 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Personality from Eye-Tracking: The Role of Gaze and Its Absence in Interactive Search Environments
Jan 13, 2026Personality traits influence how individuals engage, behave, and make decisions during the information-seeking process. However, few studies have linked personality to observable search behaviors. This study aims to characterize personality traits through a multimodal time-series model that integrates eye-tracking data and gaze missingness-periods when the user's gaze is not captured. This approach is based on the idea that people often look away when they think, signaling disengagement or reflection. We conducted a user study with 25 participants, who used an interactive application on an iPad, allowing them to engage with digital artifacts from a museum. We rely on raw gaze data from an eye tracker, minimizing preprocessing so that behavioral patterns can be preserved without substantial data cleaning. From this perspective, we trained models to predict personality traits using gaze signals. Our results from a five-fold cross-validation study demonstrate strong predictive performance across all five dimensions: Neuroticism (Macro F1 = 77.69%), Conscientiousness (74.52%), Openness (77.52%), Agreeableness (73.09%), and Extraversion (76.69%). The ablation study examines whether the absence of gaze information affects the model performance, demonstrating that incorporating missingness improves multimodal time-series modeling. The full model, which integrates both time-series signals and missingness information, achieves 10-15% higher accuracy and macro F1 scores across all Big Five traits compared to the model without time-series signals and missingness. These findings provide evidence that personality can be inferred from search-related gaze behavior and demonstrate the value of incorporating missing gaze data into time-series multimodal modeling.
Characterising Topic Familiarity and Query Specificity Using Eye-Tracking Data
May 06, 2025



Eye-tracking data has been shown to correlate with a user's knowledge level and query formulation behaviour. While previous work has focused primarily on eye gaze fixations for attention analysis, often requiring additional contextual information, our study investigates the memory-related cognitive dimension by relying solely on pupil dilation and gaze velocity to infer users' topic familiarity and query specificity without needing any contextual information. Using eye-tracking data collected via a lab user study (N=18), we achieved a Macro F1 score of 71.25% for predicting topic familiarity with a Gradient Boosting classifier, and a Macro F1 score of 60.54% with a k-nearest neighbours (KNN) classifier for query specificity. Furthermore, we developed a novel annotation guideline -- specifically tailored for question answering -- to manually classify queries as Specific or Non-specific. This study demonstrates the feasibility of eye-tracking to better understand topic familiarity and query specificity in search.
Multi-stage Large Language Model Pipelines Can Outperform GPT-4o in Relevance Assessment
Jan 24, 2025



The effectiveness of search systems is evaluated using relevance labels that indicate the usefulness of documents for specific queries and users. While obtaining these relevance labels from real users is ideal, scaling such data collection is challenging. Consequently, third-party annotators are employed, but their inconsistent accuracy demands costly auditing, training, and monitoring. We propose an LLM-based modular classification pipeline that divides the relevance assessment task into multiple stages, each utilising different prompts and models of varying sizes and capabilities. Applied to TREC Deep Learning (TREC-DL), one of our approaches showed an 18.4% Krippendorff's $\alpha$ accuracy increase over OpenAI's GPT-4o mini while maintaining a cost of about 0.2 USD per million input tokens, offering a more efficient and scalable solution for relevance assessment. This approach beats the baseline performance of GPT-4o (5 USD). With a pipeline approach, even the accuracy of the GPT-4o flagship model, measured in $\alpha$, could be improved by 9.7%.
Can Stories Help LLMs Reason? Curating Information Space Through Narrative
Oct 25, 2024



Narratives are widely recognized as a powerful tool for structuring information and facilitating comprehension of complex ideas in various domains such as science communication. This paper investigates whether incorporating narrative elements can assist Large Language Models (LLMs) in solving complex problems more effectively. We propose a novel approach, Story of Thought (SoT), integrating narrative structures into prompting techniques for problem-solving. This approach involves constructing narratives around problem statements and creating a framework to identify and organize relevant information. Our experiments show that using various LLMs with SoT consistently surpasses using them with other techniques on physics, chemistry, math, and biology questions in both the GPQA and JEEBench datasets. The narrative-based information curation process in SoT enhances problem comprehension by contextualizing critical in-domain information and highlighting causal relationships within the problem space.
Towards Investigating Biases in Spoken Conversational Search
Sep 02, 2024


Voice-based systems like Amazon Alexa, Google Assistant, and Apple Siri, along with the growing popularity of OpenAI's ChatGPT and Microsoft's Copilot, serve diverse populations, including visually impaired and low-literacy communities. This reflects a shift in user expectations from traditional search to more interactive question-answering models. However, presenting information effectively in voice-only channels remains challenging due to their linear nature. This limitation can impact the presentation of complex queries involving controversial topics with multiple perspectives. Failing to present diverse viewpoints may perpetuate or introduce biases and affect user attitudes. Balancing information load and addressing biases is crucial in designing a fair and effective voice-based system. To address this, we (i) review how biases and user attitude changes have been studied in screen-based web search, (ii) address challenges in studying these changes in voice-based settings like SCS, (iii) outline research questions, and (iv) propose an experimental setup with variables, data, and instruments to explore biases in a voice-based setting like Spoken Conversational Search.
Towards Detecting and Mitigating Cognitive Bias in Spoken Conversational Search
May 21, 2024Instruments such as eye-tracking devices have contributed to understanding how users interact with screen-based search engines. However, user-system interactions in audio-only channels -- as is the case for Spoken Conversational Search (SCS) -- are harder to characterize, given the lack of instruments to effectively and precisely capture interactions. Furthermore, in this era of information overload, cognitive bias can significantly impact how we seek and consume information -- especially in the context of controversial topics or multiple viewpoints. This paper draws upon insights from multiple disciplines (including information seeking, psychology, cognitive science, and wearable sensors) to provoke novel conversations in the community. To this end, we discuss future opportunities and propose a framework including multimodal instruments and methods for experimental designs and settings. We demonstrate preliminary results as an example. We also outline the challenges and offer suggestions for adopting this multimodal approach, including ethical considerations, to assist future researchers and practitioners in exploring cognitive biases in SCS.
Online and Offline Evaluation in Search Clarification
Mar 14, 2024



The effectiveness of clarification question models in engaging users within search systems is currently constrained, casting doubt on their overall usefulness. To improve the performance of these models, it is crucial to employ assessment approaches that encompass both real-time feedback from users (online evaluation) and the characteristics of clarification questions evaluated through human assessment (offline evaluation). However, the relationship between online and offline evaluations has been debated in information retrieval. This study aims to investigate how this discordance holds in search clarification. We use user engagement as ground truth and employ several offline labels to investigate to what extent the offline ranked lists of clarification resemble the ideal ranked lists based on online user engagement.
Walert: Putting Conversational Search Knowledge into Action by Building and Evaluating a Large Language Model-Powered Chatbot
Jan 14, 2024


Creating and deploying customized applications is crucial for operational success and enriching user experiences in the rapidly evolving modern business world. A prominent facet of modern user experiences is the integration of chatbots or voice assistants. The rapid evolution of Large Language Models (LLMs) has provided a powerful tool to build conversational applications. We present Walert, a customized LLM-based conversational agent able to answer frequently asked questions about computer science degrees and programs at RMIT University. Our demo aims to showcase how conversational information-seeking researchers can effectively communicate the benefits of using best practices to stakeholders interested in developing and deploying LLM-based chatbots. These practices are well-known in our community but often overlooked by practitioners who may not have access to this knowledge. The methodology and resources used in this demo serve as a bridge to facilitate knowledge transfer from experts, address industry professionals' practical needs, and foster a collaborative environment. The data and code of the demo are available at https://github.com/rmit-ir/walert.
MIMICS-Duo: Offline & Online Evaluation of Search Clarification
Jun 09, 2022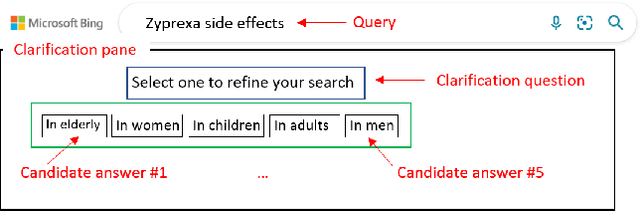

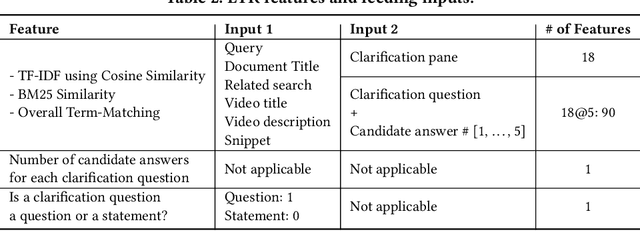

Asking clarification questions is an active area of research; however, resources for training and evaluating search clarification methods are not sufficient. To address this issue, we describe MIMICS-Duo, a new freely available dataset of 306 search queries with multiple clarifications (a total of 1,034 query-clarification pairs). MIMICS-Duo contains fine-grained annotations on clarification questions and their candidate answers and enhances the existing MIMICS datasets by enabling multi-dimensional evaluation of search clarification methods, including online and offline evaluation. We conduct extensive analysis to demonstrate the relationship between offline and online search clarification datasets and outline several research directions enabled by MIMICS-Duo. We believe that this resource will help researchers better understand clarification in search.
Conversational Information Seeking
Jan 21, 2022Conversational information seeking (CIS) is concerned with a sequence of interactions between one or more users and an information system. Interactions in CIS are primarily based on natural language dialogue, while they may include other types of interactions, such as click, touch, and body gestures. This monograph provides a thorough overview of CIS definitions, applications, interactions, interfaces, design, implementation, and evaluation. This monograph views CIS applications as including conversational search, conversational question answering, and conversational recommendation. Our aim is to provide an overview of past research related to CIS, introduce the current state-of-the-art in CIS, highlight the challenges still being faced in the community. and suggest future directions.