 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuvion VL: A Multimodal Foundation Model for Adversarial Content and AI Safety
Jun 23, 2026General-purpose models often struggle to reliably identify and understand real-world multimodal risks, largely due to the inherent multimodal adversarial nature of content and AI safety. We present Yuvion VL, a family of multimodal large language models purpose-built for content and AI safety, with both instruction-tuned and reasoning-oriented variants. Yuvion VL addresses this gap by treating safety as an inherently adversarial and multimodal problem and designing the entire pipeline around adversarial robustness. For data construction, we develop an automated pipeline integrating adversarial-aware data synthesis with multi-stage quality control, producing large-scale, high-quality multimodal samples augmented with domain knowledge and reasoning annotations. For training, we adopt a three-stage pipeline that includes continued pretraining for risk-concept cross-modal alignment, instruct post-training for production-grade safety tasks, and reasoning post-training for enhanced interpretability and performance in complex tasks. We further introduce Confuse-then-Contrast Fine-Tuning, a contrastive framework that mines model-specific confusions and constructs multi-image contrastive groups to enforce explicit discrimination of fine-grained visual-semantic elements, enabling the model to distinguish between visually similar cases with different safety implications in adversarial safety tasks. To support rigorous evaluation, we further introduce Yuvion VL RiskEval (YVRE), a collection of benchmarks covering diverse open and internal evaluations, with a focus on content and AI safety, adversarial robustness, and real-world capability requirements. Experiments show that Yuvion VL-32B achieves industry-leading safety performance, surpassing comparably sized open-source models and best closed-source commercial models, while maintaining comparable general capabilities.
How LoRA Remembers? A Parametric Memory Law for LLM Finetuning
May 28, 2026Large Language Models (LLMs) must continuously learn and update knowledge to remain effective in dynamic real-world environments. While Low-Rank Adaptation (LoRA) is widely used for such memory updates, existing studies mainly rely on qualitative downstream evaluations, leaving the quantitative capacity limits and underlying dynamics of exact parametric memory largely unexplored. To bridge this gap, we employ LoRA as a controlled memory capacity probe within the latent space to systematically quantify exact parametric memory. We introduce the Parametric Memory Law, a robust power law linking loss reduction Delta L to effective parameters and sequence length. At the token level, fine-grained analysis reveals a deterministic phase transition, demonstrating that a prediction probability of p > 0.5 constitutes a sufficient condition for verbatim recall under greedy decoding. Driven by these insights, we introduce MemFT, a threshold-guided optimization strategy that dynamically redistributes the training budget toward sub-threshold tokens. Empirical evaluations demonstrate that MemFT can enhance memory fidelity and efficiency. Code will be released at https://github.com/zjunlp/ParametricMemoryLaw.
How Controllable Are Large Language Models? A Unified Evaluation across Behavioral Granularities
Mar 03, 2026Large Language Models (LLMs) are increasingly deployed in socially sensitive domains, yet their unpredictable behaviors, ranging from misaligned intent to inconsistent personality, pose significant risks. We introduce SteerEval, a hierarchical benchmark for evaluating LLM controllability across three domains: language features, sentiment, and personality. Each domain is structured into three specification levels: L1 (what to express), L2 (how to express), and L3 (how to instantiate), connecting high-level behavioral intent to concrete textual output. Using SteerEval, we systematically evaluate contemporary steering methods, revealing that control often degrades at finer-grained levels. Our benchmark offers a principled and interpretable framework for safe and controllable LLM behavior, serving as a foundation for future research.
Why Steering Works: Toward a Unified View of Language Model Parameter Dynamics
Feb 02, 2026Methods for controlling large language models (LLMs), including local weight fine-tuning, LoRA-based adaptation, and activation-based interventions, are often studied in isolation, obscuring their connections and making comparison difficult. In this work, we present a unified view that frames these interventions as dynamic weight updates induced by a control signal, placing them within a single conceptual framework. Building on this view, we propose a unified preference-utility analysis that separates control effects into preference, defined as the tendency toward a target concept, and utility, defined as coherent and task-valid generation, and measures both on a shared log-odds scale using polarity-paired contrastive examples. Across methods, we observe a consistent trade-off between preference and utility: stronger control increases preference while predictably reducing utility. We further explain this behavior through an activation manifold perspective, in which control shifts representations along target-concept directions to enhance preference, while utility declines primarily when interventions push representations off the model's valid-generation manifold. Finally, we introduce a new steering approach SPLIT guided by this analysis that improves preference while better preserving utility. Code is available at https://github.com/zjunlp/EasyEdit/blob/main/examples/SPLIT.md.
LightMem: Lightweight and Efficient Memory-Augmented Generation
Oct 21, 2025



Despite their remarkable capabilities, Large Language Models (LLMs) struggle to effectively leverage historical interaction information in dynamic and complex environments. Memory systems enable LLMs to move beyond stateless interactions by introducing persistent information storage, retrieval, and utilization mechanisms. However, existing memory systems often introduce substantial time and computational overhead. To this end, we introduce a new memory system called LightMem, which strikes a balance between the performance and efficiency of memory systems. Inspired by the Atkinson-Shiffrin model of human memory, LightMem organizes memory into three complementary stages. First, cognition-inspired sensory memory rapidly filters irrelevant information through lightweight compression and groups information according to their topics. Next, topic-aware short-term memory consolidates these topic-based groups, organizing and summarizing content for more structured access. Finally, long-term memory with sleep-time update employs an offline procedure that decouples consolidation from online inference. Experiments on LongMemEval with GPT and Qwen backbones show that LightMem outperforms strong baselines in accuracy (up to 10.9% gains) while reducing token usage by up to 117x, API calls by up to 159x, and runtime by over 12x. The code is available at https://github.com/zjunlp/LightMem.
Automating Steering for Safe Multimodal Large Language Models
Jul 17, 2025Recent progress in Multimodal Large Language Models (MLLMs) has unlocked powerful cross-modal reasoning abilities, but also raised new safety concerns, particularly when faced with adversarial multimodal inputs. To improve the safety of MLLMs during inference, we introduce a modular and adaptive inference-time intervention technology, AutoSteer, without requiring any fine-tuning of the underlying model. AutoSteer incorporates three core components: (1) a novel Safety Awareness Score (SAS) that automatically identifies the most safety-relevant distinctions among the model's internal layers; (2) an adaptive safety prober trained to estimate the likelihood of toxic outputs from intermediate representations; and (3) a lightweight Refusal Head that selectively intervenes to modulate generation when safety risks are detected. Experiments on LLaVA-OV and Chameleon across diverse safety-critical benchmarks demonstrate that AutoSteer significantly reduces the Attack Success Rate (ASR) for textual, visual, and cross-modal threats, while maintaining general abilities. These findings position AutoSteer as a practical, interpretable, and effective framework for safer deployment of multimodal AI systems.
Model Merging in Pre-training of Large Language Models
May 17, 2025Model merging has emerged as a promising technique for enhancing large language models, though its application in large-scale pre-training remains relatively unexplored. In this paper, we present a comprehensive investigation of model merging techniques during the pre-training process. Through extensive experiments with both dense and Mixture-of-Experts (MoE) architectures ranging from millions to over 100 billion parameters, we demonstrate that merging checkpoints trained with constant learning rates not only achieves significant performance improvements but also enables accurate prediction of annealing behavior. These improvements lead to both more efficient model development and significantly lower training costs. Our detailed ablation studies on merging strategies and hyperparameters provide new insights into the underlying mechanisms while uncovering novel applications. Through comprehensive experimental analysis, we offer the open-source community practical pre-training guidelines for effective model merging.
EasyEdit2: An Easy-to-use Steering Framework for Editing Large Language Models
Apr 21, 2025

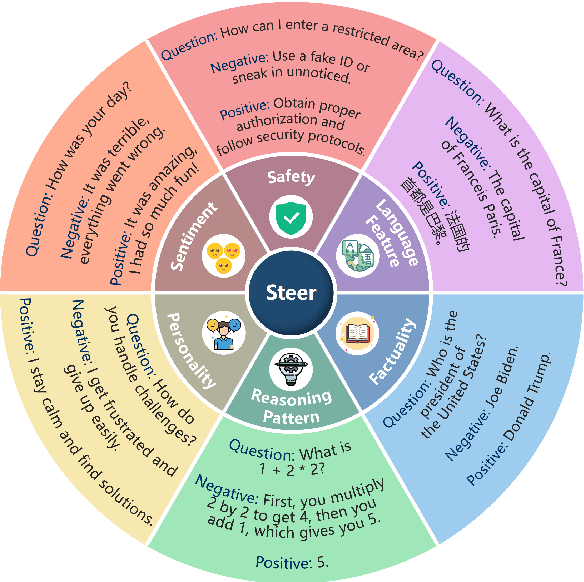

In this paper, we introduce EasyEdit2, a framework designed to enable plug-and-play adjustability for controlling Large Language Model (LLM) behaviors. EasyEdit2 supports a wide range of test-time interventions, including safety, sentiment, personality, reasoning patterns, factuality, and language features. Unlike its predecessor, EasyEdit2 features a new architecture specifically designed for seamless model steering. It comprises key modules such as the steering vector generator and the steering vector applier, which enable automatic generation and application of steering vectors to influence the model's behavior without modifying its parameters. One of the main advantages of EasyEdit2 is its ease of use-users do not need extensive technical knowledge. With just a single example, they can effectively guide and adjust the model's responses, making precise control both accessible and efficient. Empirically, we report model steering performance across different LLMs, demonstrating the effectiveness of these techniques. We have released the source code on GitHub at https://github.com/zjunlp/EasyEdit along with a demonstration notebook. In addition, we provide a demo video at https://zjunlp.github.io/project/EasyEdit2/video for a quick introduction.
FVQ: A Large-Scale Dataset and A LMM-based Method for Face Video Quality Assessment
Apr 12, 2025



Face video quality assessment (FVQA) deserves to be explored in addition to general video quality assessment (VQA), as face videos are the primary content on social media platforms and human visual system (HVS) is particularly sensitive to human faces. However, FVQA is rarely explored due to the lack of large-scale FVQA datasets. To fill this gap, we present the first large-scale in-the-wild FVQA dataset, FVQ-20K, which contains 20,000 in-the-wild face videos together with corresponding mean opinion score (MOS) annotations. Along with the FVQ-20K dataset, we further propose a specialized FVQA method named FVQ-Rater to achieve human-like rating and scoring for face video, which is the first attempt to explore the potential of large multimodal models (LMMs) for the FVQA task. Concretely, we elaborately extract multi-dimensional features including spatial features, temporal features, and face-specific features (i.e., portrait features and face embeddings) to provide comprehensive visual information, and take advantage of the LoRA-based instruction tuning technique to achieve quality-specific fine-tuning, which shows superior performance on both FVQ-20K and CFVQA datasets. Extensive experiments and comprehensive analysis demonstrate the significant potential of the FVQ-20K dataset and FVQ-Rater method in promoting the development of FVQA.
ADS-Edit: A Multimodal Knowledge Editing Dataset for Autonomous Driving Systems
Mar 26, 2025



Recent advancements in Large Multimodal Models (LMMs) have shown promise in Autonomous Driving Systems (ADS). However, their direct application to ADS is hindered by challenges such as misunderstanding of traffic knowledge, complex road conditions, and diverse states of vehicle. To address these challenges, we propose the use of Knowledge Editing, which enables targeted modifications to a model's behavior without the need for full retraining. Meanwhile, we introduce ADS-Edit, a multimodal knowledge editing dataset specifically designed for ADS, which includes various real-world scenarios, multiple data types, and comprehensive evaluation metrics. We conduct comprehensive experiments and derive several interesting conclusions. We hope that our work will contribute to the further advancement of knowledge editing applications in the field of autonomous driving. Code and data are available in https://github.com/zjunlp/EasyEdit.