 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Confidence: The Rhythms of Reasoning in Generative Models
Feb 11, 2026Large Language Models (LLMs) exhibit impressive capabilities yet suffer from sensitivity to slight input context variations, hampering reliability. Conventional metrics like accuracy and perplexity fail to assess local prediction robustness, as normalized output probabilities can obscure the underlying resilience of an LLM's internal state to perturbations. We introduce the Token Constraint Bound ($δ_{\mathrm{TCB}}$), a novel metric that quantifies the maximum internal state perturbation an LLM can withstand before its dominant next-token prediction significantly changes. Intrinsically linked to output embedding space geometry, $δ_{\mathrm{TCB}}$ provides insights into the stability of the model's internal predictive commitment. Our experiments show $δ_{\mathrm{TCB}}$ correlates with effective prompt engineering and uncovers critical prediction instabilities missed by perplexity during in-context learning and text generation. $δ_{\mathrm{TCB}}$ offers a principled, complementary approach to analyze and potentially improve the contextual stability of LLM predictions.
Gradients Must Earn Their Influence: Unifying SFT with Generalized Entropic Objectives
Feb 11, 2026Standard negative log-likelihood (NLL) for Supervised Fine-Tuning (SFT) applies uniform token-level weighting. This rigidity creates a two-fold failure mode: (i) overemphasizing low-probability targets can amplify gradients on noisy supervision and disrupt robust priors, and (ii) uniform weighting provides weak sharpening when the model is already confident. Existing methods fail to resolve the resulting plasticity--stability dilemma, often suppressing necessary learning signals alongside harmful ones. To address this issue, we unify token-level SFT objectives within a generalized deformed-log family and expose a universal gate $\times$ error gradient structure, where the gate controls how much the model trusts its current prediction. By employing the Cayley transform, we map the model's continuously evolving uncertainty onto a continuous focus trajectory, which enables seamless interpolation between scenarios involving uncertain novel concepts and those involving well-established knowledge. We then introduce Dynamic Entropy Fine-Tuning (DEFT), a parameter-free objective that modulates the trust gate using distribution concentration (Rényi-2 entropy) as a practical proxy for the model's predictive state. Extensive experiments and analyses demonstrate that DEFT achieves a better balance between exploration and exploitation, leading to improved overall performance.
EchoReview: Learning Peer Review from the Echoes of Scientific Citations
Jan 31, 2026As the volume of scientific submissions continues to grow rapidly, traditional peer review systems are facing unprecedented scalability pressures, highlighting the urgent need for automated reviewing methods that are both scalable and reliable. Existing supervised fine-tuning approaches based on real review data are fundamentally constrained by single-source of data as well as the inherent subjectivity and inconsistency of human reviews, limiting their ability to support high-quality automated reviewers. To address these issues, we propose EchoReview, a citation-context-driven data synthesis framework that systematically mines implicit collective evaluative signals from academic citations and transforms scientific community's long-term judgments into structured review-style data. Based on this pipeline, we construct EchoReview-16K, the first large-scale, cross-conference, and cross-year citation-driven review dataset, and train an automated reviewer, EchoReviewer-7B. Experimental results demonstrate that EchoReviewer-7B can achieve significant and stable improvements on core review dimensions such as evidence support and review comprehensiveness, validating citation context as a robust and effective data paradigm for reliable automated peer review.
ScEdit: Script-based Assessment of Knowledge Editing
May 29, 2025Knowledge Editing (KE) has gained increasing attention, yet current KE tasks remain relatively simple. Under current evaluation frameworks, many editing methods achieve exceptionally high scores, sometimes nearing perfection. However, few studies integrate KE into real-world application scenarios (e.g., recent interest in LLM-as-agent). To support our analysis, we introduce a novel script-based benchmark -- ScEdit (Script-based Knowledge Editing Benchmark) -- which encompasses both counterfactual and temporal edits. We integrate token-level and text-level evaluation methods, comprehensively analyzing existing KE techniques. The benchmark extends traditional fact-based ("What"-type question) evaluation to action-based ("How"-type question) evaluation. We observe that all KE methods exhibit a drop in performance on established metrics and face challenges on text-level metrics, indicating a challenging task. Our benchmark is available at https://github.com/asdfo123/ScEdit.
Surrogate Signals from Format and Length: Reinforcement Learning for Solving Mathematical Problems without Ground Truth Answers
May 26, 2025Large Language Models have achieved remarkable success in natural language processing tasks, with Reinforcement Learning playing a key role in adapting them to specific applications. However, obtaining ground truth answers for training LLMs in mathematical problem-solving is often challenging, costly, and sometimes unfeasible. This research delves into the utilization of format and length as surrogate signals to train LLMs for mathematical problem-solving, bypassing the need for traditional ground truth answers.Our study shows that a reward function centered on format correctness alone can yield performance improvements comparable to the standard GRPO algorithm in early phases. Recognizing the limitations of format-only rewards in the later phases, we incorporate length-based rewards. The resulting GRPO approach, leveraging format-length surrogate signals, not only matches but surpasses the performance of the standard GRPO algorithm relying on ground truth answers in certain scenarios, achieving 40.0\% accuracy on AIME2024 with a 7B base model. Through systematic exploration and experimentation, this research not only offers a practical solution for training LLMs to solve mathematical problems and reducing the dependence on extensive ground truth data collection, but also reveals the essence of why our label-free approach succeeds: base model is like an excellent student who has already mastered mathematical and logical reasoning skills, but performs poorly on the test paper, it simply needs to develop good answering habits to achieve outstanding results in exams , in other words, to unlock the capabilities it already possesses.
Large Language Models for Planning: A Comprehensive and Systematic Survey
May 26, 2025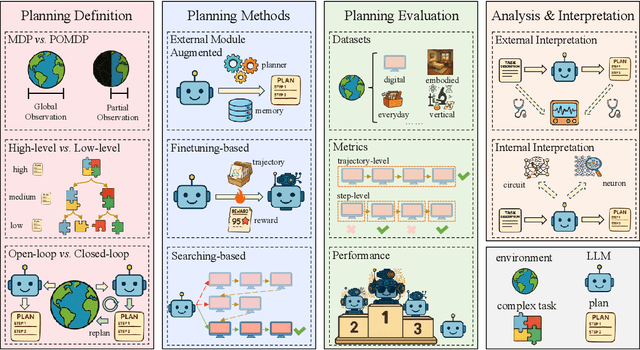
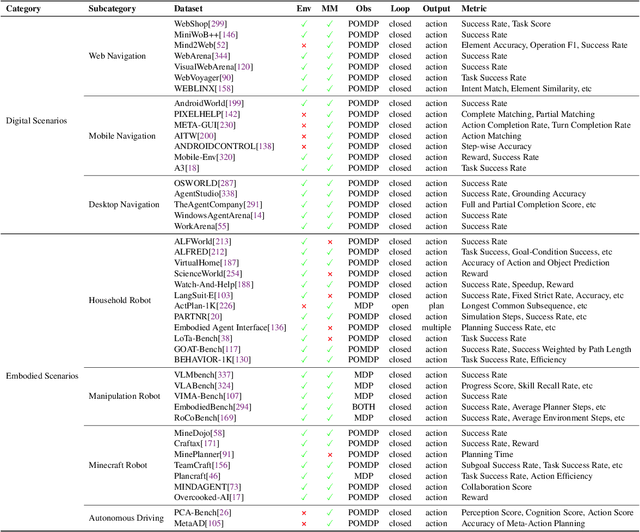
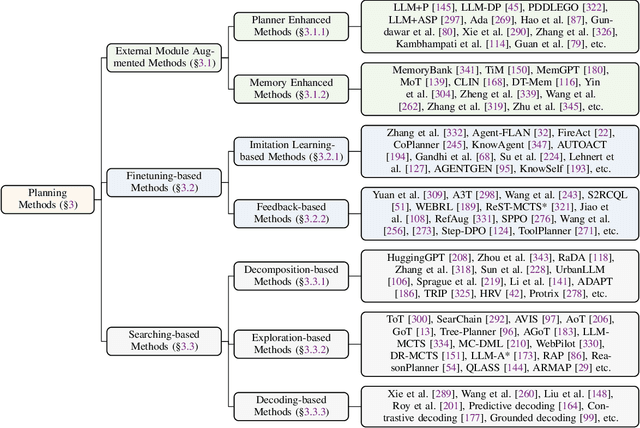
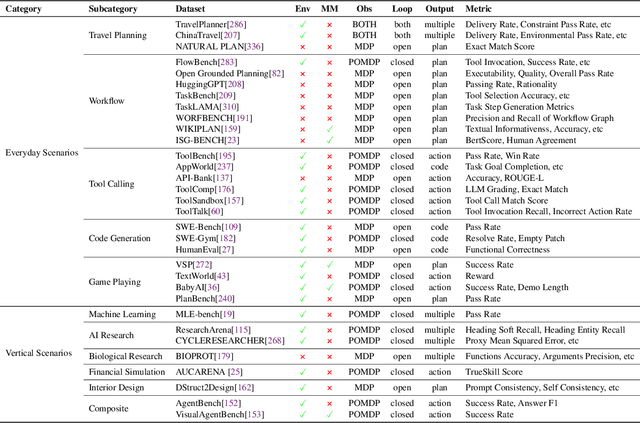
Planning represents a fundamental capability of intelligent agents, requiring comprehensive environmental understanding, rigorous logical reasoning, and effective sequential decision-making. While Large Language Models (LLMs) have demonstrated remarkable performance on certain planning tasks, their broader application in this domain warrants systematic investigation. This paper presents a comprehensive review of LLM-based planning. Specifically, this survey is structured as follows: First, we establish the theoretical foundations by introducing essential definitions and categories about automated planning. Next, we provide a detailed taxonomy and analysis of contemporary LLM-based planning methodologies, categorizing them into three principal approaches: 1) External Module Augmented Methods that combine LLMs with additional components for planning, 2) Finetuning-based Methods that involve using trajectory data and feedback signals to adjust LLMs in order to improve their planning abilities, and 3) Searching-based Methods that break down complex tasks into simpler components, navigate the planning space, or enhance decoding strategies to find the best solutions. Subsequently, we systematically summarize existing evaluation frameworks, including benchmark datasets, evaluation metrics and performance comparisons between representative planning methods. Finally, we discuss the underlying mechanisms enabling LLM-based planning and outline promising research directions for this rapidly evolving field. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this field.
LFTF: Locating First and Then Fine-Tuning for Mitigating Gender Bias in Large Language Models
May 21, 2025Nowadays, Large Language Models (LLMs) have attracted widespread attention due to their powerful performance. However, due to the unavoidable exposure to socially biased data during training, LLMs tend to exhibit social biases, particularly gender bias. To better explore and quantifying the degree of gender bias in LLMs, we propose a pair of datasets named GenBiasEval and GenHintEval, respectively. The GenBiasEval is responsible for evaluating the degree of gender bias in LLMs, accompanied by an evaluation metric named AFGB-Score (Absolutely Fair Gender Bias Score). Meanwhile, the GenHintEval is used to assess whether LLMs can provide responses consistent with prompts that contain gender hints, along with the accompanying evaluation metric UB-Score (UnBias Score). Besides, in order to mitigate gender bias in LLMs more effectively, we present the LFTF (Locating First and Then Fine-Tuning) algorithm.The algorithm first ranks specific LLM blocks by their relevance to gender bias in descending order using a metric called BMI (Block Mitigating Importance Score). Based on this ranking, the block most strongly associated with gender bias is then fine-tuned using a carefully designed loss function. Numerous experiments have shown that our proposed LFTF algorithm can significantly mitigate gender bias in LLMs while maintaining their general capabilities.
LLMSR@XLLM25: An Empirical Study of LLM for Structural Reasoning
May 18, 2025We present Team asdfo123's submission to the LLMSR@XLLM25 shared task, which evaluates large language models on producing fine-grained, controllable, and interpretable reasoning processes. Systems must extract all problem conditions, decompose a chain of thought into statement-evidence pairs, and verify the logical validity of each pair. Leveraging only the off-the-shelf Meta-Llama-3-8B-Instruct, we craft a concise few-shot, multi-turn prompt that first enumerates all conditions and then guides the model to label, cite, and adjudicate every reasoning step. A lightweight post-processor based on regular expressions normalises spans and enforces the official JSON schema. Without fine-tuning, external retrieval, or ensembling, our method ranks 5th overall, achieving macro F1 scores on par with substantially more complex and resource-consuming pipelines. We conclude by analysing the strengths and limitations of our approach and outlining directions for future research in structural reasoning with LLMs. Our code is available at https://github.com/asdfo123/LLMSR-asdfo123.
TMGBench: A Systematic Game Benchmark for Evaluating Strategic Reasoning Abilities of LLMs
Oct 14, 2024



The rapid advancement of large language models (LLMs) has accelerated their application in reasoning, with strategic reasoning drawing increasing attention. To evaluate LLMs' strategic reasoning capabilities, game theory, with its concise structure, has become a preferred approach. However, current research focuses on a limited selection of games, resulting in low coverage. Classic game scenarios risk data leakage, and existing benchmarks often lack extensibility, making them inadequate for evaluating state-of-the-art models. To address these challenges, we propose TMGBench, a benchmark with comprehensive game type coverage, novel scenarios, and flexible organization. Specifically, we incorporate all 144 game types summarized by the Robinson-Goforth topology of 2x2 games, constructed as classic games. We also employ synthetic data generation to create diverse, higher-quality scenarios through topic guidance and human inspection, referred to as story-based games. Lastly, we provide a sustainable framework for increasingly powerful LLMs by treating these games as atomic units and organizing them into more complex forms via sequential, parallel, and nested structures. Our comprehensive evaluation of mainstream LLMs covers tests on rational reasoning, robustness, Theory-of-Mind (ToM), and reasoning in complex forms. Results reveal flaws in accuracy, consistency, and varying mastery of ToM. Additionally, o1-mini, OpenAI's latest reasoning model, achieved accuracy rates of 66.6%, 60.0%, and 70.0% on sequential, parallel, and nested games, highlighting TMGBench's challenges.
Mitigating Gender Bias in Code Large Language Models via Model Editing
Oct 10, 2024In recent years, with the maturation of large language model (LLM) technology and the emergence of high-quality programming code datasets, researchers have become increasingly confident in addressing the challenges of program synthesis automatically. However, since most of the training samples for LLMs are unscreened, it is inevitable that LLMs' performance may not align with real-world scenarios, leading to the presence of social bias. To evaluate and quantify the gender bias in code LLMs, we propose a dataset named CodeGenBias (Gender Bias in the Code Generation) and an evaluation metric called FB-Score (Factual Bias Score) based on the actual gender distribution of correlative professions. With the help of CodeGenBias and FB-Score, we evaluate and analyze the gender bias in eight mainstream Code LLMs. Previous work has demonstrated that model editing methods that perform well in knowledge editing have the potential to mitigate social bias in LLMs. Therefore, we develop a model editing approach named MG-Editing (Multi-Granularity model Editing), which includes the locating and editing phases. Our model editing method MG-Editing can be applied at five different levels of model parameter granularity: full parameters level, layer level, module level, row level, and neuron level. Extensive experiments not only demonstrate that our MG-Editing can effectively mitigate the gender bias in code LLMs while maintaining their general code generation capabilities, but also showcase its excellent generalization. At the same time, the experimental results show that, considering both the gender bias of the model and its general code generation capability, MG-Editing is most effective when applied at the row and neuron levels of granularity.