 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Semantics-based Summary Quality Assessment for Single-document Summarization
Paper and Code
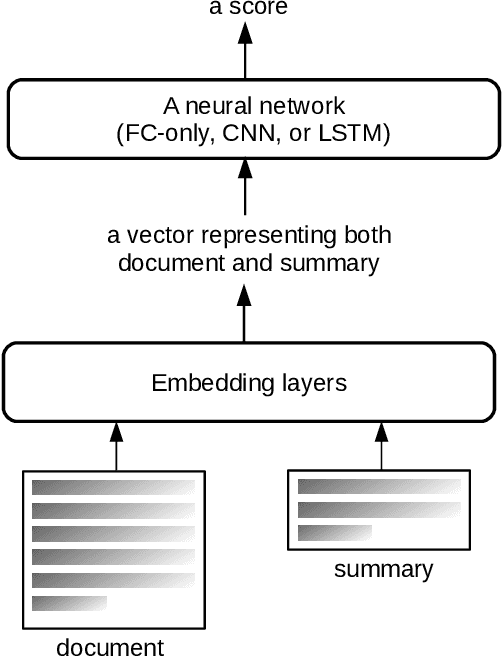
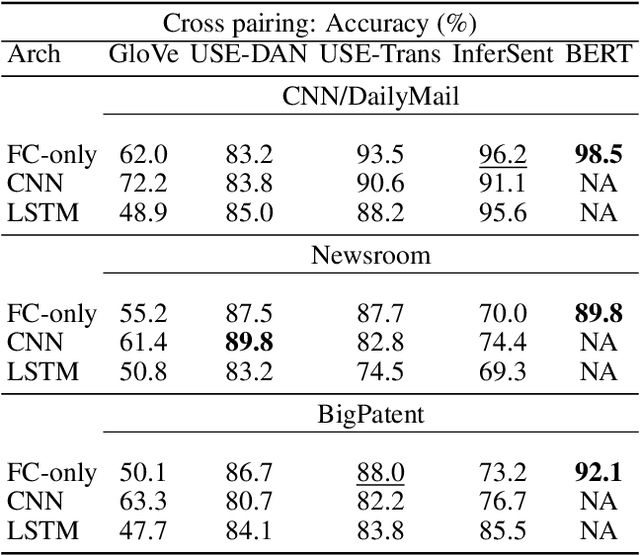

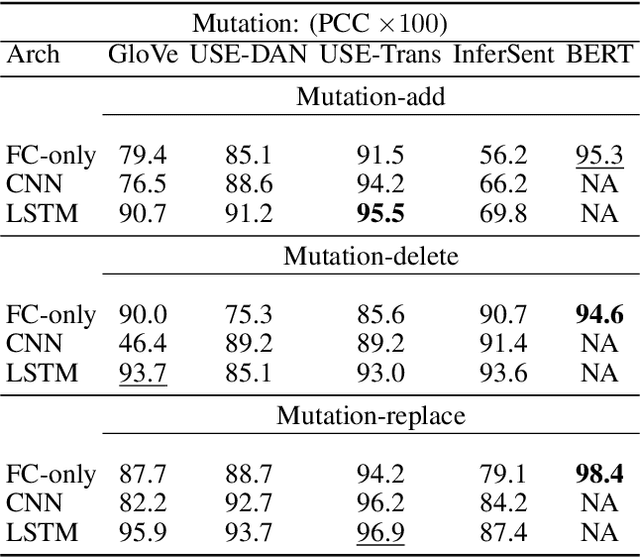
ROUGE is the de facto criterion for summarization research. However, its two major drawbacks limit the research and application of automated summarization systems. First, ROUGE favors lexical similarity instead of semantic similarity, making it especially unfit for abstractive summarization. Second, ROUGE cannot function without a reference summary, which is expensive or impossible to obtain in many cases. Therefore, we introduce a new end-to-end metric system for summary quality assessment by leveraging the semantic similarities of words and/or sentences in deep learning. Models trained in our framework can evaluate a summary directly against the input document, without the need of a reference summary. The proposed approach exhibits very promising results on gold-standard datasets and suggests its great potential to future summarization research. The scores from our models have correlation coefficients up to 0.54 with human evaluations on machine generated summaries in TAC2010. Its performance is also very close to ROUGE metrics'.