 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasyTransfer -- A Simple and Scalable Deep Transfer Learning Platform for NLP Applications
Nov 23, 2020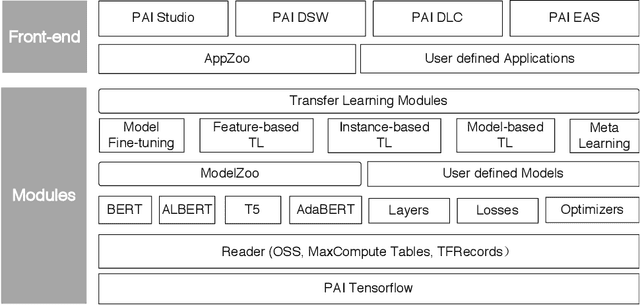

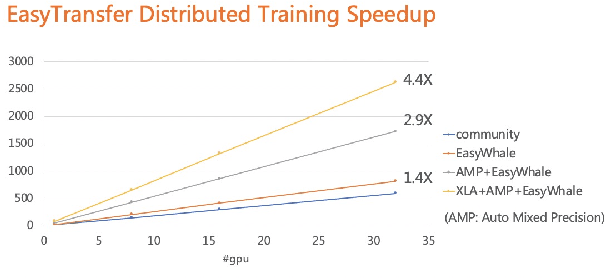
The literature has witnessed the success of applying deep Transfer Learning (TL) algorithms to many NLP applications, yet it is not easy to build a simple and scalable TL toolkit for this purpose. To bridge this gap, the EasyTransfer platform is designed to make it easy to develop deep TL algorithms for NLP applications. It is built with rich API abstractions, a scalable architecture and comprehensive deep TL algorithms, to make the development of NLP applications easier. To be specific, the build-in data and model parallelism strategy shows to be 4x faster than the default distribution strategy of Tensorflow. EasyTransfer supports the mainstream pre-trained ModelZoo, including Pre-trained Language Models (PLMs) and multi-modality models. It also integrates various SOTA models for mainstream NLP applications in AppZoo, and supports mainstream TL algorithms as well. The toolkit is convenient for users to quickly start model training, evaluation, offline prediction, and online deployment. This system is currently deployed at Alibaba to support a variety of business scenarios, including item recommendation, personalized search, and conversational question answering. Extensive experiments on real-world datasets show that EasyTransfer is suitable for online production with cutting-edge performance. The source code of EasyTransfer is released at Github (https://github.com/alibaba/EasyTransfer).
One-shot Text Field Labeling using Attention and Belief Propagation for Structure Information Extraction
Sep 09, 2020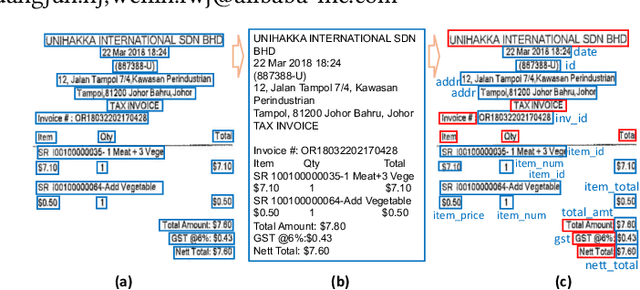

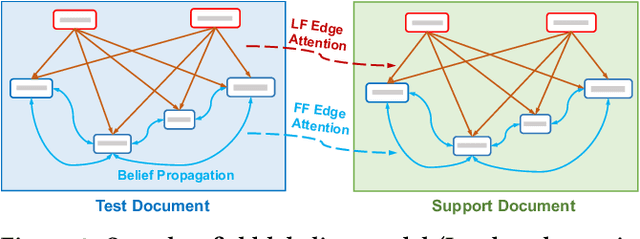
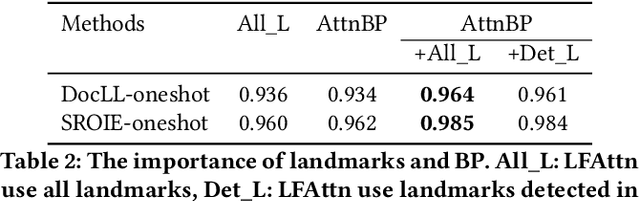
Structured information extraction from document images usually consists of three steps: text detection, text recognition, and text field labeling. While text detection and text recognition have been heavily studied and improved a lot in literature, text field labeling is less explored and still faces many challenges. Existing learning based methods for text labeling task usually require a large amount of labeled examples to train a specific model for each type of document. However, collecting large amounts of document images and labeling them is difficult and sometimes impossible due to privacy issues. Deploying separate models for each type of document also consumes a lot of resources. Facing these challenges, we explore one-shot learning for the text field labeling task. Existing one-shot learning methods for the task are mostly rule-based and have difficulty in labeling fields in crowded regions with few landmarks and fields consisting of multiple separate text regions. To alleviate these problems, we proposed a novel deep end-to-end trainable approach for one-shot text field labeling, which makes use of attention mechanism to transfer the layout information between document images. We further applied conditional random field on the transferred layout information for the refinement of field labeling. We collected and annotated a real-world one-shot field labeling dataset with a large variety of document types and conducted extensive experiments to examine the effectiveness of the proposed model. To stimulate research in this direction, the collected dataset and the one-shot model will be released1.
* 9 pages
A Comprehensive Analysis of Information Leakage in Deep Transfer Learning
Sep 04, 2020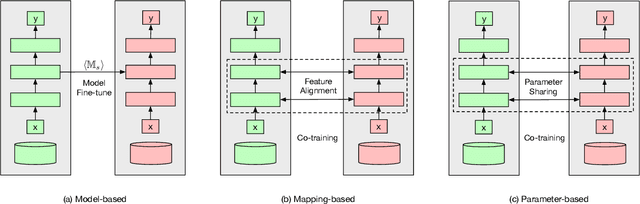

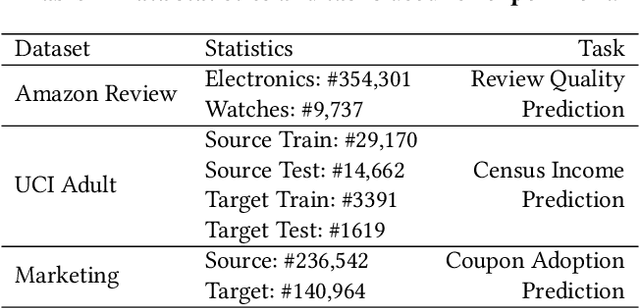
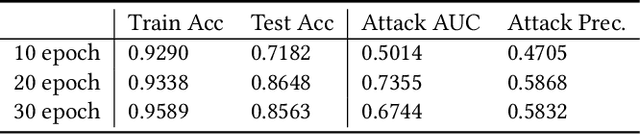
Transfer learning is widely used for transferring knowledge from a source domain to the target domain where the labeled data is scarce. Recently, deep transfer learning has achieved remarkable progress in various applications. However, the source and target datasets usually belong to two different organizations in many real-world scenarios, potential privacy issues in deep transfer learning are posed. In this study, to thoroughly analyze the potential privacy leakage in deep transfer learning, we first divide previous methods into three categories. Based on that, we demonstrate specific threats that lead to unintentional privacy leakage in each category. Additionally, we also provide some solutions to prevent these threats. To the best of our knowledge, our study is the first to provide a thorough analysis of the information leakage issues in deep transfer learning methods and provide potential solutions to the issue. Extensive experiments on two public datasets and an industry dataset are conducted to show the privacy leakage under different deep transfer learning settings and defense solution effectiveness.
Knowledge-Empowered Representation Learning for Chinese Medical Reading Comprehension: Task, Model and Resources
Aug 24, 2020

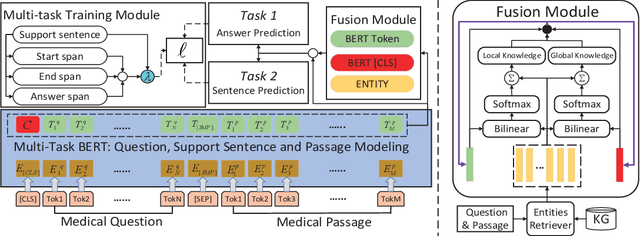
Machine Reading Comprehension (MRC) aims to extract answers to questions given a passage. It has been widely studied recently, especially in open domains. However, few efforts have been made on closed-domain MRC, mainly due to the lack of large-scale training data. In this paper, we introduce a multi-target MRC task for the medical domain, whose goal is to predict answers to medical questions and the corresponding support sentences from medical information sources simultaneously, in order to ensure the high reliability of medical knowledge serving. A high-quality dataset is manually constructed for the purpose, named Multi-task Chinese Medical MRC dataset (CMedMRC), with detailed analysis conducted. We further propose the Chinese medical BERT model for the task (CMedBERT), which fuses medical knowledge into pre-trained language models by the dynamic fusion mechanism of heterogeneous features and the multi-task learning strategy. Experiments show that CMedBERT consistently outperforms strong baselines by fusing context-aware and knowledge-aware token representations.
FashionBERT: Text and Image Matching with Adaptive Loss for Cross-modal Retrieval
May 29, 2020
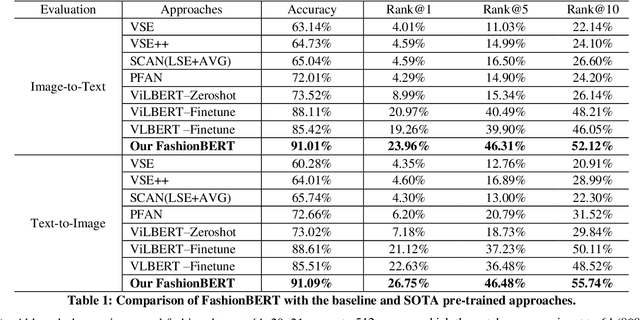
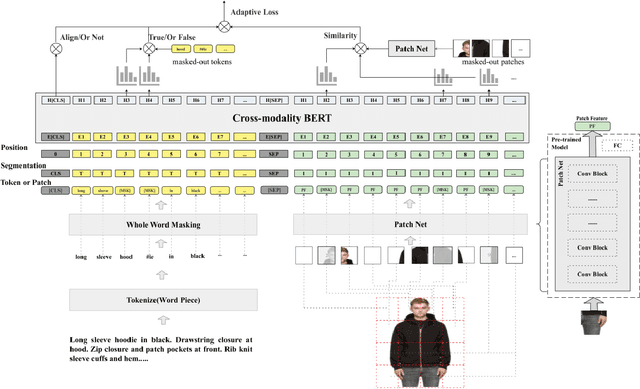
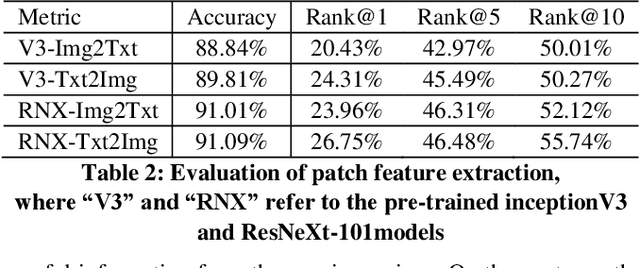
In this paper, we address the text and image matching in cross-modal retrieval of the fashion industry. Different from the matching in the general domain, the fashion matching is required to pay much more attention to the fine-grained information in the fashion images and texts. Pioneer approaches detect the region of interests (i.e., RoIs) from images and use the RoI embeddings as image representations. In general, RoIs tend to represent the "object-level" information in the fashion images, while fashion texts are prone to describe more detailed information, e.g. styles, attributes. RoIs are thus not fine-grained enough for fashion text and image matching. To this end, we propose FashionBERT, which leverages patches as image features. With the pre-trained BERT model as the backbone network, FashionBERT learns high level representations of texts and images. Meanwhile, we propose an adaptive loss to trade off multitask learning in the FashionBERT modeling. Two tasks (i.e., text and image matching and cross-modal retrieval) are incorporated to evaluate FashionBERT. On the public dataset, experiments demonstrate FashionBERT achieves significant improvements in performances than the baseline and state-of-the-art approaches. In practice, FashionBERT is applied in a concrete cross-modal retrieval application. We provide the detailed matching performance and inference efficiency analysis.
Open-Retrieval Conversational Question Answering
May 22, 2020
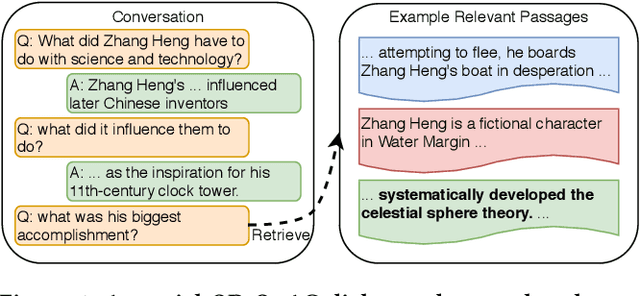
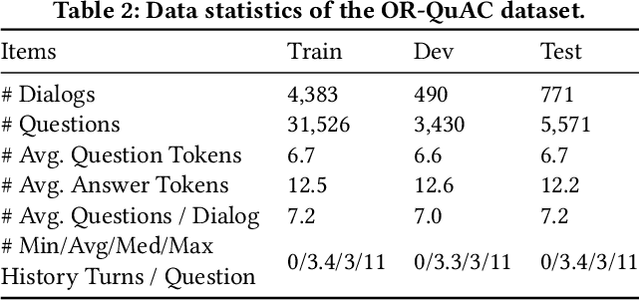
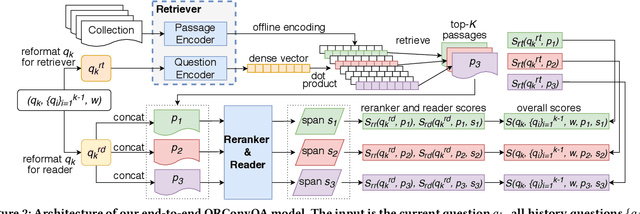
Conversational search is one of the ultimate goals of information retrieval. Recent research approaches conversational search by simplified settings of response ranking and conversational question answering, where an answer is either selected from a given candidate set or extracted from a given passage. These simplifications neglect the fundamental role of retrieval in conversational search. To address this limitation, we introduce an open-retrieval conversational question answering (ORConvQA) setting, where we learn to retrieve evidence from a large collection before extracting answers, as a further step towards building functional conversational search systems. We create a dataset, OR-QuAC, to facilitate research on ORConvQA. We build an end-to-end system for ORConvQA, featuring a retriever, a reranker, and a reader that are all based on Transformers. Our extensive experiments on OR-QuAC demonstrate that a learnable retriever is crucial for ORConvQA. We further show that our system can make a substantial improvement when we enable history modeling in all system components. Moreover, we show that the reranker component contributes to the model performance by providing a regularization effect. Finally, further in-depth analyses are performed to provide new insights into ORConvQA.
End-to-end Semantics-based Summary Quality Assessment for Single-document Summarization
May 13, 2020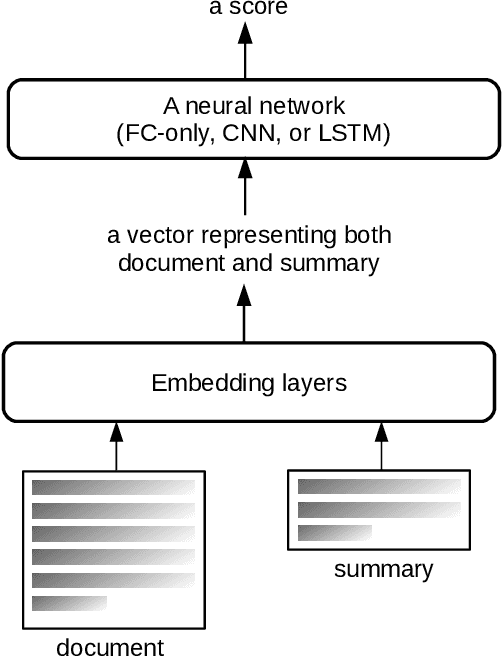
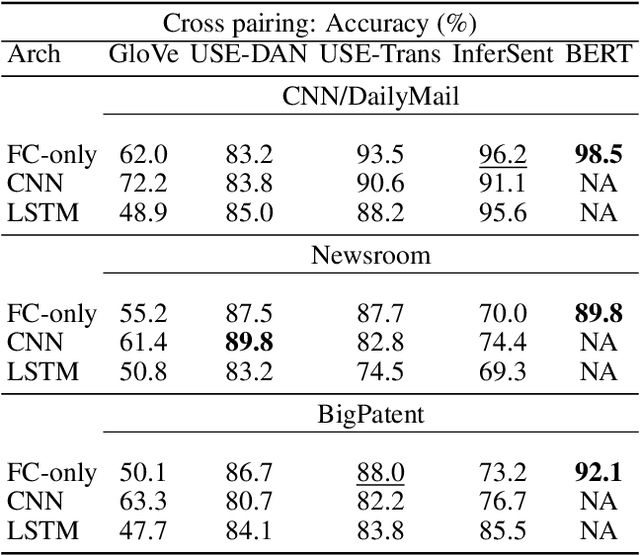

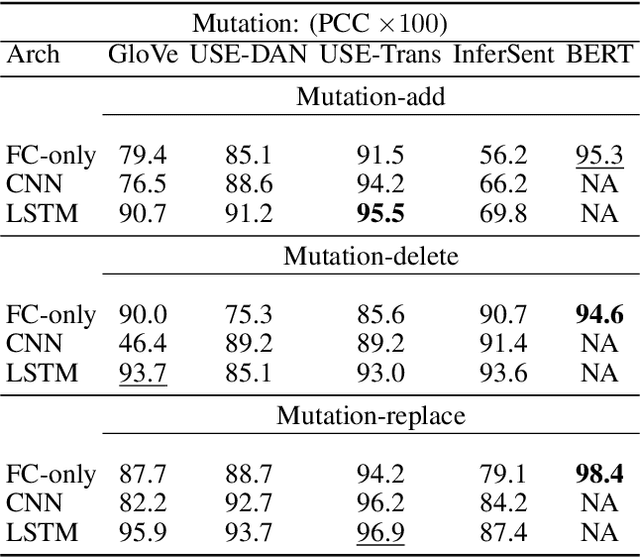
ROUGE is the de facto criterion for summarization research. However, its two major drawbacks limit the research and application of automated summarization systems. First, ROUGE favors lexical similarity instead of semantic similarity, making it especially unfit for abstractive summarization. Second, ROUGE cannot function without a reference summary, which is expensive or impossible to obtain in many cases. Therefore, we introduce a new end-to-end metric system for summary quality assessment by leveraging the semantic similarities of words and/or sentences in deep learning. Models trained in our framework can evaluate a summary directly against the input document, without the need of a reference summary. The proposed approach exhibits very promising results on gold-standard datasets and suggests its great potential to future summarization research. The scores from our models have correlation coefficients up to 0.54 with human evaluations on machine generated summaries in TAC2010. Its performance is also very close to ROUGE metrics'.
Meta Fine-Tuning Neural Language Models for Multi-Domain Text Mining
Mar 29, 2020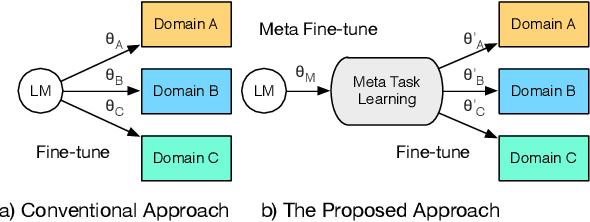
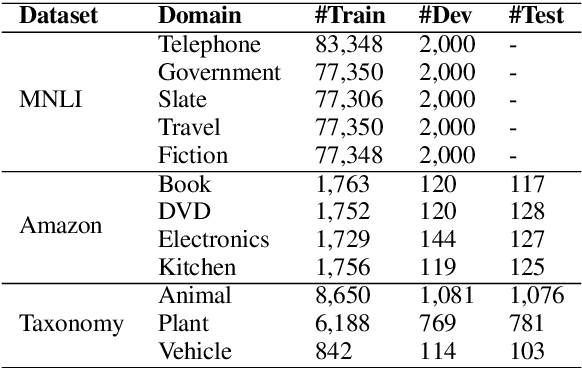
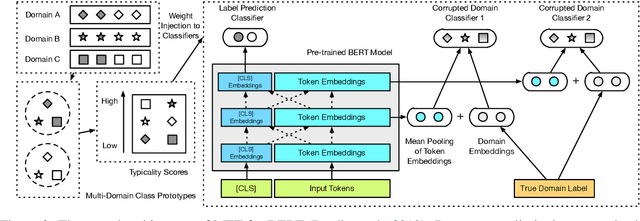
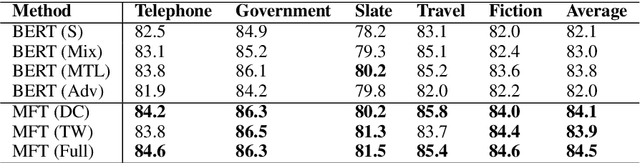
Pre-trained neural language models bring significant improvement for various NLP tasks, by fine-tuning the models on task-specific training sets. During fine-tuning, the parameters are initialized from pre-trained models directly, which ignores how the learning process of similar NLP tasks in different domains is correlated and mutually reinforced. In this paper, we propose an effective learning procedure named Meta Fine-Tuning (MFT), served as a meta-learner to solve a group of similar NLP tasks for neural language models. Instead of simply multi-task training over all the datasets, MFT only learns from typical instances of various domains to acquire highly transferable knowledge. It further encourages the language model to encode domain-invariant representations by optimizing a series of novel domain corruption loss functions. After MFT, the model can be fine-tuned for each domain with better parameter initializations and higher generalization ability. We implement MFT upon BERT to solve several multi-domain text mining tasks. Experimental results confirm the effectiveness of MFT and its usefulness for few-shot learning.
KEML: A Knowledge-Enriched Meta-Learning Framework for Lexical Relation Classification
Feb 25, 2020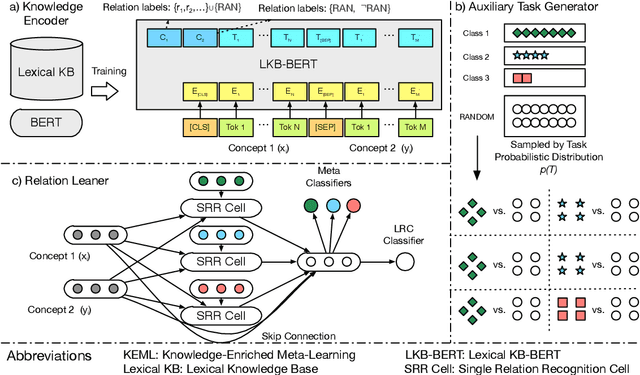
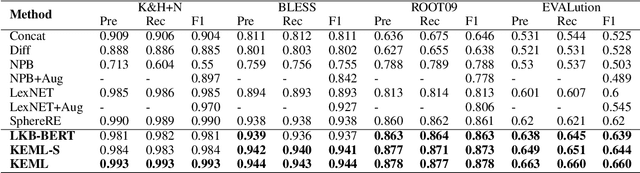
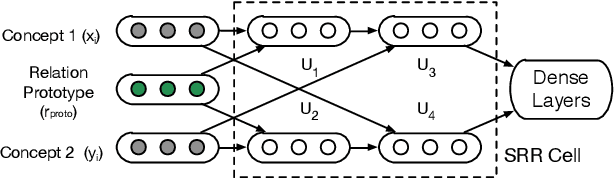
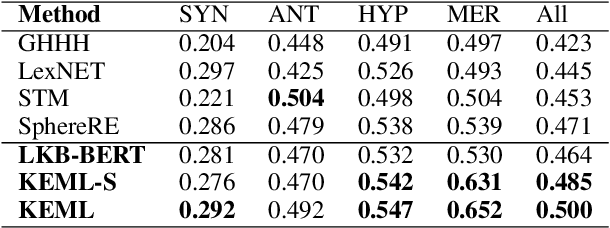
Lexical relations describe how concepts are semantically related, in the form of relation triples. The accurate prediction of lexical relations between concepts is challenging, due to the sparsity of patterns indicating the existence of such relations. We propose the Knowledge-Enriched Meta-Learning (KEML) framework to address the task of lexical relation classification. In KEML, the LKB-BERT (Lexical Knowledge Base-BERT) model is presented to learn concept representations from massive text corpora, with rich lexical knowledge injected by distant supervision. A probabilistic distribution of auxiliary tasks is defined to increase the model's ability to recognize different types of lexical relations. We further combine a meta-learning process over the auxiliary task distribution and supervised learning to train the neural lexical relation classifier. Experiments over multiple datasets show that KEML outperforms state-of-the-art methods.
IART: Intent-aware Response Ranking with Transformers in Information-seeking Conversation Systems
Feb 03, 2020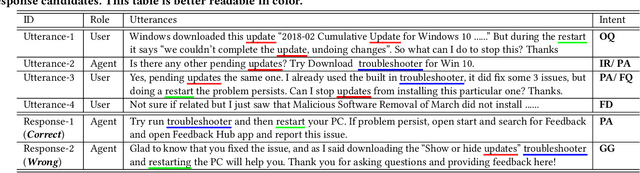
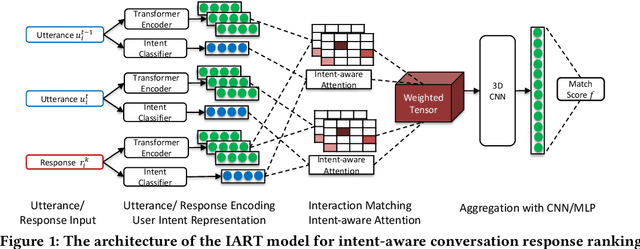
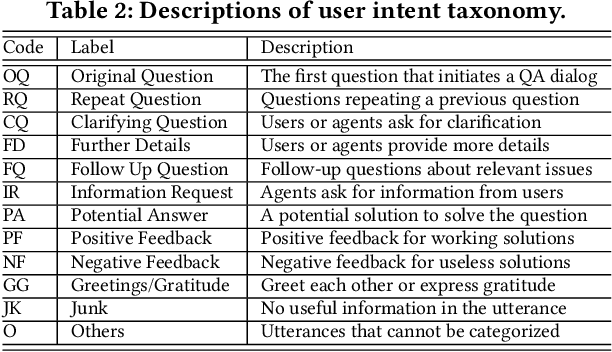
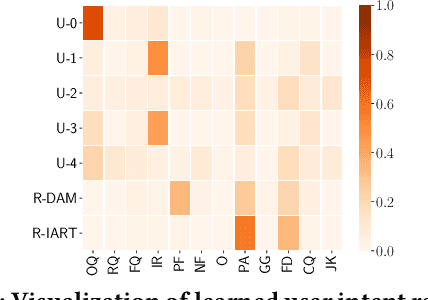
Personal assistant systems, such as Apple Siri, Google Assistant, Amazon Alexa, and Microsoft Cortana, are becoming ever more widely used. Understanding user intent such as clarification questions, potential answers and user feedback in information-seeking conversations is critical for retrieving good responses. In this paper, we analyze user intent patterns in information-seeking conversations and propose an intent-aware neural response ranking model "IART", which refers to "Intent-Aware Ranking with Transformers". IART is built on top of the integration of user intent modeling and language representation learning with the Transformer architecture, which relies entirely on a self-attention mechanism instead of recurrent nets. It incorporates intent-aware utterance attention to derive an importance weighting scheme of utterances in conversation context with the aim of better conversation history understanding. We conduct extensive experiments with three information-seeking conversation data sets including both standard benchmarks and commercial data. Our proposed model outperforms all baseline methods with respect to a variety of metrics. We also perform case studies and analysis of learned user intent and its impact on response ranking in information-seeking conversations to provide interpretation of results.