 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM-MCTS: Learning from Reasoning Trajectories with Metacognitive Reflection
Apr 07, 2026PRISM-MCTS: Learning from Reasoning Trajectories with Metacognitive Reflection Siyuan Cheng, Bozhong Tian, Yanchao Hao, Zheng Wei Published: 06 Apr 2026, Last Modified: 06 Apr 2026 ACL 2026 Findings Conference, Area Chairs, Reviewers, Publication Chairs, Authors Revisions BibTeX CC BY 4.0 Keywords: Efficient/Low-Resource Methods for NLP, Generation, Question Answering Abstract: The emergence of reasoning models, exemplified by OpenAI o1, signifies a transition from intuitive to deliberative cognition, effectively reorienting the scaling laws from pre-training paradigms toward test-time computation. While Monte Carlo Tree Search (MCTS) has shown promise in this domain, existing approaches typically treat each rollout as an isolated trajectory. This lack of information sharing leads to severe inefficiency and substantial computational redundancy, as the search process fails to leverage insights from prior explorations. To address these limitations, we propose PRISM-MCTS, a novel reasoning framework that draws inspiration from human parallel thinking and reflective processes. PRISM-MCTS integrates a Process Reward Model (PRM) with a dynamic shared memory, capturing both "Heuristics" and "Fallacies". By reinforcing successful strategies and pruning error-prone branches, PRISM-MCTS effectively achieves refinement. Furthermore, we develop a data-efficient training strategy for the PRM, achieving high-fidelity evaluation under a few-shot regime. Empirical evaluations across diverse reasoning benchmarks substantiate the efficacy of PRISM-MCTS. Notably, it halves the trajectory requirements on GPQA while surpassing MCTS-RAG and Search-o1, demonstrating that it scales inference by reasoning judiciously rather than exhaustively.
ChineseHarm-Bench: A Chinese Harmful Content Detection Benchmark
Jun 12, 2025Large language models (LLMs) have been increasingly applied to automated harmful content detection tasks, assisting moderators in identifying policy violations and improving the overall efficiency and accuracy of content review. However, existing resources for harmful content detection are predominantly focused on English, with Chinese datasets remaining scarce and often limited in scope. We present a comprehensive, professionally annotated benchmark for Chinese content harm detection, which covers six representative categories and is constructed entirely from real-world data. Our annotation process further yields a knowledge rule base that provides explicit expert knowledge to assist LLMs in Chinese harmful content detection. In addition, we propose a knowledge-augmented baseline that integrates both human-annotated knowledge rules and implicit knowledge from large language models, enabling smaller models to achieve performance comparable to state-of-the-art LLMs. Code and data are available at https://github.com/zjunlp/ChineseHarm-bench.
ADS-Edit: A Multimodal Knowledge Editing Dataset for Autonomous Driving Systems
Mar 26, 2025



Recent advancements in Large Multimodal Models (LMMs) have shown promise in Autonomous Driving Systems (ADS). However, their direct application to ADS is hindered by challenges such as misunderstanding of traffic knowledge, complex road conditions, and diverse states of vehicle. To address these challenges, we propose the use of Knowledge Editing, which enables targeted modifications to a model's behavior without the need for full retraining. Meanwhile, we introduce ADS-Edit, a multimodal knowledge editing dataset specifically designed for ADS, which includes various real-world scenarios, multiple data types, and comprehensive evaluation metrics. We conduct comprehensive experiments and derive several interesting conclusions. We hope that our work will contribute to the further advancement of knowledge editing applications in the field of autonomous driving. Code and data are available in https://github.com/zjunlp/EasyEdit.
MLLM can see? Dynamic Correction Decoding for Hallucination Mitigation
Oct 15, 2024



Multimodal Large Language Models (MLLMs) frequently exhibit hallucination phenomena, but the underlying reasons remain poorly understood. In this paper, we present an empirical analysis and find that, although MLLMs incorrectly generate the objects in the final output, they are actually able to recognize visual objects in the preceding layers. We speculate that this may be due to the strong knowledge priors of the language model suppressing the visual information, leading to hallucinations. Motivated by this, we propose a novel dynamic correction decoding method for MLLMs (DeCo), which adaptively selects the appropriate preceding layers and proportionally integrates knowledge into the final layer to adjust the output logits. Note that DeCo is model agnostic and can be seamlessly incorporated with various classic decoding strategies and applied to different MLLMs. We evaluate DeCo on widely-used benchmarks, demonstrating that it can reduce hallucination rates by a large margin compared to baselines, highlighting its potential to mitigate hallucinations. Code is available at https://github.com/zjunlp/DeCo.
OneEdit: A Neural-Symbolic Collaboratively Knowledge Editing System
Sep 09, 2024



Knowledge representation has been a central aim of AI since its inception. Symbolic Knowledge Graphs (KGs) and neural Large Language Models (LLMs) can both represent knowledge. KGs provide highly accurate and explicit knowledge representation, but face scalability issue; while LLMs offer expansive coverage of knowledge, but incur significant training costs and struggle with precise and reliable knowledge manipulation. To this end, we introduce OneEdit, a neural-symbolic prototype system for collaborative knowledge editing using natural language, which facilitates easy-to-use knowledge management with KG and LLM. OneEdit consists of three modules: 1) The Interpreter serves for user interaction with natural language; 2) The Controller manages editing requests from various users, leveraging the KG with rollbacks to handle knowledge conflicts and prevent toxic knowledge attacks; 3) The Editor utilizes the knowledge from the Controller to edit KG and LLM. We conduct experiments on two new datasets with KGs which demonstrate that OneEdit can achieve superior performance.
To Forget or Not? Towards Practical Knowledge Unlearning for Large Language Models
Jul 02, 2024
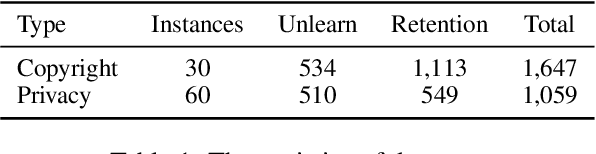
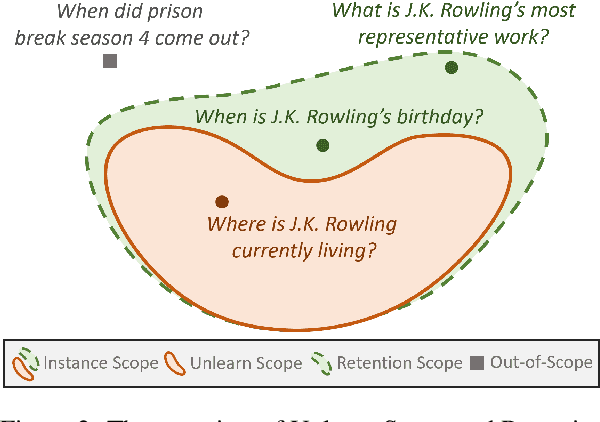
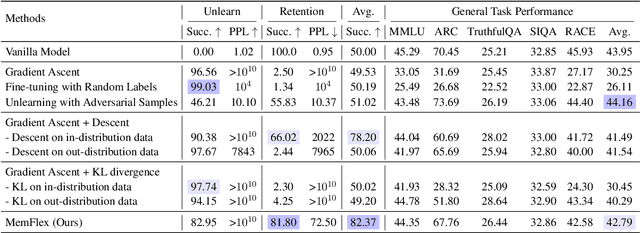
Large Language Models (LLMs) trained on extensive corpora inevitably retain sensitive data, such as personal privacy information and copyrighted material. Recent advancements in knowledge unlearning involve updating LLM parameters to erase specific knowledge. However, current unlearning paradigms are mired in vague forgetting boundaries, often erasing knowledge indiscriminately. In this work, we introduce KnowUnDo, a benchmark containing copyrighted content and user privacy domains to evaluate if the unlearning process inadvertently erases essential knowledge. Our findings indicate that existing unlearning methods often suffer from excessive unlearning. To address this, we propose a simple yet effective method, MemFlex, which utilizes gradient information to precisely target and unlearn sensitive parameters. Experimental results show that MemFlex is superior to existing methods in both precise knowledge unlearning and general knowledge retaining of LLMs. Code and dataset will be released at https://github.com/zjunlp/KnowUnDo.
InstructEdit: Instruction-based Knowledge Editing for Large Language Models
Feb 25, 2024



Knowledge editing for large language models can offer an efficient solution to alter a model's behavior without negatively impacting the overall performance. However, the current approach encounters issues with limited generalizability across tasks, necessitating one distinct editor for each task, which significantly hinders the broader applications. To address this, we take the first step to analyze the multi-task generalization issue in knowledge editing. Specifically, we develop an instruction-based editing technique, termed InstructEdit, which facilitates the editor's adaptation to various task performances simultaneously using simple instructions. With only one unified editor for each LLM, we empirically demonstrate that InstructEdit can improve the editor's control, leading to an average 14.86% increase in Reliability in multi-task editing setting. Furthermore, experiments involving holdout unseen task illustrate that InstructEdit consistently surpass previous strong baselines. To further investigate the underlying mechanisms of instruction-based knowledge editing, we analyze the principal components of the editing gradient directions, which unveils that instructions can help control optimization direction with stronger OOD generalization. Code and datasets will be available in https://github.com/zjunlp/EasyEdit.
MIKE: A New Benchmark for Fine-grained Multimodal Entity Knowledge Editing
Feb 18, 2024



Multimodal knowledge editing represents a critical advancement in enhancing the capabilities of Multimodal Large Language Models (MLLMs). Despite its potential, current benchmarks predominantly focus on coarse-grained knowledge, leaving the intricacies of fine-grained (FG) multimodal entity knowledge largely unexplored. This gap presents a notable challenge, as FG entity recognition is pivotal for the practical deployment and effectiveness of MLLMs in diverse real-world scenarios. To bridge this gap, we introduce MIKE, a comprehensive benchmark and dataset specifically designed for the FG multimodal entity knowledge editing. MIKE encompasses a suite of tasks tailored to assess different perspectives, including Vanilla Name Answering, Entity-Level Caption, and Complex-Scenario Recognition. In addition, a new form of knowledge editing, Multi-step Editing, is introduced to evaluate the editing efficiency. Through our extensive evaluations, we demonstrate that the current state-of-the-art methods face significant challenges in tackling our proposed benchmark, underscoring the complexity of FG knowledge editing in MLLMs. Our findings spotlight the urgent need for novel approaches in this domain, setting a clear agenda for future research and development efforts within the community.
A Comprehensive Study of Knowledge Editing for Large Language Models
Jan 09, 2024



Large Language Models (LLMs) have shown extraordinary capabilities in understanding and generating text that closely mirrors human communication. However, a primary limitation lies in the significant computational demands during training, arising from their extensive parameterization. This challenge is further intensified by the dynamic nature of the world, necessitating frequent updates to LLMs to correct outdated information or integrate new knowledge, thereby ensuring their continued relevance. Note that many applications demand continual model adjustments post-training to address deficiencies or undesirable behaviors. There is an increasing interest in efficient, lightweight methods for on-the-fly model modifications. To this end, recent years have seen a burgeoning in the techniques of knowledge editing for LLMs, which aim to efficiently modify LLMs' behaviors within specific domains while preserving overall performance across various inputs. In this paper, we first define the knowledge editing problem and then provide a comprehensive review of cutting-edge approaches. Drawing inspiration from educational and cognitive research theories, we propose a unified categorization criterion that classifies knowledge editing methods into three groups: resorting to external knowledge, merging knowledge into the model, and editing intrinsic knowledge. Furthermore, we introduce a new benchmark, KnowEdit, for a comprehensive empirical evaluation of representative knowledge editing approaches. Additionally, we provide an in-depth analysis of knowledge location, which can give a deeper understanding of the knowledge structures inherent within LLMs. Finally, we discuss several potential applications of knowledge editing, outlining its broad and impactful implications.
Can We Edit Multimodal Large Language Models?
Oct 13, 2023



In this paper, we focus on editing Multimodal Large Language Models (MLLMs). Compared to editing single-modal LLMs, multimodal model editing is more challenging, which demands a higher level of scrutiny and careful consideration in the editing process. To facilitate research in this area, we construct a new benchmark, dubbed MMEdit, for editing multimodal LLMs and establishing a suite of innovative metrics for evaluation. We conduct comprehensive experiments involving various model editing baselines and analyze the impact of editing different components for multimodal LLMs. Empirically, we notice that previous baselines can implement editing multimodal LLMs to some extent, but the effect is still barely satisfactory, indicating the potential difficulty of this task. We hope that our work can provide the NLP community with insights. Code and dataset are available in https://github.com/zjunlp/EasyEdit.