 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Demonstration Annotation for In-Context Learning via Language Model-Based Determinantal Point Process
Aug 04, 2024



In-context learning (ICL) is a few-shot learning paradigm that involves learning mappings through input-output pairs and appropriately applying them to new instances. Despite the remarkable ICL capabilities demonstrated by Large Language Models (LLMs), existing works are highly dependent on large-scale labeled support sets, not always feasible in practical scenarios. To refine this approach, we focus primarily on an innovative selective annotation mechanism, which precedes the standard demonstration retrieval. We introduce the Language Model-based Determinant Point Process (LM-DPP) that simultaneously considers the uncertainty and diversity of unlabeled instances for optimal selection. Consequently, this yields a subset for annotation that strikes a trade-off between the two factors. We apply LM-DPP to various language models, including GPT-J, LlaMA, and GPT-3. Experimental results on 9 NLU and 2 Generation datasets demonstrate that LM-DPP can effectively select canonical examples. Further analysis reveals that LLMs benefit most significantly from subsets that are both low uncertainty and high diversity.
RaFe: Ranking Feedback Improves Query Rewriting for RAG
May 23, 2024



As Large Language Models (LLMs) and Retrieval Augmentation Generation (RAG) techniques have evolved, query rewriting has been widely incorporated into the RAG system for downstream tasks like open-domain QA. Many works have attempted to utilize small models with reinforcement learning rather than costly LLMs to improve query rewriting. However, current methods require annotations (e.g., labeled relevant documents or downstream answers) or predesigned rewards for feedback, which lack generalization, and fail to utilize signals tailored for query rewriting. In this paper, we propose ours, a framework for training query rewriting models free of annotations. By leveraging a publicly available reranker, ours~provides feedback aligned well with the rewriting objectives. Experimental results demonstrate that ours~can obtain better performance than baselines.
Editing Conceptual Knowledge for Large Language Models
Mar 10, 2024Recently, there has been a growing interest in knowledge editing for Large Language Models (LLMs). Current approaches and evaluations merely explore the instance-level editing, while whether LLMs possess the capability to modify concepts remains unclear. This paper pioneers the investigation of editing conceptual knowledge for LLMs, by constructing a novel benchmark dataset ConceptEdit and establishing a suite of new metrics for evaluation. The experimental results reveal that, although existing editing methods can efficiently modify concept-level definition to some extent, they also have the potential to distort the related instantial knowledge in LLMs, leading to poor performance. We anticipate this can inspire further progress in better understanding LLMs. Our project homepage is available at https://zjunlp.github.io/project/ConceptEdit.
A Comprehensive Study of Knowledge Editing for Large Language Models
Jan 09, 2024



Large Language Models (LLMs) have shown extraordinary capabilities in understanding and generating text that closely mirrors human communication. However, a primary limitation lies in the significant computational demands during training, arising from their extensive parameterization. This challenge is further intensified by the dynamic nature of the world, necessitating frequent updates to LLMs to correct outdated information or integrate new knowledge, thereby ensuring their continued relevance. Note that many applications demand continual model adjustments post-training to address deficiencies or undesirable behaviors. There is an increasing interest in efficient, lightweight methods for on-the-fly model modifications. To this end, recent years have seen a burgeoning in the techniques of knowledge editing for LLMs, which aim to efficiently modify LLMs' behaviors within specific domains while preserving overall performance across various inputs. In this paper, we first define the knowledge editing problem and then provide a comprehensive review of cutting-edge approaches. Drawing inspiration from educational and cognitive research theories, we propose a unified categorization criterion that classifies knowledge editing methods into three groups: resorting to external knowledge, merging knowledge into the model, and editing intrinsic knowledge. Furthermore, we introduce a new benchmark, KnowEdit, for a comprehensive empirical evaluation of representative knowledge editing approaches. Additionally, we provide an in-depth analysis of knowledge location, which can give a deeper understanding of the knowledge structures inherent within LLMs. Finally, we discuss several potential applications of knowledge editing, outlining its broad and impactful implications.
Editing Personality for LLMs
Oct 03, 2023This paper introduces an innovative task focused on editing the personality traits of Large Language Models (LLMs). This task seeks to adjust the models' responses to opinion-related questions on specified topics since an individual's personality often manifests in the form of their expressed opinions, thereby showcasing different personality traits. Specifically, we construct a new benchmark dataset PersonalityEdit to address this task. Drawing on the theory in Social Psychology, we isolate three representative traits, namely Neuroticism, Extraversion, and Agreeableness, as the foundation for our benchmark. We then gather data using GPT-4, generating responses that not only align with a specified topic but also embody the targeted personality trait. We conduct comprehensive experiments involving various baselines and discuss the representation of personality behavior in LLMs. Our intriguing findings uncover potential challenges of the proposed task, illustrating several remaining issues. We anticipate that our work can provide the NLP community with insights. Code and datasets will be released at https://github.com/zjunlp/EasyEdit.
SPEECH: Structured Prediction with Energy-Based Event-Centric Hyperspheres
May 26, 2023Event-centric structured prediction involves predicting structured outputs of events. In most NLP cases, event structures are complex with manifold dependency, and it is challenging to effectively represent these complicated structured events. To address these issues, we propose Structured Prediction with Energy-based Event-Centric Hyperspheres (SPEECH). SPEECH models complex dependency among event structured components with energy-based modeling, and represents event classes with simple but effective hyperspheres. Experiments on two unified-annotated event datasets indicate that SPEECH is predominant in event detection and event-relation extraction tasks.
Knowledge Rumination for Pre-trained Language Models
May 15, 2023



Previous studies have revealed that vanilla pre-trained language models (PLMs) lack the capacity to handle knowledge-intensive NLP tasks alone; thus, several works have attempted to integrate external knowledge into PLMs. However, despite the promising outcome, we empirically observe that PLMs may have already encoded rich knowledge in their pre-trained parameters but fails to fully utilize them when applying to knowledge-intensive tasks. In this paper, we propose a new paradigm dubbed Knowledge Rumination to help the pre-trained language model utilize those related latent knowledge without retrieving them from the external corpus. By simply adding a prompt like ``As far as I know'' to the PLMs, we try to review related latent knowledge and inject them back to the model for knowledge consolidation. We apply the proposed knowledge rumination to various language models, including RoBERTa, DeBERTa, GPT-3 and OPT. Experimental results on six commonsense reasoning tasks and GLUE benchmarks demonstrate the effectiveness of our proposed approach, which further proves that the knowledge stored in PLMs can be better exploited to enhance the downstream performance. Code will be available in https://github.com/zjunlp/knowledge-rumination.
Schema-aware Reference as Prompt Improves Data-Efficient Relational Triple and Event Extraction
Oct 19, 2022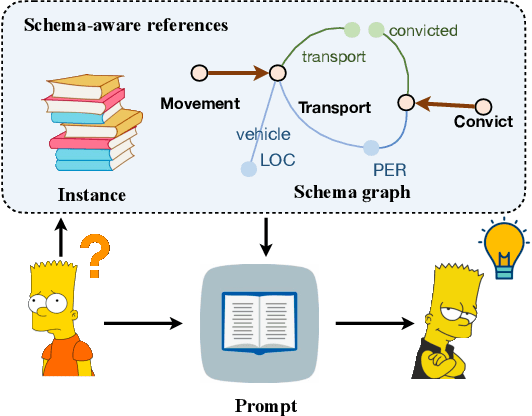
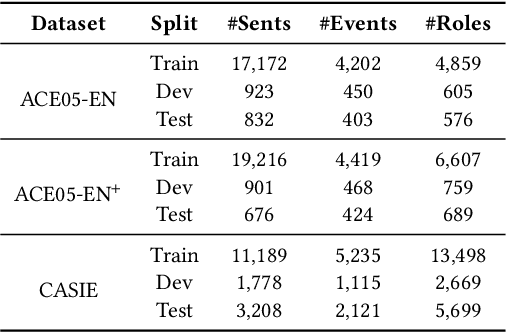
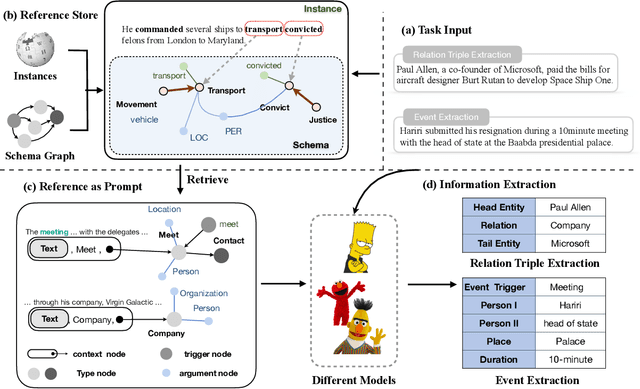
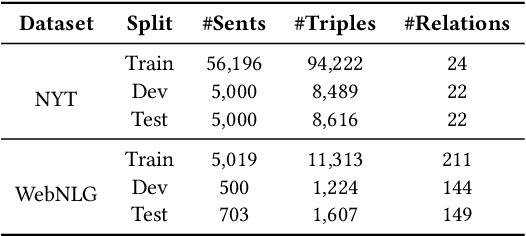
Information Extraction, which aims to extract structural relational triple or event from unstructured texts, often suffers from data scarcity issues. With the development of pre-trained language models, many prompt-based approaches to data-efficient information extraction have been proposed and achieved impressive performance. However, existing prompt learning methods for information extraction are still susceptible to several potential limitations: (i) semantic gap between natural language and output structure knowledge with pre-defined schema; (ii) representation learning with locally individual instances limits the performance given the insufficient features. In this paper, we propose a novel approach of schema-aware Reference As Prompt (RAP), which dynamically leverage schema and knowledge inherited from global (few-shot) training data for each sample. Specifically, we propose a schema-aware reference store, which unifies symbolic schema and relevant textual instances. Then, we employ a dynamic reference integration module to retrieve pertinent knowledge from the datastore as prompts during training and inference. Experimental results demonstrate that RAP can be plugged into various existing models and outperforms baselines in low-resource settings on five datasets of relational triple extraction and event extraction. In addition, we provide comprehensive empirical ablations and case analysis regarding different types and scales of knowledge in order to better understand the mechanisms of RAP. Code is available in https://github.com/zjunlp/RAP.