 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Autonomous Agentic Data Engineering for Model Specialization
May 28, 2026Large Language Models (LLMs) have demonstrated strong performance on general tasks, while often struggling to adapt to specialized domains without high-quality domain-specific data. Existing LLM-based data curation methods primarily rely on human-designed workflows, leaving it unexamined whether LLMs can autonomously execute an end-to-end data engineering pipeline for model specialization. We formalize \textbf{Autonomous Agentic Data Engineering}, a novel task designed to evaluate LLMs as autonomous data engineers that drive model specialization through end-to-end data curation. We frame data as an optimizable component and study agents that plan, generate, and iteratively optimize training data across multiple domains, guided by post-training performance improvement. Experiments show that autonomous LLM data engineers yield substantial gains, as GPT-5.2 constructs a training curriculum that improves a student model by \textbf{57.29\%}, entirely through iterative, agent-driven data adaptation. By illuminating both potential and bottlenecks, our study establishes autonomous data engineering as a measurable capability and charts a path toward agent-driven model specialization\footnote{Code will be released at https://github.com/zjunlp/DataAgent.}.
Rewarding the Scientific Process: Process-Level Reward Modeling for Agentic Data Analysis
Apr 27, 2026Process Reward Models (PRMs) have achieved remarkable success in augmenting the reasoning capabilities of Large Language Models (LLMs) within static domains such as mathematics. However, their potential in dynamic data analysis tasks remains underexplored. In this work, we first present a empirical study revealing that general-domain PRMs struggle to supervise data analysis agents. Specifically, they fail to detect silent errors, logical flaws that yield incorrect results without triggering interpreter exceptions, and erroneously penalize exploratory actions, mistaking necessary trial-and-error exploration for grounding failures. To bridge this gap, we introduce DataPRM, a novel environment-aware generative process reward model that (1) can serve as an active verifier, autonomously interacting with the environment to probe intermediate execution states and uncover silent errors, and (2) employs a reflection-aware ternary reward strategy that distinguishes between correctable grounding errors and irrecoverable mistakes. We design a scalable pipeline to construct over 8K high-quality training instances for DataPRM via diversity-driven trajectory generation and knowledge-augmented step-level annotation. Experimental results demonstrate that DataPRM improves downstream policy LLMs by 7.21% on ScienceAgentBench and 11.28% on DABStep using Best-of-N inference. Notably, with only 4B parameters, DataPRM outperforms strong baselines, and exhibits robust generalizability across diverse Test-Time Scaling strategies. Furthermore, integrating DataPRM into Reinforcement Learning yields substantial gains over outcome-reward baselines, achieving 78.73% on DABench and 64.84% on TableBench, validating the effectiveness of process reward supervision. Code is available at https://github.com/zjunlp/DataMind.
StructMem: Structured Memory for Long-Horizon Behavior in LLMs
Apr 23, 2026Long-term conversational agents need memory systems that capture relationships between events, not merely isolated facts, to support temporal reasoning and multi-hop question answering. Current approaches face a fundamental trade-off: flat memory is efficient but fails to model relational structure, while graph-based memory enables structured reasoning at the cost of expensive and fragile construction. To address these issues, we propose \textbf{StructMem}, a structure-enriched hierarchical memory framework that preserves event-level bindings and induces cross-event connections. By temporally anchoring dual perspectives and performing periodic semantic consolidation, StructMem improves temporal reasoning and multi-hop performance on \texttt{LoCoMo}, while substantially reducing token usage, API calls, and runtime compared to prior memory systems, see https://github.com/zjunlp/LightMem .
LightThinker++: From Reasoning Compression to Memory Management
Apr 04, 2026Large language models (LLMs) excel at complex reasoning, yet their efficiency is limited by the surging cognitive overhead of long thought traces. In this paper, we propose LightThinker, a method that enables LLMs to dynamically compress intermediate thoughts into compact semantic representations. However, static compression often struggles with complex reasoning where the irreversible loss of intermediate details can lead to logical bottlenecks. To address this, we evolve the framework into LightThinker++, introducing Explicit Adaptive Memory Management. This paradigm shifts to behavioral-level management by incorporating explicit memory primitives, supported by a specialized trajectory synthesis pipeline to train purposeful memory scheduling. Extensive experiments demonstrate the framework's versatility across three dimensions. (1) LightThinker reduces peak token usage by 70% and inference time by 26% with minimal accuracy loss. (2) In standard reasoning, LightThinker++ slashes peak token usage by 69.9% while yielding a +2.42% accuracy gain under the same context budget for maximum performance. (3) Most notably, in long-horizon agentic tasks, it maintains a stable footprint beyond 80 rounds (a 60%-70% reduction), achieving an average performance gain of 14.8% across different complex scenarios. Overall, our work provides a scalable direction for sustaining deep LLM reasoning over extended horizons with minimal overhead.
OceanGym: A Benchmark Environment for Underwater Embodied Agents
Sep 30, 2025We introduce OceanGym, the first comprehensive benchmark for ocean underwater embodied agents, designed to advance AI in one of the most demanding real-world environments. Unlike terrestrial or aerial domains, underwater settings present extreme perceptual and decision-making challenges, including low visibility, dynamic ocean currents, making effective agent deployment exceptionally difficult. OceanGym encompasses eight realistic task domains and a unified agent framework driven by Multi-modal Large Language Models (MLLMs), which integrates perception, memory, and sequential decision-making. Agents are required to comprehend optical and sonar data, autonomously explore complex environments, and accomplish long-horizon objectives under these harsh conditions. Extensive experiments reveal substantial gaps between state-of-the-art MLLM-driven agents and human experts, highlighting the persistent difficulty of perception, planning, and adaptability in ocean underwater environments. By providing a high-fidelity, rigorously designed platform, OceanGym establishes a testbed for developing robust embodied AI and transferring these capabilities to real-world autonomous ocean underwater vehicles, marking a decisive step toward intelligent agents capable of operating in one of Earth's last unexplored frontiers. The code and data are available at https://github.com/OceanGPT/OceanGym.
Why Do Open-Source LLMs Struggle with Data Analysis? A Systematic Empirical Study
Jun 24, 2025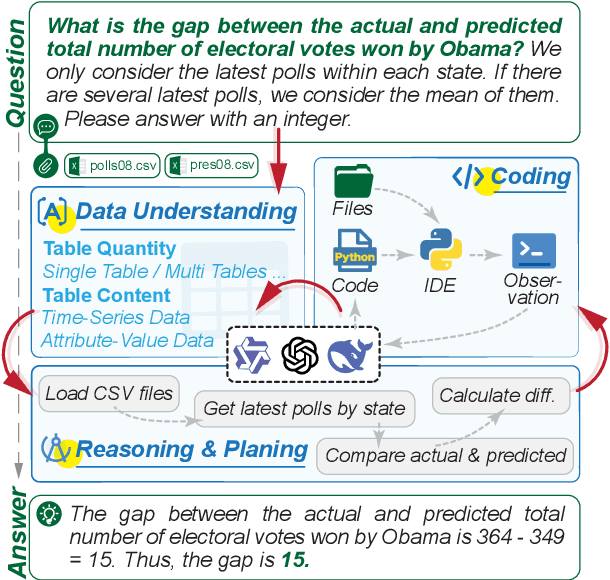
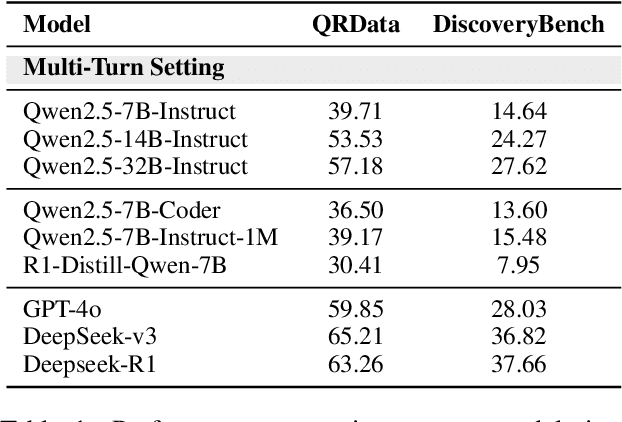
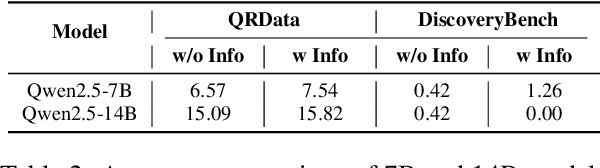
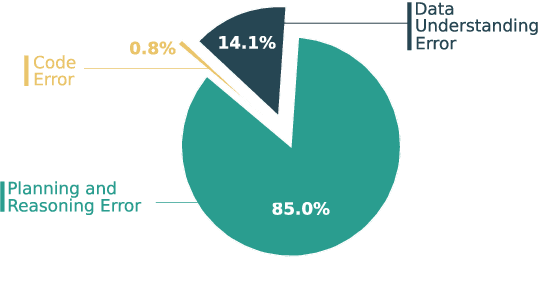
Large Language Models (LLMs) hold promise in automating data analysis tasks, yet open-source models face significant limitations in these kinds of reasoning-intensive scenarios. In this work, we investigate strategies to enhance the data analysis capabilities of open-source LLMs. By curating a seed dataset of diverse, realistic scenarios, we evaluate models across three dimensions: data understanding, code generation, and strategic planning. Our analysis reveals three key findings: (1) Strategic planning quality serves as the primary determinant of model performance; (2) Interaction design and task complexity significantly influence reasoning capabilities; (3) Data quality demonstrates a greater impact than diversity in achieving optimal performance. We leverage these insights to develop a data synthesis methodology, demonstrating significant improvements in open-source LLMs' analytical reasoning capabilities.
Knowledge Augmented Complex Problem Solving with Large Language Models: A Survey
May 06, 2025



Problem-solving has been a fundamental driver of human progress in numerous domains. With advancements in artificial intelligence, Large Language Models (LLMs) have emerged as powerful tools capable of tackling complex problems across diverse domains. Unlike traditional computational systems, LLMs combine raw computational power with an approximation of human reasoning, allowing them to generate solutions, make inferences, and even leverage external computational tools. However, applying LLMs to real-world problem-solving presents significant challenges, including multi-step reasoning, domain knowledge integration, and result verification. This survey explores the capabilities and limitations of LLMs in complex problem-solving, examining techniques including Chain-of-Thought (CoT) reasoning, knowledge augmentation, and various LLM-based and tool-based verification techniques. Additionally, we highlight domain-specific challenges in various domains, such as software engineering, mathematical reasoning and proving, data analysis and modeling, and scientific research. The paper further discusses the fundamental limitations of the current LLM solutions and the future directions of LLM-based complex problems solving from the perspective of multi-step reasoning, domain knowledge integration and result verification.
LightThinker: Thinking Step-by-Step Compression
Feb 21, 2025Large language models (LLMs) have shown remarkable performance in complex reasoning tasks, but their efficiency is hindered by the substantial memory and computational costs associated with generating lengthy tokens. In this paper, we propose LightThinker, a novel method that enables LLMs to dynamically compress intermediate thoughts during reasoning. Inspired by human cognitive processes, LightThinker compresses verbose thought steps into compact representations and discards the original reasoning chains, thereby significantly reducing the number of tokens stored in the context window. This is achieved by training the model on when and how to perform compression through data construction, mapping hidden states to condensed gist tokens, and creating specialized attention masks. Additionally, we introduce the Dependency (Dep) metric to quantify the degree of compression by measuring the reliance on historical tokens during generation. Extensive experiments on four datasets and two models show that LightThinker reduces peak memory usage and inference time, while maintaining competitive accuracy. Our work provides a new direction for improving the efficiency of LLMs in complex reasoning tasks without sacrificing performance. Code will be released at https://github.com/zjunlp/LightThinker.
Bias in Decision-Making for AI's Ethical Dilemmas: A Comparative Study of ChatGPT and Claude
Jan 17, 2025



Recent advances in Large Language Models (LLMs) have enabled human-like responses across various tasks, raising questions about their ethical decision-making capabilities and potential biases. This study investigates protected attributes in LLMs through systematic evaluation of their responses to ethical dilemmas. Using two prominent models - GPT-3.5 Turbo and Claude 3.5 Sonnet - we analyzed their decision-making patterns across multiple protected attributes including age, gender, race, appearance, and disability status. Through 11,200 experimental trials involving both single-factor and two-factor protected attribute combinations, we evaluated the models' ethical preferences, sensitivity, stability, and clustering of preferences. Our findings reveal significant protected attributeses in both models, with consistent preferences for certain features (e.g., "good-looking") and systematic neglect of others. Notably, while GPT-3.5 Turbo showed stronger preferences aligned with traditional power structures, Claude 3.5 Sonnet demonstrated more diverse protected attribute choices. We also found that ethical sensitivity significantly decreases in more complex scenarios involving multiple protected attributes. Additionally, linguistic referents heavily influence the models' ethical evaluations, as demonstrated by differing responses to racial descriptors (e.g., "Yellow" versus "Asian"). These findings highlight critical concerns about the potential impact of LLM biases in autonomous decision-making systems and emphasize the need for careful consideration of protected attributes in AI development. Our study contributes to the growing body of research on AI ethics by providing a systematic framework for evaluating protected attributes in LLMs' ethical decision-making capabilities.
Consistency of Responses and Continuations Generated by Large Language Models on Social Media
Jan 15, 2025



Large Language Models (LLMs) demonstrate remarkable capabilities in text generation, yet their emotional consistency and semantic coherence in social media contexts remain insufficiently understood. This study investigates how LLMs handle emotional content and maintain semantic relationships through continuation and response tasks using two open-source models: Gemma and Llama. By analyzing climate change discussions from Twitter and Reddit, we examine emotional transitions, intensity patterns, and semantic similarity between human-authored and LLM-generated content. Our findings reveal that while both models maintain high semantic coherence, they exhibit distinct emotional patterns: Gemma shows a tendency toward negative emotion amplification, particularly anger, while maintaining certain positive emotions like optimism. Llama demonstrates superior emotional preservation across a broader spectrum of affects. Both models systematically generate responses with attenuated emotional intensity compared to human-authored content and show a bias toward positive emotions in response tasks. Additionally, both models maintain strong semantic similarity with original texts, though performance varies between continuation and response tasks. These findings provide insights into LLMs' emotional and semantic processing capabilities, with implications for their deployment in social media contexts and human-AI interaction design.