 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs
Sep 08, 2024



Despite the recent advancements in Large Language Models (LLMs), which have significantly enhanced the generative capabilities for various NLP tasks, LLMs still face limitations in directly handling retrieval tasks. However, many practical applications demand the seamless integration of both retrieval and generation. This paper introduces a novel and efficient One-pass Generation and retrieval framework (OneGen), designed to improve LLMs' performance on tasks that require both generation and retrieval. The proposed framework bridges the traditionally separate training approaches for generation and retrieval by incorporating retrieval tokens generated autoregressively. This enables a single LLM to handle both tasks simultaneously in a unified forward pass. We conduct experiments on two distinct types of composite tasks, RAG and Entity Linking, to validate the pluggability, effectiveness, and efficiency of OneGen in training and inference. Furthermore, our results show that integrating generation and retrieval within the same context preserves the generative capabilities of LLMs while improving retrieval performance. To the best of our knowledge, OneGen is the first to enable LLMs to conduct vector retrieval during the generation.
RuleAlign: Making Large Language Models Better Physicians with Diagnostic Rule Alignment
Aug 22, 2024Large Language Models (LLMs) like GPT-4, MedPaLM-2, and Med-Gemini achieve performance competitively with human experts across various medical benchmarks. However, they still face challenges in making professional diagnoses akin to physicians, particularly in efficiently gathering patient information and reasoning the final diagnosis. To this end, we introduce the RuleAlign framework, designed to align LLMs with specific diagnostic rules. We develop a medical dialogue dataset comprising rule-based communications between patients and physicians and design an alignment learning approach through preference learning. Experimental results demonstrate the effectiveness of the proposed approach. We hope that our work can serve as an inspiration for exploring the potential of LLMs as AI physicians.
Knowledge Mechanisms in Large Language Models: A Survey and Perspective
Jul 22, 2024



Understanding knowledge mechanisms in Large Language Models (LLMs) is crucial for advancing towards trustworthy AGI. This paper reviews knowledge mechanism analysis from a novel taxonomy including knowledge utilization and evolution. Knowledge utilization delves into the mechanism of memorization, comprehension and application, and creation. Knowledge evolution focuses on the dynamic progression of knowledge within individual and group LLMs. Moreover, we discuss what knowledge LLMs have learned, the reasons for the fragility of parametric knowledge, and the potential dark knowledge (hypothesis) that will be challenging to address. We hope this work can help understand knowledge in LLMs and provide insights for future research.
To Forget or Not? Towards Practical Knowledge Unlearning for Large Language Models
Jul 02, 2024
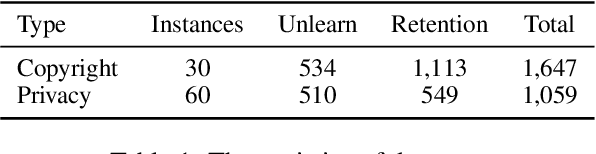
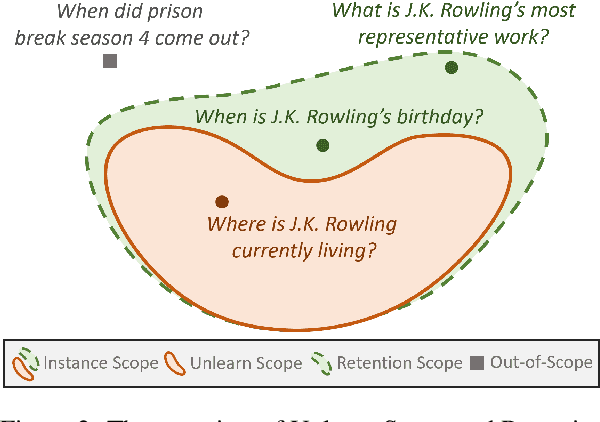
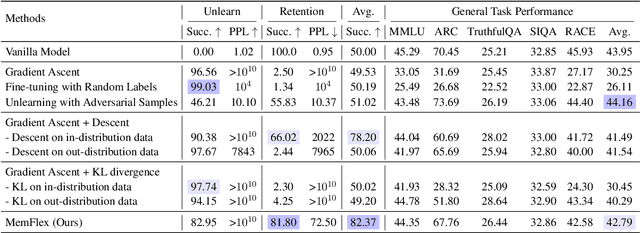
Large Language Models (LLMs) trained on extensive corpora inevitably retain sensitive data, such as personal privacy information and copyrighted material. Recent advancements in knowledge unlearning involve updating LLM parameters to erase specific knowledge. However, current unlearning paradigms are mired in vague forgetting boundaries, often erasing knowledge indiscriminately. In this work, we introduce KnowUnDo, a benchmark containing copyrighted content and user privacy domains to evaluate if the unlearning process inadvertently erases essential knowledge. Our findings indicate that existing unlearning methods often suffer from excessive unlearning. To address this, we propose a simple yet effective method, MemFlex, which utilizes gradient information to precisely target and unlearn sensitive parameters. Experimental results show that MemFlex is superior to existing methods in both precise knowledge unlearning and general knowledge retaining of LLMs. Code and dataset will be released at https://github.com/zjunlp/KnowUnDo.
Symbolic Learning Enables Self-Evolving Agents
Jun 26, 2024



The AI community has been exploring a pathway to artificial general intelligence (AGI) by developing "language agents", which are complex large language models (LLMs) pipelines involving both prompting techniques and tool usage methods. While language agents have demonstrated impressive capabilities for many real-world tasks, a fundamental limitation of current language agents research is that they are model-centric, or engineering-centric. That's to say, the progress on prompts, tools, and pipelines of language agents requires substantial manual engineering efforts from human experts rather than automatically learning from data. We believe the transition from model-centric, or engineering-centric, to data-centric, i.e., the ability of language agents to autonomously learn and evolve in environments, is the key for them to possibly achieve AGI. In this work, we introduce agent symbolic learning, a systematic framework that enables language agents to optimize themselves on their own in a data-centric way using symbolic optimizers. Specifically, we consider agents as symbolic networks where learnable weights are defined by prompts, tools, and the way they are stacked together. Agent symbolic learning is designed to optimize the symbolic network within language agents by mimicking two fundamental algorithms in connectionist learning: back-propagation and gradient descent. Instead of dealing with numeric weights, agent symbolic learning works with natural language simulacrums of weights, loss, and gradients. We conduct proof-of-concept experiments on both standard benchmarks and complex real-world tasks and show that agent symbolic learning enables language agents to update themselves after being created and deployed in the wild, resulting in "self-evolving agents".
Better Late Than Never: Formulating and Benchmarking Recommendation Editing
Jun 06, 2024



Recommendation systems play a pivotal role in suggesting items to users based on their preferences. However, in online platforms, these systems inevitably offer unsuitable recommendations due to limited model capacity, poor data quality, or evolving user interests. Enhancing user experience necessitates efficiently rectify such unsuitable recommendation behaviors. This paper introduces a novel and significant task termed recommendation editing, which focuses on modifying known and unsuitable recommendation behaviors. Specifically, this task aims to adjust the recommendation model to eliminate known unsuitable items without accessing training data or retraining the model. We formally define the problem of recommendation editing with three primary objectives: strict rectification, collaborative rectification, and concentrated rectification. Three evaluation metrics are developed to quantitatively assess the achievement of each objective. We present a straightforward yet effective benchmark for recommendation editing using novel Editing Bayesian Personalized Ranking Loss. To demonstrate the effectiveness of the proposed method, we establish a comprehensive benchmark that incorporates various methods from related fields. Codebase is available at https://github.com/cycl2018/Recommendation-Editing.
Knowledge Circuits in Pretrained Transformers
May 28, 2024



The remarkable capabilities of modern large language models are rooted in their vast repositories of knowledge encoded within their parameters, enabling them to perceive the world and engage in reasoning. The inner workings of how these models store knowledge have long been a subject of intense interest and investigation among researchers. To date, most studies have concentrated on isolated components within these models, such as the Multilayer Perceptrons and attention head. In this paper, we delve into the computation graph of the language model to uncover the knowledge circuits that are instrumental in articulating specific knowledge. The experiments, conducted with GPT2 and TinyLLAMA, has allowed us to observe how certain information heads, relation heads, and Multilayer Perceptrons collaboratively encode knowledge within the model. Moreover, we evaluate the impact of current knowledge editing techniques on these knowledge circuits, providing deeper insights into the functioning and constraints of these editing methodologies. Finally, we utilize knowledge circuits to analyze and interpret language model behaviors such as hallucinations and in-context learning. We believe the knowledge circuit holds potential for advancing our understanding of Transformers and guiding the improved design of knowledge editing. Code and data are available in https://github.com/zjunlp/KnowledgeCircuits.
Agent Planning with World Knowledge Model
May 23, 2024



Recent endeavors towards directly using large language models (LLMs) as agent models to execute interactive planning tasks have shown commendable results. Despite their achievements, however, they still struggle with brainless trial-and-error in global planning and generating hallucinatory actions in local planning due to their poor understanding of the ''real'' physical world. Imitating humans' mental world knowledge model which provides global prior knowledge before the task and maintains local dynamic knowledge during the task, in this paper, we introduce parametric World Knowledge Model (WKM) to facilitate agent planning. Concretely, we steer the agent model to self-synthesize knowledge from both expert and sampled trajectories. Then we develop WKM, providing prior task knowledge to guide the global planning and dynamic state knowledge to assist the local planning. Experimental results on three complex real-world simulated datasets with three state-of-the-art open-source LLMs, Mistral-7B, Gemma-7B, and Llama-3-8B, demonstrate that our method can achieve superior performance compared to various strong baselines. Besides, we analyze to illustrate that our WKM can effectively alleviate the blind trial-and-error and hallucinatory action issues, providing strong support for the agent's understanding of the world. Other interesting findings include: 1) our instance-level task knowledge can generalize better to unseen tasks, 2) weak WKM can guide strong agent model planning, and 3) unified WKM training has promising potential for further development. Code will be available at https://github.com/zjunlp/WKM.
WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models
May 23, 2024Large language models (LLMs) need knowledge updates to meet the ever-growing world facts and correct the hallucinated responses, facilitating the methods of lifelong model editing. Where the updated knowledge resides in memories is a fundamental question for model editing. In this paper, we find that editing either long-term memory (direct model parameters) or working memory (non-parametric knowledge of neural network activations/representations by retrieval) will result in an impossible triangle -- reliability, generalization, and locality can not be realized together in the lifelong editing settings. For long-term memory, directly editing the parameters will cause conflicts with irrelevant pretrained knowledge or previous edits (poor reliability and locality). For working memory, retrieval-based activations can hardly make the model understand the edits and generalize (poor generalization). Therefore, we propose WISE to bridge the gap between memories. In WISE, we design a dual parametric memory scheme, which consists of the main memory for the pretrained knowledge and a side memory for the edited knowledge. We only edit the knowledge in the side memory and train a router to decide which memory to go through when given a query. For continual editing, we devise a knowledge-sharding mechanism where different sets of edits reside in distinct subspaces of parameters, and are subsequently merged into a shared memory without conflicts. Extensive experiments show that WISE can outperform previous model editing methods and overcome the impossible triangle under lifelong model editing of question answering, hallucination, and out-of-distribution settings across trending LLM architectures, e.g., GPT, LLaMA, and Mistral. Code will be released at https://github.com/zjunlp/EasyEdit.
RaFe: Ranking Feedback Improves Query Rewriting for RAG
May 23, 2024



As Large Language Models (LLMs) and Retrieval Augmentation Generation (RAG) techniques have evolved, query rewriting has been widely incorporated into the RAG system for downstream tasks like open-domain QA. Many works have attempted to utilize small models with reinforcement learning rather than costly LLMs to improve query rewriting. However, current methods require annotations (e.g., labeled relevant documents or downstream answers) or predesigned rewards for feedback, which lack generalization, and fail to utilize signals tailored for query rewriting. In this paper, we propose ours, a framework for training query rewriting models free of annotations. By leveraging a publicly available reranker, ours~provides feedback aligned well with the rewriting objectives. Experimental results demonstrate that ours~can obtain better performance than baselines.