries to retrieve and incorporate the most relevant patch-level visual references, enabling the model to respond to evolving generation needs while avoiding limitations (e.g., over-copying, stylistic bias, etc.) prevalent in existing methods. To realize AR-RAG, we propose two parallel frameworks: (1) Distribution-Augmentation in Decoding (DAiD), a training-free plug-and-use decoding strategy that directly merges the distribution of model-predicted patches with the distribution of retrieved patches, and (2) Feature-Augmentation in Decoding (FAiD), a parameter-efficient fine-tuning method that progressively smooths the features of retrieved patches via multi-scale convolution operations and leverages them to augment the image generation process. We validate the effectiveness of AR-RAG on widely adopted benchmarks, including Midjourney-30K, GenEval and DPG-Bench, demonstrating significant performance gains over state-of-the-art image generation models.
LaTtE-Flow: Layerwise Timestep-Expert Flow-based Transformer
Jun 08, 2025Recent advances in multimodal foundation models unifying image understanding and generation have opened exciting avenues for tackling a wide range of vision-language tasks within a single framework. Despite progress, existing unified models typically require extensive pretraining and struggle to achieve the same level of performance compared to models dedicated to each task. Additionally, many of these models suffer from slow image generation speeds, limiting their practical deployment in real-time or resource-constrained settings. In this work, we propose Layerwise Timestep-Expert Flow-based Transformer (LaTtE-Flow), a novel and efficient architecture that unifies image understanding and generation within a single multimodal model. LaTtE-Flow builds upon powerful pretrained Vision-Language Models (VLMs) to inherit strong multimodal understanding capabilities, and extends them with a novel Layerwise Timestep Experts flow-based architecture for efficient image generation. LaTtE-Flow distributes the flow-matching process across specialized groups of Transformer layers, each responsible for a distinct subset of timesteps. This design significantly improves sampling efficiency by activating only a small subset of layers at each sampling timestep. To further enhance performance, we propose a Timestep-Conditioned Residual Attention mechanism for efficient information reuse across layers. Experiments demonstrate that LaTtE-Flow achieves strong performance on multimodal understanding tasks, while achieving competitive image generation quality with around 6x faster inference speed compared to recent unified multimodal models.
R2I-Bench: Benchmarking Reasoning-Driven Text-to-Image Generation
May 29, 2025

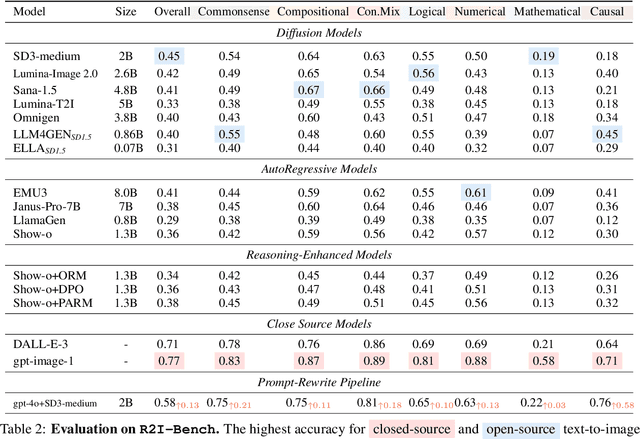

Reasoning is a fundamental capability often required in real-world text-to-image (T2I) generation, e.g., generating ``a bitten apple that has been left in the air for more than a week`` necessitates understanding temporal decay and commonsense concepts. While recent T2I models have made impressive progress in producing photorealistic images, their reasoning capability remains underdeveloped and insufficiently evaluated. To bridge this gap, we introduce R2I-Bench, a comprehensive benchmark specifically designed to rigorously assess reasoning-driven T2I generation. R2I-Bench comprises meticulously curated data instances, spanning core reasoning categories, including commonsense, mathematical, logical, compositional, numerical, causal, and concept mixing. To facilitate fine-grained evaluation, we design R2IScore, a QA-style metric based on instance-specific, reasoning-oriented evaluation questions that assess three critical dimensions: text-image alignment, reasoning accuracy, and image quality. Extensive experiments with 16 representative T2I models, including a strong pipeline-based framework that decouples reasoning and generation using the state-of-the-art language and image generation models, demonstrate consistently limited reasoning performance, highlighting the need for more robust, reasoning-aware architectures in the next generation of T2I systems. Project Page: https://r2i-bench.github.io
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
May 14, 2025Unifying image understanding and generation has gained growing attention in recent research on multimodal models. Although design choices for image understanding have been extensively studied, the optimal model architecture and training recipe for a unified framework with image generation remain underexplored. Motivated by the strong potential of autoregressive and diffusion models for high-quality generation and scalability, we conduct a comprehensive study of their use in unified multimodal settings, with emphasis on image representations, modeling objectives, and training strategies. Grounded in these investigations, we introduce a novel approach that employs a diffusion transformer to generate semantically rich CLIP image features, in contrast to conventional VAE-based representations. This design yields both higher training efficiency and improved generative quality. Furthermore, we demonstrate that a sequential pretraining strategy for unified models-first training on image understanding and subsequently on image generation-offers practical advantages by preserving image understanding capability while developing strong image generation ability. Finally, we carefully curate a high-quality instruction-tuning dataset BLIP3o-60k for image generation by prompting GPT-4o with a diverse set of captions covering various scenes, objects, human gestures, and more. Building on our innovative model design, training recipe, and datasets, we develop BLIP3-o, a suite of state-of-the-art unified multimodal models. BLIP3-o achieves superior performance across most of the popular benchmarks spanning both image understanding and generation tasks. To facilitate future research, we fully open-source our models, including code, model weights, training scripts, and pretraining and instruction tuning datasets.
LLM Can be a Dangerous Persuader: Empirical Study of Persuasion Safety in Large Language Models
Apr 14, 2025



Recent advancements in Large Language Models (LLMs) have enabled them to approach human-level persuasion capabilities. However, such potential also raises concerns about the safety risks of LLM-driven persuasion, particularly their potential for unethical influence through manipulation, deception, exploitation of vulnerabilities, and many other harmful tactics. In this work, we present a systematic investigation of LLM persuasion safety through two critical aspects: (1) whether LLMs appropriately reject unethical persuasion tasks and avoid unethical strategies during execution, including cases where the initial persuasion goal appears ethically neutral, and (2) how influencing factors like personality traits and external pressures affect their behavior. To this end, we introduce PersuSafety, the first comprehensive framework for the assessment of persuasion safety which consists of three stages, i.e., persuasion scene creation, persuasive conversation simulation, and persuasion safety assessment. PersuSafety covers 6 diverse unethical persuasion topics and 15 common unethical strategies. Through extensive experiments across 8 widely used LLMs, we observe significant safety concerns in most LLMs, including failing to identify harmful persuasion tasks and leveraging various unethical persuasion strategies. Our study calls for more attention to improve safety alignment in progressive and goal-driven conversations such as persuasion.